Solr学习之四-Solr配置说明之二
上一篇的配置说明主要是说明solrconfig.xml配置中的查询部分配置,在solr的功能中另外一个重要的功能是建索引,这是提供快速查询的核心。
按照Solr学习之一所述关于搜索引擎的原理中说明了建立索引,其实就需要经过分词组件处理,语言组件处理最后建立成一个倒排索引表,
通过这个索引表,来进行查询,本篇就是说明solr如何建立索引的也即是solrconfig.xml中关于更新索引的部分,另外由于建立索引需要涉及到
schemal.xml相关内容定义,这里面也一起说明。
一、设计schema
在solr的基本概念中,有个文档的概念。solr在建立索引的时候,是按照文档的方式添加到索引中的。那么我们如何设计一个文档那。
- 文档粒度确认
举个简单的例子,假设你对图书馆的图书建立索引,你是按照每个图书的信息来建立索引,还是按照所有图书的所有章节来建立索引那,
这其实要看你的应用程序要求。如果你的客户要求查询的时候,出来是一条条书目的信息,那么就比较适合按照一本本图书这个级别来建立
文档,那可能涉及到的文档字段(field) 有书名、作者、出版社、价格等基本信息。
那在搜索的时候,如果用户想查询的是哪些书包含某些内容的信息是查不到的。 如果 想查到,可能要对书的每篇文章都作为一个索引信息,
当然你要承受大索引的数据了。
所以简单的总结来说,文档定义为一个个客户想查询到的信息粒度比较合适。
- 字段基本定义
文档是由字段组成的,类似于数据库的一条记录,在数据库中记录一般都有一个主键,文档也类似,文档通过唯一键id来在分布式部署的时候路由到
相应的shard上去,也便于索引确认唯一的文档,如果你两次发的id是一样的,solr将会覆盖上一个文档。
solr的字段定义一般形如:
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
如果是唯一键,则配置为: <uniqueKey>id</uniqueKey>
通过上面字段的定义我们看到字段有几个重要属性:
name: 标示这个字段的名称;
type:标示字段的类型,注意这里面的类型不同于java的类型,是solr自己定义的,通过这个类型solr知道这个字段
该是否分词等,注意定义为string类型一般是不做分词的,做分词可以定义为text*类型。
indexed:定义文档是否被索引,这个可以理解为我们是否在此字段上进行搜索,如果在,这个定义为true,否则为false;另外如果你需要在这个字段上进行排序、分组、切片、 提供建议、或者执行一个查询函数,你也需要定义这个索引为true。
举个例子,你假设定义一个test1字段,这个值为true,你就可以可以通过q=test1:foo这种方式来进行查询;如果定义为false,
即使你的文档中有这个字段而且值就是foo,那么也查不到数据。
stored :定义这个字段内容是否可以作为返回结果的一部分,如果是,则定义为true,否则为false。
举个例子,你如果想提取test1字段可以通过制定fl=test1来提取,如果配置为true则可以提取到这个值,如果是false则提取不到。
这个indexed和stored可以都配置为false,一般在你动态字段中定义,一般用来忽略某个值。
- 字段其他属性
docValues:表示此域是否需要添加一个 docValues 域,这对 facet 查询, group 分组,排序, function 查询有好处,尽管这个属性不是必须的,
但他能加快索引数据加载,对 NRT 近实时搜索比较友好,且更节省内存,但它也有一些限制,比如当前docValues 域只支持 strField,UUIDField,
Trie*Field 等类型,且要求域的域值是单值而且是必须有值的或者有默认值的,不能是多值域
solrMissingFirst/solrMissingLast:在查询结果排序的时候,如果这个字段没有值的话,这个文档是放在查询结果有值字段的前面/后面。
multValued: 这个字段是否存在多个值,如果存在多个值设置为true,sorlj用add而不是set来设置这个字段。
omitNorms: 此属性若设置为 true ,即表示将忽略域值的长度标准化,忽略在索引过程中对当前域的权重设置,且会节省内存。
只有全文本域或者你需要在索引创建过程中设置域的权重时才需要把这个值设为 false, 对于基本数据类型且不分词的域(field)
如intFeild,longField,StrField 等默认此属性值就是 true, 否则默认就是 false.
