Zookeeper(二) zookeeper集群搭建 与使用
一、zookeeper集群搭建
鉴于 zookeeper 本身的特点,服务器集群的节点数推荐设置为奇数台。我这里我规划为三台, 为别为 hadoop01,hadoop02,hadoop03
1、下载地址: http://mirrors.hust.edu.cn/apache/zookeeper/
版本号: zookeeper-3.4.7.tar.gz
2、解压安装到自己的目录
tar -zxvf zookeeper-3.4.7.tar.gz -C apps/
3、修改配置文件
cd conf/
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg



二、启动软件,并验证安装是否成功

三、zookeeper集群使用
1、cli使用
首先,我们可以是用命令 bin/zkCli.sh 进入 zookeeper 的命令行客户端,这种是直接连接本机 的 zookeeper 服务器,还有一种方式,可以连接其他的 zookeeper 服务器,只需要我们在命 令后面接一个参数-server 就可以了。 例如: zkCli.sh –server hadoop01:2181
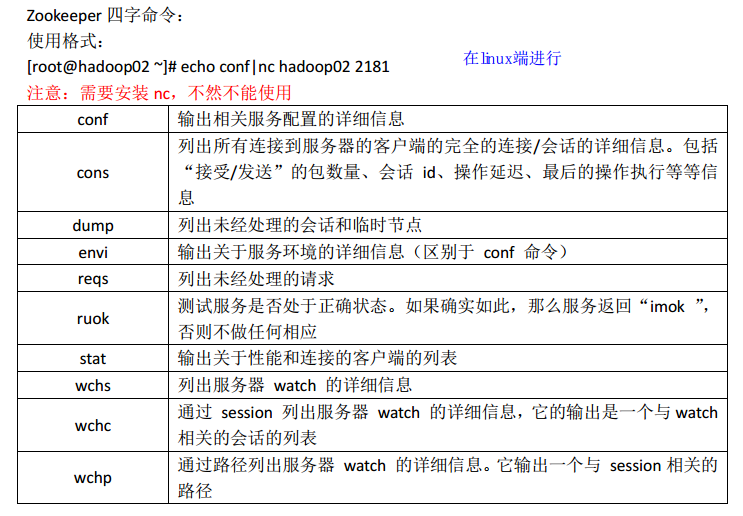
进入命令行之后,键入 help 可以查看简易的命令帮助文档,

znode 数据信息字段解释


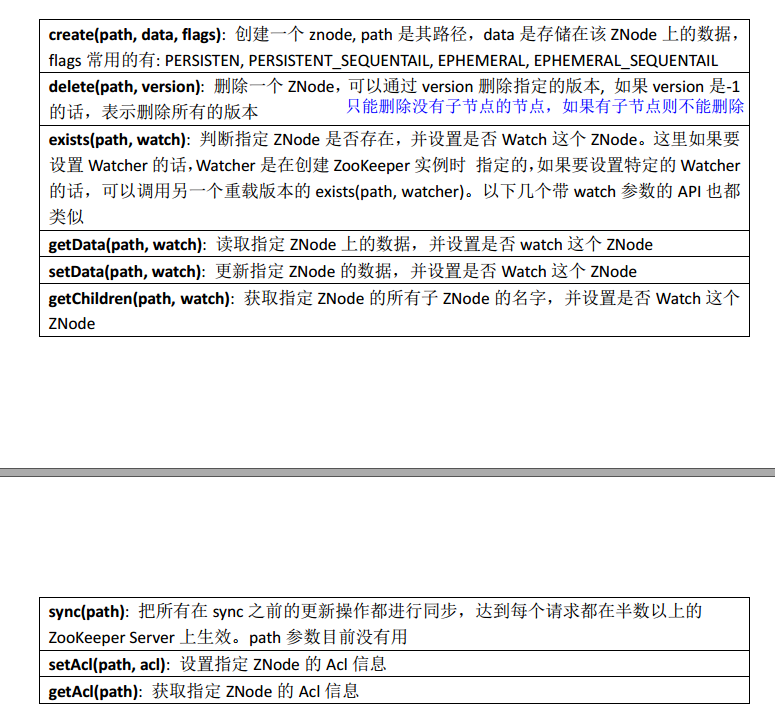
2、zookeeper Java API 使用
- package com.ghgj.zkapi;
- import java.text.SimpleDateFormat;
- import java.util.Date;
- import java.util.List;
- import org.apache.zookeeper.CreateMode;
- import org.apache.zookeeper.KeeperException;
- import org.apache.zookeeper.ZooDefs.Ids;
- import org.apache.zookeeper.ZooKeeper;
- import org.apache.zookeeper.data.Stat;
- public class ZKAPIDEMO {
- // 获取zookeeper连接时所需要的服务器连接信息,格式为主机名:端口号
- private static final String ConnectString = "hadoop02:2181";
- // 请求了解的会话超时时长
- private static final int SessionTimeout = 5000;
- public static void main(String[] args) throws Exception {
- /**
- * 获取zookeeper链接, 要求的连接参数至少有三个: ConnectString:服务器的连接信息
- * SessionTimeout:请求连接的超时时长 Watch:添加监听器
- */
- ZooKeeper zk = new ZooKeeper(ConnectString, SessionTimeout, null);
- // 根据拿到的zk连接去做相应的操作
- // 查看节点数据
- // byte[] data = zk.getData("/ghgj/hadoop", false, null);
- // System.out.println(new String(data));
- // 查看子节点的信息
- // String parentNodePath = "/ghgj";
- // List<String> childrens = zk.getChildren(parentNodePath, false);
- // for(String child : childrens){
- // System.out.println(parentNodePath+"/"+child);
- // }
- // 修改节点的数据
- // Stat setData = zk.setData("/ghgj/hadoop",
