leetcode-49-字母异位词分组(神奇的哈希)
题目描述:
给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
示例:
输入:["eat", "tea", "tan", "ate", "nat", "bat"],
输出:
[
["ate","eat","tea"],
["nat","tan"],
["bat"]
]
说明:
- 所有输入均为小写字母。
- 不考虑答案输出的顺序。
给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
示例:
输入:
["eat", "tea", "tan", "ate", "nat", "bat"],
输出:
[
["ate","eat","tea"],
["nat","tan"],
["bat"]
]说明:
- 所有输入均为小写字母。
- 不考虑答案输出的顺序。
要完成的函数:
vector<vector<string>> groupAnagrams(vector<string>& strs)
说明:
1、给定一个vector,里面装着多个string,要求把这些string进行分组。
两个字符串拥有相同的字母,就是同一组。(题目说字母相同,顺序不同,但测试样例中出现了字母相同顺序也相同的,也在同一组)
字符串只含有小写字母。
每一组存在一维vector中,所有组存放在二维vector中,最终返回二维vector。
2、这道题笔者最开始想用一个双重循环,外层循环对每个字符串进行迭代,内层循环判断当前字符串跟前面的字符串,有没有哪个是相同字母的。
关于内层循环的判断,笔者最开始想用异或来处理,但后来发现it和ro这四个不同的字母,i^t^r^o的结果为0……
也就是我们不能用异或结果是不是0来判断字母是不是相同。
异或应该只是适用于只有一个字母不同,而其他字母都相同的情况。
那不能用异或,那就用普通的“空间换时间”,我们建立长度为26的vector,在内层循环中判断两个字符串是否拥有相同字母。
在对长度为26的vector进行操作前,我们先判断两个字符串的长度是否相等,这可以省去很多时间。
代码如下:(附详解)
bool judge(string a,string b)//判断两个字符串是否拥有相同的字母
{
vector<int>table(26,0),t1(26,0);
for(char i:a)
table[i-'a']++;
for(char i:b)
table[i-'a']--;
if(table!=t1)return false;//如果table不是全为0,返回false
return true;//否则返回true
}
vector<vector<string>> groupAnagrams(vector<string>& strs)
{
vector<vector<string>>res={{strs[0]}};//初始化最终要返回的二维vector
bool flag;
for(int i=1;i<strs.size();i++)//循环迭代每个字符串
{
flag=0;
for(int j=0;j<res.size();j++)//对当前的字符串,判断是否跟前面出现过的字符串,拥有相同字母
{
if(strs[i].size()!=res[j][0].size())//长度的判断
continue;
if(judge(strs[i],res[j][0]))//字母相同的两个字符串
{
res[j].push_back(strs[i]);
flag=1;
break;
}
}
if(flag==0)//前面所有字符串跟当前字符串的字母都不相同
{
res.push_back({strs[i]});
}
}
return res;//最终返回res
}
上述代码也可以通过测试,但是实测1228ms,beats 2.20% of cpp submissions……太低了
那肯定还有更好的办法==
我们分析一下上述代码,发现耗费时间的地方在于:
①双重循环,如果可以改成单重循环就最好了。
②二维vector的不断申请空间、不断插入
第二点似乎很难避免,我们要初始化res拥有多长的长度?跟给定的一维vector strs一样长?那多出来那部分怎么处理……
不断地pop_back()?这也是一个方法,但看了一下普遍的时间花费是36ms左右,我这样改可能效果也不会很大……
那第一点要怎么改善?外层循环肯定不可少了,内层循环改成O(1)的时间复杂度?
我们想一下,如果是数字串而不是字母串,我们会怎样判断当前数字串有没有出现过?
比如12,32,12,当前数字是第三个数字12,我们可以用vector,前面有了vector[12]=1,vector[32]=1,此时我们再查询一下当前数字12的对应vector[12],是不是0。
如果是0,那么没有出现过,如果不是0,那么出现过。
这个时候我们不用一个个地去循环,去遍历,直接就访问了。
那可不可以同样利用这种方法来处理字母串呢?
答案是可以的,我们可以用哈希表。
哈希表其实就是数组+链表的结构,在c++中,笔者觉得map这种数据结构可能就是实现了哈希表的算法。
哈希表结合了数组的快速访问、修改和链表的无限长度两个特点,可以参考下面这张图。
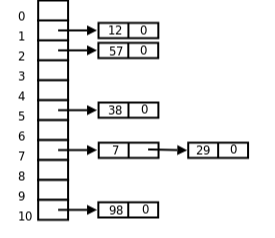
左边是数组,快速访问和修改,右边的链表延伸出去,无限长度。
我们以字母串作为键值,像用vector查看数字串一样去判断。
但有的同学可能有想法,比如“ate”和“eat”这两个键值都不一样,你怎么判断?