这个如果设置为false,可以起到加强短文章的boost作用,比如你有一个100个单词的文档含有这个词,还有一个1000个单词的文档
同样只含有一次这个值,那么在比较相关性的时候,100个单词的文章相关性更强。如果你的文章长度大小差不多可以不设置这个值。
required: 添加文档时,该字段必须存在,类似于数据库的非空。
termVectors: 设置为 true 即表示需要为该 field 存储项向量信息,当你需要MoreLikeThis 功能时,则需要将此属性值设为 true ,这样会带来一些性能提升。
说明下,在文档和查询语句进行匹配的时候,需要用到相关度判断,就是通过单词向量来处理的。
这个设置为true会记录词出现的频次和位置,可以提取出来。
termPositions: 是否termVectors中在存储 Term 的起始位置信息,这会增大索引的体积,但高亮功能需要依赖此项设置,否则无法高亮,
可以通过positions提取出来,目前没测试过。
termOffsets: 设置为true则记录词的偏移量。
default: 如果这个字段没有指定值的时候,使用的默认值。
- 动态字段(Dynamic Fields)
所谓的动态字段,是为了简化字段的定义,设想下一个文档的字段有几十个,定义起来非常麻烦,有很多属性是相同的,solr支持通过字段名匹配的字段可以通用一个配置,
这就是动态字段.
举个例子:
<dynamicField name="*_txt" type="text_general" indexed="true" stored="true" multiValued="true"/>
标示,以_txt结尾的字段都匹配这个配置,其他属性同一般字段。这样可以不用经常修改这个字段。
- 复制字段(Copy Field)
复制字段的作用就是可以将多个字段复制到一个字段中,这样便于搜索,当然你要保证两个字段间类型的兼容性。
注意
1)只能从定义其他其他字段复制到复制字段,不能从复制 字段到复制字段,可以限制复制多少个字段长度。
2) 一般复制字段需要定义为多值存储。
3)复制字段一般不用再存储了,存储无意义。
定义如下:
<copyField source="head" dest="teaser" maxChars="300"/>
一个整体定义:
<dynamicField name="*_company" type="string" indexed="true" stored="true"/>
<dynamicField name="*_entity" type="string" indexed="true" stored="true"/>
<field name="database_ids" type="string" indexed="true" stored="false"/>
复制字段定义如下:
<copyField source="*_company" dest="database_ids"/>
<copyField source="*_entity" dest="database_ids"/>
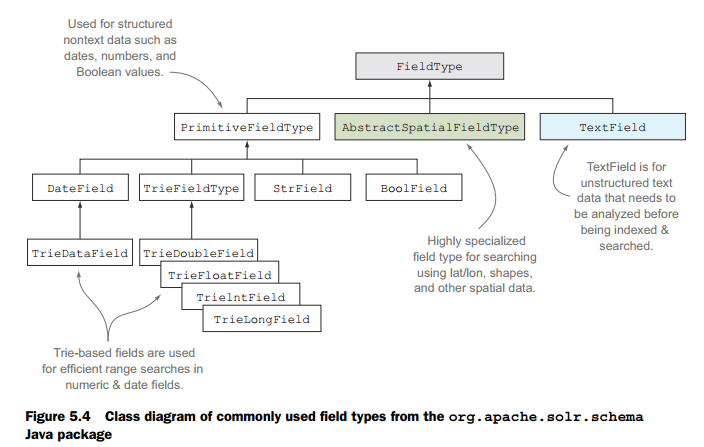
二、字段类型
有6种基本类型都是不分词的:
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
说明: 不被分词,支持docvalue,不能是多值,不能为空或有默认值。
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
说明: 只能取true或false
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>
说明:1、支持docvalue字段,同样不能为空或者有默认值不能为多值。
2、如果支持快速范围搜索的话,建议用tint等。
3、precisionStep 这个是字段划分几个范围,这个值设置越小,划分的范围就多,范围查询速度更快,更占索引空间。
positionIncrementGap: 这个是多值使用,多个值之间间隔,常用语复制字段防止误匹配。
<fieldType name="date" class="solr.TrieDateField" precisionStep="0" positionIncrementGap="0"/>
说明: 日期类型,支持格式:1995-12-31T23:59:59Z,默认存储的是UTC-0区的时间。
北京时间存储的时候一般需要+8个小时存储。
<field name=”timestamp” type=”date” indexed=”true” stored=”true” default=”NOW+8HOUR” multiValued=”false”/>
<fieldtype name="binary" class="solr.BinaryField"/>
说明:经过base64编码的二进制数据,查询的时候,查询的内容也要经过base64编码来查询。
<fieldType name="random" class="solr.RandomSortField" indexed="true" />
说明:随机数字段,需要伪随机数排序的时候使用。
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
xxx
</fieldType>
说明: text字段,需要分词的定义为这种类型,xxx标示中间还有很多内容,比如定义分词器等。