- // "hadoopsprakjsdlfkj".getBytes(), -1);
- // long mtime = setData.getMtime();
- // SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
- // System.out.println(sdf.format(new Date(mtime)));
- // 添加持久节点znode
- String addPathnode = "/spark/node";
- String path = zk.create(addPathnode, "node".getBytes(),
- Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL);
- System.out.println(path);
- // 添加短暂型节点
- // String addPathnode1 = "/ghgj/hive1";
- // String path1 = zk.create(addPathnode1, "hive1".getBytes(),
- // Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
- // System.out.println(path1);
- // Thread.sleep(5000);
- // 删除一个带有多级子节点的znode
- // boolean rmr = rmr("/zk", zk);
- // System.out.println(rmr?"删除成功":"删除失败");
- zk.close();
- }
- public static Stat exists(String path, ZooKeeper zk) throws Exception {
- Stat exists = zk.exists("/ghgj/hadoop", false);
- if (null != exists) {
- System.out.println("该节点/ghgj/hadoop还存在");
- return exists;
- } else {
- System.out.println("该节点/ghgj/hadoop不存在");
- return null;
- }
- }
- public static boolean rmr(String path, ZooKeeper zk) throws Exception {
- // 判断节点存在不存在
- Stat stat = exists(path, zk);
- // if (stat.getNumChildren() == 0) {
- List<String> children = zk.getChildren(path, false);
- if (children.size() == 0) {
- // 删除节点
- zk.delete(path, -1);
- } else {
- // 要删除这个有子节点的父节点,那么就需要先删除所有子节点,然后再删除该父节点,完成对该节点的级联删除
- // 删除有子节点的父节点下的所有子节点
- for (String nodeName : children) {
- System.out.println(path);
- rmr(path + "/" + nodeName, zk);
- }
- // 删除该父节点
- rmr(path, zk);
- }
- return true;
- }
- }
Zookeeper(二) zookeeper集群搭建 与使用的更多相关文章
- zookeeper安装与集群搭建
此处以centos系统下zookeeper安装为例,详细步骤可参考官网文档:zookeeper教程 一.单节点部署 1.下载zookeeper wget http://mirrors.hust.edu ...
- 基于zookeeper的Swarm集群搭建
简介 Swarm:docker原生的集群管理工具,将一组docker主机作为一个虚拟的docker主机来管理. 对客户端而言,Swarm集群就像是另一台普通的docker主机. Swarm集群中的每台 ...
