scikit-learn 学习笔记-- Generalized Linear Models (二)
Lasso regression
今天介绍另外一种带正则项的线性回归, ridge regression 的正则项是二范数,还有另外一种是一范数的,也就是lasso 回归,lasso 回归的正则项是系数的绝对值之和,这种正则项会让系数最后变得稀疏:
其中,N" role="presentation" style="position: relative;">NN 是样本的个数。
Elastic Net
Elastic Net 这种线性回归将二范数和一范数的正则都考虑进去了,两种正则项以某种权重的方式组合在一起,所以类似一种弹性的模型,这大概也是其名称的由来吧,elastic net 的目标函数为:
elastic net 模型可以让模型像 lasso regression 一样具有一定的稀疏性,同时又保持 ridge regression 的稳定性
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import r2_score
np.random.seed(42)
n_samples, n_features = 100, 100
X = np.random.randn(n_samples, n_features)
coef = 3 * np.random.randn(n_features)
inds = np.arange(n_features)
np.random.shuffle(inds)
coef[inds[10:]] = 0 # sparsify coef
y = np.dot(X, coef)
# add noise
y += 0.01 * np.random.normal(size=n_samples)
# Split data in train set and test set
n_samples = X.shape[0]
X_train, y_train = X[:n_samples // 2], y[:n_samples // 2]
X_test, y_test = X[n_samples // 2:], y[n_samples // 2:]
# #############################################################################
# Lasso
from sklearn.linear_model import Lasso
alpha = 0.1
lasso = Lasso(alpha=alpha)
y_pred_lasso = lasso.fit(X_train, y_train).predict(X_test)
r2_score_lasso = r2_score(y_test, y_pred_lasso)
print(lasso)
print("r^2 on test data : %f" % r2_score_lasso)
# #############################################################################
# ElasticNet
from sklearn.linear_model import ElasticNet
enet = ElasticNet(alpha=alpha, l1_ratio=0.7)
y_pred_enet = enet.fit(X_train, y_train).predict(X_test)
r2_score_enet = r2_score(y_test, y_pred_enet)
print(enet)
print("r^2 on test data : %f" % r2_score_enet)
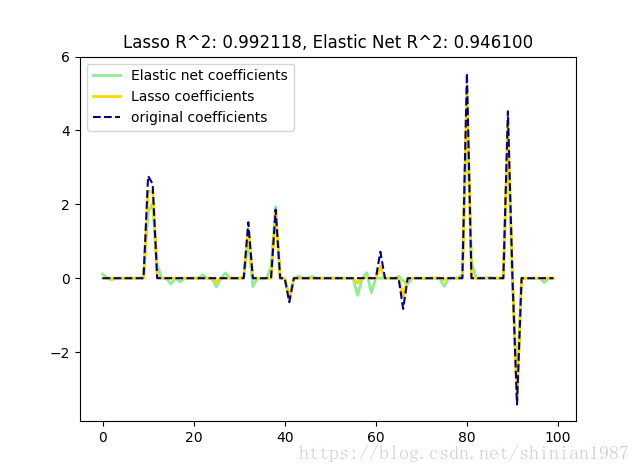
plt.plot(enet.coef_, color='lightgreen', linewidth=2,
label='Elastic net coefficients')
plt.plot(lasso.coef_, color='gold', linewidth=2,
label='Lasso coefficients')
plt.plot(coef, '--', color='navy', label='original coefficients')
plt.legend(loc='best')
plt.title("Lasso R^2: %f, Elastic Net R^2: %f"
% (r2_score_lasso, r2_score_enet))
plt.show()
#########################
**output**:
Lasso(alpha=0.1, copy_X=True, fit_intercept=True, max_iter=1000,
normalize=False, positive=False, precompute=False, random_state=None,
selection='cyclic', tol=0.0001, warm_start=False)
r^2 on test data : 0.992118
ElasticNet(alpha=0.1, copy_X=True, fit_intercept=True, l1_ratio=0.7,
max_iter=1000, normalize=False, positive=False, precompute=False,
random_state=None, selection='cyclic', tol=0.0001, warm_start=False)
r^2 on test data : 0.946100
#########################
scikit-learn 学习笔记-- Generalized Linear Models (二)的更多相关文章
- scikit-learn 学习笔记-- Generalized Linear Models (一)
scikit-learn 是非常优秀的一个有关机器学习的 Python Lib,包含了除深度学习之外的传统机器学习的绝大多数算法,对于了解传统机器学习是一个很不错的平台.每个算法都有相应的例子,既可以 ...