三、更新索引
按照前面文章所述,我们知道solr是可以通过HTTP的接口发送JSON或者XML或者Javabin(一种二进制+文本混合模式)的http报文来进行solr的索引的更新的。
通过xml的格式如下,在json格式中,多个文档用数组形式每个文档必须是json报文格式,多值也采用文档形式。另外solr还可以通过DIH(Data Import Handler)的
方式来从数据库、json格式的报文或者xml报文导入数据。还可以从二进制文件,比如PDF、比如MS office提取数据。
<add> <doc> <field name="id">1</field> <field name="test_s">hello</field> <field name="type_s">post</field>
<field name="mutilvalue_s">value1</field> <field name="mutilvalue_s">value2</field> </doc> <doc> <field name="id">2</field> <field name="test_s">hello2</field> <field name="type_s">get</field> <field name="mutilvalue_s">value3</field> <field name="mutilvalue_s">value4</field> </doc> </add>
更新索引在solrconfig.xml中的配置如下:
<updateHandler class="solr.DirectUpdateHandler2">
<updateLog>
<str name="dir">${solr.ulog.dir:}</str>
</updateLog>
<autoCommit>
<maxTime>60000</maxTime>
<maxDocs>30000</maxDocs>
<openSearcher>false</openSearcher>
</autoCommit> <autoSoftCommit>
<maxTime>${solr.autoSoftCommit.maxTime:-1}</maxTime>
</autoSoftCommit> <!--
<listener event="postCommit" class="solr.RunExecutableListener">
<str name="exe">solr/bin/snapshooter</str>
<str name="dir">.</str>
<bool name="wait">true</bool>
<arr name="args"> <str>arg1</str> <str>arg2</str> </arr>
<arr name="env"> <str>MYVAR=val1</str> </arr>
</listener>
--> </updateHandler>
在配置中有autoCommit 相关配置,在说明之前先说下commit,一般说的commit是指硬提交,目的是使所有在这个collection上的未提交的内容刷新到可持久化设备上去,
并且打开新的搜索器,预热搜索器,使搜索可见。
简单来说软提交softCommit的目的是为了使搜索可见,并不保证数据被持久化,在服务器崩溃的时候可能数据会丢失。
这里面的自动提交,默认是硬提交,新的搜索器是否打开是通过:openSearcher 控制的,如果为true就打开,那么这时候提交的数据可见,这里面可以配置固定的诗句进行
自动提交(<maxTime>60000</maxTime> 单位是毫秒)或者未提交的文档数量( <maxDocs>30000</maxDocs>)达到多少进行提交,两个都配置的时候,第一个达到的起效。
自动软提交的配置类似。
整个更新的流程:
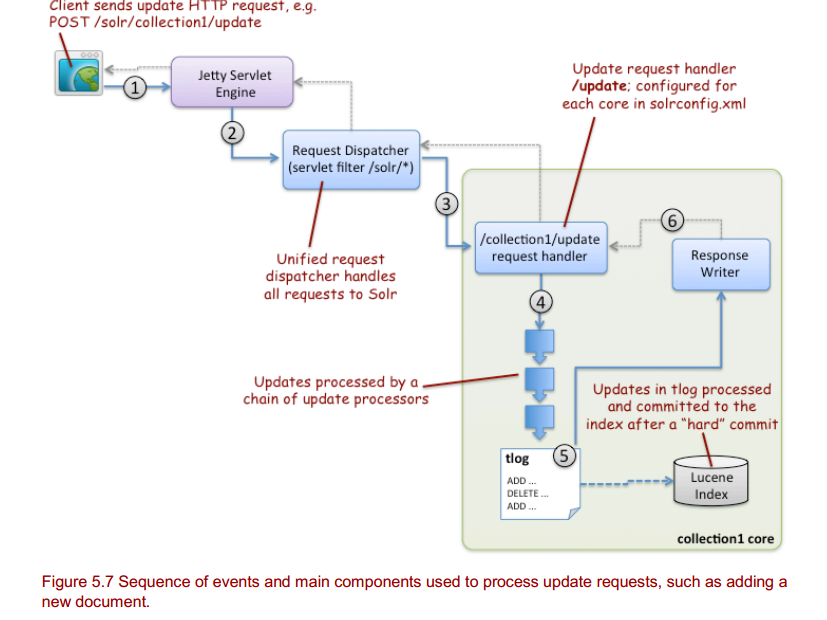
说明:
1、客户端通过http发送xml、json或javabin格式文档给jetty服务器。
2、jetty服务器根据地址路由到solr这个web程序。
3、solr根据/update 通过solrconfig.xml的配置:
<requestHandler name="/update" class="solr.UpdateRequestHandler">
</requestHandler>
来选定处理的handler。
4、更新的handler根据schemal.xml配置的文档字段类型进行具体的分析处理。
5、将添加文档操作记录到事务日志中。
6、将数据记录到事务日志后,只要成功了,无论是否做了commit都可以返回了,即使后面没有做commit,服务器有问题,在启动的时候仍然可以通过事务日志进行恢复。
3.1 事务日志
事务日志是保障索引数据不丢失的策略之一,只要你更新索引,比如在solrJ中使用了solrJ服务的相关add方法,虽然没提交数据,但是这些数据仍然被记录在了solr的事务日志中,前文配置为:
<updateLog>
<str name="dir">${solr.ulog.dir:}</str>
</updateLog>
事务日志的作用:
1、事务日志在客户端未发送commit而且没有进行自动提交的时候,如果客户端崩溃了,可以通过事务日志进行恢复。
2、事务日志在实时搜索中被使用,通过文档id查询,自动更新时候也是用这个文档。