- zookeeper及kafka集群搭建
zookeeper及kafka集群搭建 1.有关zookeeper的介绍可参考:http://www.cnblogs.com/wuxl360/p/5817471.html 2.zookeeper安装 ...
- Zookeeper简介与集群搭建【转】
Zookeeper简介 Zookeeper是一个高效的分布式协调服务,可以提供配置信息管理.命名.分布式同步.集群管理.数据库切换等服务.它不适合用来存储大量信息,可以用来存储一些配置.发布与订阅等少 ...
- 【运维技术】Zookeeper单机以及集群搭建教程
Zookeeper单机以及集群搭建教程 单机搭建 单机安装以及启动 安装zookeeper的前提是必须有java环境 # 选择目录进行下载安装 cd /app # 下载zk,可以去官方网站下载,自己上 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- zookeeper高可用集群搭建
前提:已经在master01配置好hadoop:在各个slave节点配置好hadoop和zookeeper: (该文是将zookeeper配置在各slave节点上的,其实也可以配置在各master上, ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- Zookeeper简介与集群搭建
Zookeeper简介 Zookeeper是一个高效的分布式协调服务,可以提供配置信息管理.命名.分布式同步.集群管理.数据库切换等服务.它不适合用来存储大量信息,可以用来存储一些配置.发布与订阅等少 ...
随机推荐
- Java构造方法与析构方法实例剖析
Java构造方法 类有一个特殊的成员方法叫作构造方法,它的作用是创建对象并初始化成员变量.在创建对象时,会自动调用类的构造方法. 构造方法定义规则:Java 中的构造方法必须与该类具有相同的名字,并且 ...
- jmeter逻辑控制器
刚开始学习,只写几种了解的逻辑控制器 1.简单控制器 只用来组合采样器和其他逻辑控制器,不影响jmeter的运行 2.循环控制器 用来循环执行采样器和其他逻辑控制器,例如一个用户发送特定请求多次,即可 ...
- Mac下布置appium环境
1.下载或者更新Homebrew:homebrew官网 macOS 不可或缺的套件管理器 $ /usr/bin/ruby -e "$(curl -fsSL https://raw.githu ...
- Java接口获取系统配置信息
Java获取当前运行系统的配置信息 接口:System.getProperty() 参数 描述 java.version Java运行时环境版本 java.vendor Java运行时环境供应商 ja ...
- 论文笔记:DeepFace: Closing the Gap to Human-Level Performance in Face Verification
2014 CVPR Facebook AI研究院 简单介绍 人脸识别中,通常经过四个步骤,检测,对齐(校正),表示,分类 论文主要阐述了在对齐和表示这两个步骤上提出了新的方法,模型的表现超越了前人的工 ...
- Python Pygame (3) 界面显示
显示模式: 之前使display模块的set_mode()的方法用来指定界面的大小,并返回一个Surface对象. set_mode()的原型如下: display.set_mode(resoluti ...
- MOOK学习
课程选择及其理由 课程:c++程序设计 教师:魏英 学校:西北工业大学 总共:48讲 选择理由:我其实之前找了好几个,但由于小白,思考了下(迷茫,感觉好像都不错),然后看了一下大家都选择了西北工业大学 ...
- 60行代码:Javascript 写的俄罗斯方块游戏
哈哈这个实在是有点意思 备受打击当初用java各种类写的都要几百行啦 先看效果图: 游戏结束图: javascript实现源码: [javascript] view plaincopyprint? & ...
- <浪潮之巅>读书笔记
<浪潮之巅>这本书通过介绍AT&T.IBM.微软.苹果.google等IT公司的发展历史,揭示科技工业的胜败规律,说明这些公司是如何在每一次科技革命浪潮到来时站在浪尖,实现跨越式发 ...
- C#高级编程 (第六版) 学习 第一章:.Net体系结构
第一章 .Net体系结构 1,公共语言运行库(Common Language Runtime, CLR) .Net Framework的核心是其运行库的执行环境,称为公共语言运行库,或.Net运行库. ...