“ate”和“eat”是不一样,但它们有共性,那就是拥有的字母相同,我们可以对它们的字母排下序,就可以转化为相同的键值了。
代码如下:(附详解)
vector<vector<string>> groupAnagrams(vector<string>& strs)
{
vector<vector<string>>res;//最终要返回的二维vector
unordered_map<string,int>m1;//定义一个map作为哈希表
int index=0;
vector<string> strs1=strs;//用于重新排序strs中的每个字符串,strs是原本
for(int i=0;i<strs1.size();i++)
{
sort(strs1[i].begin(),strs1[i].end());//对字符串中的字母进行排序
if(!m1.count(strs1[i]))//如果之前没有出现过
{
m1[strs1[i]]=index;//更新一下
index++;//index作为res中的索引
res.push_back({strs[i]});//插入一个一维的vector
}
else//如果有出现过了
{
res[m1[strs1[i]]].push_back(strs[i]);//res找到对应的索引,插入当前字符串
}
}
return res;//最终返回res
}
上述代码实测28ms,beats 93.68% of cpp submissions。
哈希表其实就是我们平时常用的vector的升级版本,用map实现时,既可以实现快速访问,又有好的哈希函数,使得空间充足。
神奇神奇~
leetcode-49-字母异位词分组(神奇的哈希)的更多相关文章
- LeetCode 49: 字母异位词分组 Group Anagrams
LeetCode 49: 字母异位词分组 Group Anagrams 题目: 给定一个字符串数组,将字母异位词组合在一起.字母异位词指字母相同,但排列不同的字符串. Given an array o ...
- Java实现 LeetCode 49 字母异位词分组
49. 字母异位词分组 给定一个字符串数组,将字母异位词组合在一起.字母异位词指字母相同,但排列不同的字符串. 示例: 输入: ["eat", "tea", & ...
- Leetcode 49.字母异位词分组
字母异位词分组 给定一个字符串数组,将字母异位词组合在一起.字母异位词指字母相同,但排列不同的字符串. 示例: 输入: ["eat", "tea", " ...
- LeetCode 49. 字母异位词分组(Group Anagrams)
题目描述 给定一个字符串数组,将字母异位词组合在一起.字母异位词指字母相同,但排列不同的字符串. 示例: 输入: ["eat", "tea", "ta ...
- 【LeetCode】49. 字母异位词分组
49. 字母异位词分组 知识点:字符串:哈希表 题目描述 给你一个字符串数组,请你将 字母异位词 组合在一起.可以按任意顺序返回结果列表. 字母异位词 是由重新排列源单词的字母得到的一个新单词,所有源 ...
- LeetCode:字母异位词分组【16】
LeetCode:字母异位词分组[16] 题目描述 给定一个字符串数组,将字母异位词组合在一起.字母异位词指字母相同,但排列不同的字符串. 示例: 输入: ["eat", &quo ...
- leetcode TOP100 字母异位词分组
字母异位词分组 给定一个字符串数组,将字母异位词组合在一起.字母异位词指字母相同,但排列不同的字符串. 思路: 一个map,将每个字符串字符进行记数,字符作为map的key,次数初始为零,以此来标识字 ...
- Leetcode题库——49.字母异位词分组【##】
@author: ZZQ @software: PyCharm @file: leetcode49_groupAnagrams.py @time: 2018/11/19 13:18 要求:给定一个字符 ...
- Leetcode题目49.字母异位词分组(中等)
题目描述: 给定一个字符串数组,将字母异位词组合在一起.字母异位词指字母相同,但排列不同的字符串. 示例: 输入: ["eat", "tea", "t ...
- leetcode刷题-49字母异位词分组
题目 给定一个字符串数组,将字母异位词组合在一起.字母异位词指字母相同,但排列不同的字符串. 思路 由于异位词由相同字母构成,所以可以用一个顺序的字符串作为这些字母异位词的标志,由此可以想到字典的方法 ...
随机推荐
- C#开发微信公众化平台
C#开发微信公众化平台 写在前面 服务号和订阅号 URL配置 创建菜单 查询.删除菜单 接受消息 发送消息(图文.菜单事件响应) 示例Demo下载 后记 最近公司在做微信开发,其实就是接口开发,网上 ...
- Vue.js基础知识
<!DOCTYPE html> <html lang="en" xmlns:v-bind="http://www.w3.org/1999/xhtml&q ...
- springMVC框架介绍以及运行流程(图解)
1 Springmvc是什么? spring web mvc和struts2都属于表现层的框架,spring web mvc是spring框架的一部分(所以spring mvc与spring之间不需要 ...
- 配置yum源方法,以及失效时的处理
正常方法如下: step1: 备份原CentOS-Base.repo 文件 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-B ...
- sklearn.metrics import precision_recall_fscore_support
二分类/多分类/多标签 对于二分类来说,必须定义一些matrics(f1_score,roc_auc_score).在这些case中,缺省只评估正例的label,缺省的正例label被标为1(可以通过 ...
- win7下面iis错误汇总
1.分析器错误消息: 无法识别的属性“targetFramework”.请注意属性名称区分大小写 解决方法: 修改.NET Framework 版本为相应版本即可,我以前用的是2.0换成4.0的时候出 ...
- Groovy 读取json文件,并用gson反序列化为List集合
Groovy 读取json文件,并用gson反序列化 package com.bicycle.util import bicycle_grails.StationInfo import com.goo ...
- 单链表(带random指针)深拷贝(Copy List with Random Pointer)
问题: A linked list is given such that each node contains an additional random pointer which could poi ...
- 深入jetty的使用详解
简介: Jetty 是一个用 Java 实现.开源.基于标准的,并且具有丰富功能的 Http 服务器和 Web 容器,可以免费的用于商业行为.Jetty 这个项目成立于 1995 年,现在已经有非常多 ...
- Android-SurfaceView生命周期
SurfaceView的生命周期,和 Activity生命周期,Service生命周期,BroadcastReceiver生命周期,等,不一样: 因为SurfaceView显示的是(视频画面,游戏画面 ...