3、事务日志在solrColud部署中,由副本更新时候使用。
事务日志内容:
我去看过,基本上是记录文档的信息,操作的基本信息。事务日志在提交前都保留,一旦进行了硬提交,老的事务日志会删除,新的事务日志会建立起来。
事务日志的大小:
事务日志的大小,要看你的提交的频率,如果你设置了自动提交,那么自动提交的最大文档数量,也就是一个事务日志的最大大小,更大的事务日志可能
会造成在服务器恢复的时候耗费更长的时间来恢复。
3.2 更新字段操作
solr中不存在update操作,是通过先delete后add操作完成的,solr可以通过自己的内部机制,设置了update的具体一个文档字段的操作,其实也是通过先提取出来这个文档的信息,再更新的。
<add>
<doc>
<field name ="id">1</field>
<field update="set" name ="count">10</field>
</doc></add>
并发更新:
在solr运行的时候,如果存在多个客户端来更新同一个文档的时候,可能会存在着并发问题,这个问题,solr是通过_version_来控制的,并发更新的时候,为了防止重复更新或者更新错误的情况,在更新的时候带上这个字段(<field name="_version_">1234567890</field>),则solr在做具体的操作的时候,会从索引或事务日志中提取版本信息,如果是这个版本则更新,不是则抛出异常。
版本信息可以通过id和版本号来得到。
这个版本信息字段_version_还可以做其他作用。
1: 仅仅标示这个文档必须存在。
>1:则标示为正式的版本号,必须存在而且是这个版本,否则失败;
0:无并发控制,如果存在则重写;
<0:文档必须不存在。
3.3 其他更新参数
段合并:
由前面文章我们知道,solr的索引是由段组成,更新索引的时候是写入一个段的信息,几个段共同组成一个索引,在solr优化索引的时候或其他的时候,solr的段是会合并的。
所以有不少相关段控制的信息。
<mergeFactor>10</mergeFactor>
说明:合并因子,有两层含义:
1、内存中有10个文档的时候,会创建一个段;
2、当一个索引中段的个数达到10的时候,这10个段会合并成一个段,简单的说,一个索引中最多只能有9个段。
注意,如果一味的这样合并可能会导致一个段的内容过多,索引变慢,所以solr通过maxMergeDocs 这个参数来指定一个段的最大文档数量,即使以后solr的段的个数超过了
10的,如果合并后不满足一个段的最大文档个数为:maxMergeDocs的条件,则不进行合并。
minMergeSize: 指定最小的合并段大小,如果段的大小小于这个值,则可以参加合并。
maxMergeSize:当一个段的大小大于这个值的时候就不参与合并了。
maxMergeDocs:当文档数据量大于这个的时候,这个段就不参与合并了。
合并段默认通过: <mergeScheduler class="org.apache.lucene.index.ConcurrentMergeScheduler"/>配置类来处理。
底层更新:
<updateHandler class="solr.DirectUpdateHandler2">是配置底层更新的相关数据,不能同 <requestHandler name="/update" class="solr.UpdateRequestHandler">相互混淆了。
这里面涉及到:
1、首先这些存储存在什么位置:
<dataDir>${solr.data.dir:}</dataDir> 这个更改默认的data位置,一般data是在solr的根目录下面的core的子目录的data里面。
建议如果存在多个磁盘可以不同的core存放在不同的磁盘上。
2、具体的写操作的实现:
<directoryFactory name="DirectoryFactory"
class="${solr.directoryFactory:solr.NRTCachingDirectoryFactory}"> <!-- These will be used if you are using the solr.HdfsDirectoryFactory,
otherwise they will be ignored. If you don't plan on using hdfs,
you can safely remove this section. -->
<!-- The root directory that collection data should be written to. -->
<str name="solr.hdfs.home">${solr.hdfs.home:}</str>
<!-- The hadoop configuration files to use for the hdfs client. -->
<str name="solr.hdfs.confdir">${solr.hdfs.confdir:}</str>
<!-- Enable/Disable the hdfs cache. -->
<str name="solr.hdfs.blockcache.enabled">${solr.hdfs.blockcache.enabled:true}</str>
<!-- Enable/Disable using one global cache for all SolrCores.