- scikit-learn 学习笔记-- Generalized Linear Models (三)
Bayesian regression 前面介绍的线性模型都是从最小二乘,均方误差的角度去建立的,从最简单的最小二乘到带正则项的 lasso,ridge 等.而 Bayesian regression ...
- Andrew Ng机器学习公开课笔记 -- Generalized Linear Models
网易公开课,第4课 notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf 前面介绍一个线性回归问题,符合高斯分布 一个分类问题,logstic回 ...
- 机器学习-scikit learn学习笔记
scikit-learn官网:http://scikit-learn.org/stable/ 通常情况下,一个学习问题会包含一组学习样本数据,计算机通过对样本数据的学习,尝试对未知数据进行预测. 学习 ...
- [Scikit-learn] 1.1 Generalized Linear Models - from Linear Regression to L1&L2
Introduction 一.Scikit-learning 广义线性模型 From: http://sklearn.lzjqsdd.com/modules/linear_model.html#ord ...
- [Scikit-learn] 1.5 Generalized Linear Models - SGD for Regression
梯度下降 一.亲手实现“梯度下降” 以下内容其实就是<手动实现简单的梯度下降>. 神经网络的实践笔记,主要包括: Logistic分类函数 反向传播相关内容 Link: http://pe ...
- [Scikit-learn] 1.5 Generalized Linear Models - SGD for Classification
NB: 因为softmax,NN看上去是分类,其实是拟合(回归),拟合最大似然. 多分类参见:[Scikit-learn] 1.1 Generalized Linear Models - Logist ...
- [Scikit-learn] 1.1 Generalized Linear Models - Logistic regression & Softmax
二分类:Logistic regression 多分类:Softmax分类函数 对于损失函数,我们求其最小值, 对于似然函数,我们求其最大值. Logistic是loss function,即: 在逻 ...
- 广义线性模型(Generalized Linear Models)
前面的文章已经介绍了一个回归和一个分类的例子.在逻辑回归模型中我们假设: 在分类问题中我们假设: 他们都是广义线性模型中的一个例子,在理解广义线性模型之前需要先理解指数分布族. 指数分布族(The E ...
随机推荐
- centos 相关
运行locate httpd.conf,提示-bash: locate: command not found错误.则需要安装mlocate软件包: yum install mlocate 搜索,提示l ...
- cocos代码研究(17)Widget子类RadioButtonGroup学习笔记
理论基础 RadioButtonGroup可以把指定的单选按钮组织起来, 形成一个组, 使它们彼此交互. 在一个RadioButtonGroup, 有且只有一个或者没有RadioButton可以处于被 ...
- VS2010/MFC编程入门之二十一(常用控件:编辑框Edit Control)
鸡啄米上一节讲了静态文本框,本节要讲的编辑框(Edit Control)同样是一种很常用的控件,我们可以在编辑框中输入并编辑文本.在前面加法计算器的例子中已经演示了编辑框的基本应用.下面具体讲解编辑框 ...
- 两步实现在Git Bash中用Sublime打开文件
每次都要用鼠标点来点去才能用sublime打开文件!太不科学!今天来配置一下在Git bash中用sublime打开文件 方法 新建一个文件命名为你想要的命令,比如 subl(注意不能有后缀名),内容 ...
- Core Java 6
p277~p279: 1.使用解耦合的 try/catch 和 try/finally 语句块可以提高代码的清晰度,并且会报告 finally 子句中出现的错误. 2.假设利用 return 语句从 ...
- Window 常用系统变量
转载:http://www.slyar.com/blog/envionment-variables.html 转载:http://blog.csdn.net/wuliusir/article/deta ...
- mysql绑定参数bind_param原理以及防SQL注入
假设我们的用户表中存在一行.用户名字段为username.值为aaa.密码字段为pwd.值为pwd.. 下面我们来模拟一个用户登录的过程.. <?php $username = "aa ...
- python assert 断言详细用法格式
使用assert断言是学习python一个非常好的习惯,python assert 断言句语格式及用法很简单.在没完善一个程序之前,我们不知道程序在哪里会出错,与其让它在运行最崩溃,不如在出现错误条件 ...
- npm 安装私有 git 包
npm 安装私有 git 包 npm 对于前端开发来说是一种必备的工具,对于开源项目来说,完全没有任何问题,安装包的依赖直接依赖于 Npm 即可. 对于公司内网的一些项目就不是太方便了,因为我们通常会 ...
- 【SQL Server高可用性】数据库复制:SQL Server 2008R2中数据库复制
经常在论坛中看到有人问数据同步的技术,如果只是同步少量的表,那么可以考虑使用链接服务器+触发器,来实现数据同步,但当要同步的数据表比较多,那么可以考虑用数据库复制技术,来实现数据的同步. 一.使用场景 ...