The settings used will be from the first HdfsDirectoryFactory created. -->
<str name="solr.hdfs.blockcache.global">${solr.hdfs.blockcache.global:true}</str> </directoryFactory>
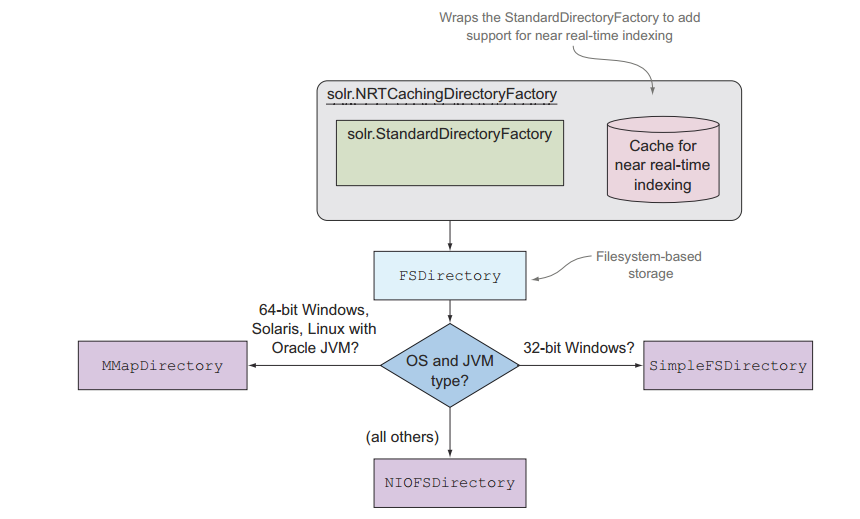
默认的NRTCachingDirectoryFactory 实际上是standardDirectoryFactory的封装。
在实际运行过程中,solr会根据系统和JVM的版本进行。
1、在linux、windows、solaris的64位操作系统用的是MMapDirectory中。
2、在32windows下用的是SimpleFSDirectory。
3、NIOFSDirectory :利用NIO优化,避免从相同的文件读数据需要同步。不能在windows上利用这个,是因为JVM的bug。
在solr的管理界面,可以看到Directory的具体实现。
在solrconfig.xml中,你可以重写默认的Directory的实现,通过如下的更改:
<directoryFactory name="DirectoryFactory"
class="${solr.directoryFactory:solr.MMapDirectoryFactory}"/>
在64位windows上、solaris、和linux上,它通过虚拟内存管理功能可以获得读的更好性能。
Solr学习之四-Solr配置说明之二的更多相关文章
- Solr学习总结 Solr的安装与配置
接着前一篇,这里总结下Solr的安装与配置 1.准备 1.安装Java8 和 Tomcat9 ,java和tomcat 的安装这里不再重复.需要注意的是这两个的版本兼容问题.貌似java8 不支持,t ...
- Solr学习之三 solr配置说明之一
严格来说,我这篇内容,主要是根据Solr in Action关于配置的说明,以及参考Solr的wiki写的算是读书笔记吧,所有的图片默认来自Solr in Action这本书. 这本书我觉得对学习So ...
- 02——Solr学习之Solr安装与配置(linux上的安装)
借鉴博客:https://www.jianshu.com/p/1100f54fcbd8 https://www.cnblogs.com/jepson6669/p/9134652.html 1.准备一个 ...
- 03——Solr学习之Solr的使用(不会用)
1.先放上次在linux搭建成功的solr管理UI界面 2.有个很蛋疼的问题我就要吐槽一下了 由于没接触过solr这玩意,在百度上一顿操作搜索怎么用,怎么导入数据,建索引库什么的,看了一大片别人的博客 ...
- 我的solr学习笔记--solr admin 页面 检索调试
前言 Solr/Lucene是一个全文检索引擎,全文引擎和SQL引擎所不同的是强调部分相关度高的内容返回,而不是所有内容返回,所以部分内容包含在索引库中却无法命中是正常现象. 多数情况下我们 ...
- Solr学习之二-Solr基础知识
一 基本说明 简单来说Solr是基于Lucene的高性能的,开源的Java企业搜索服务器.Solr可以看作一个Web app,运行在tomcat或Jetty这类HTTP服务器上, 底层是一个基于Luc ...
- Solr学习总结(二)Solr的安装与配置
接着前一篇,这里总结下Solr的安装与配置 1.准备 1.安装Java8 和 Tomcat9 ,java和tomcat 的安装这里不再重复.需要注意的是这两个的版本兼容问题.貌似java8 不支持,t ...
- Solr学习总结(五)SolrNet的基本用法及CURD
上一篇已经讲到了Solr 查询的相关的参数.这里在讲讲C#是如何通过客户端请求和接受solr服务器的数据, 这里推荐使用SolrNet,主要是:SolrNet使用非常方便,而且用户众多,一直都在更新, ...
- solr课程学习系列-solr服务器配置(2)
本文是solr课程学习系列的第2个课程,对solr基础知识不是很了解的请查看solr课程学习系列-solr的概念与结构(1) 本文以windows的solr6服务器搭建为例. 一.solr的工作环境: ...
随机推荐
- 记录规则 – 销售只能看到自己的客户,经理可以看到全部
OpenERP中的权限管理有四个层次: 菜单级别: 即,不属于指定菜单所包含组的用户看不到该菜单.不安全,只是隐藏菜单,若用户知道菜单ID,仍然可以通过指定URL访问 对象级别: 即,对某个对象是否有 ...
- 实战c++中的vector系列--将迭代器转换为索引
stl的迭代器非常方便 用于各种算法. 可是一想到vector.我们总是把他当做数组,总喜欢使用下标索引,而不是迭代器. 这里有个问题就是怎样把迭代器转换为索引: #include <vecto ...
- echo “新密码”|passwd --stdin 用户名
--stdin This option is used to indicate that passwd should read the new password from standard input ...
- Highcharts网页版
//后台控制器中(SpringMVC) @RequestMapping(value="/getAll",method=RequestMethod.POST) @ResponseBo ...
- 在ListView的右边添加字母列表
在ListView的右边添加字母列表,点击某个字母时,列表就滚动到预期位置. <!-- 数字和字母栏在标题栏下边并且停靠在右边 --> <com.txrj.sms.component ...
- 【laravel5.4】自定义404、503等页面
1.处理自定义错误或不存在页面:生产环境一定要关闭debug模式. public function render($request, Exception $exception) { if ($exce ...
- maven依赖导致包重复加载及冲突
maven中配置 pom时,有时配置添加一个 jar却会自动导入多个 jar包,往往这些自动导入的 jar包会与我们项目中已存在的 jar包重复,从而导致冲突.由于这些 jar包不是我们自己配置的,所 ...
- C#利用反射机制调用dll
利用反射进行动态加载和调用. Assembly ass=Assembly.LoadFrom(DllPath); //利用dll的路径加载,同时将此程序集所依赖的程序集加载进来,需后辍名.dll Ass ...
- HDUOJ ---1269迷宫城堡
http://acm.hdu.edu.cn/showproblem.php?pid=1269 迷宫城堡 Time Limit: 2000/1000 MS (Java/Others) Memory ...
- mysql 必须掌握的工具pt-query-digest安装
mysql 必须掌握的工具pt-query-digest 古人云:工欲善其事,必先利其器.作为一名优秀的mysql dba也需要有掌握几个好用的mysql管理工具,所以我也一直在整理和查找一些能够便于 ...