3.Airflow使用
2. 相关概念
2.1 服务进程
2.1.1. web server
2.1.2. scheduler
2.1.3. worker
2.1.4. celery flower
2.2 相关概念
2.2.1. dag
2.2.2.task
2.2.3.Operator
2.2.4 scheduler
2.2.5.worker
2.2.6.executor
2.2.7.Task Instances
2.2.8.pool
2.2.9.connection
2.2.10.Hooks
2.2.11.Queues
2.2.12.XComs
2.2.13.Variables
2.2.14.Branching
2.2.15.SLAs (Service Level Agreements)
2.2.16.Trigger Rules
2.2.17 宏
2.2.18 jinja2
2.2.19 Latest Run Only
3. 命令行
4. API
5. 使用
5.1 创建dag
5.2 示例dag
6. 总结
1. airflow简介
airflow是Airbnb公司于2014年开始开发的一个工作流调度器.不同于其它调度器使用XML或者text文件方式定义工作流,airflow通过python文件作流,用户可以通过代码完全自定义自己的工作流。airflow的主要功能:工作流定义、任务调度、任务依赖、变量、池、分布式执行任务等。
2. 相关概念
2.1 服务进程
2.1.1. web server
web server是airflow的显示与管理工具,在页面中能看到任务及执行情况,还能配置变量、池等
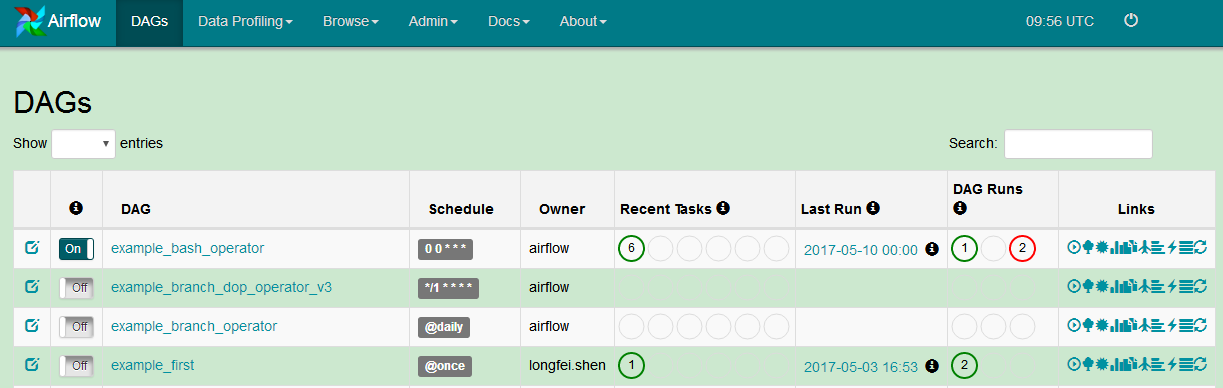
2.1.2. scheduler
调度器用来监控任务执行时间并提交任务给worker执行。在airflow中scheduler做为独立的服务来启动。
2.1.3. worker
工作进程,负责任务的的执行。worker进程会创建SequentialExecutor、LocalExecutor、CeleryExecutor之一来执行任务。在airflow中作为独立服务启动。
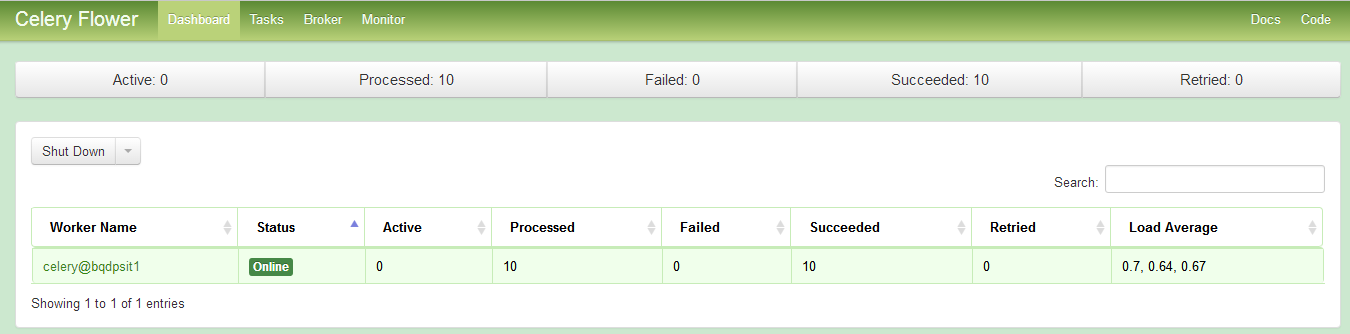
2.1.4. celery flower
celery flower用来监控celery executor的信息。
url:http://host:5555
2.2 相关概念
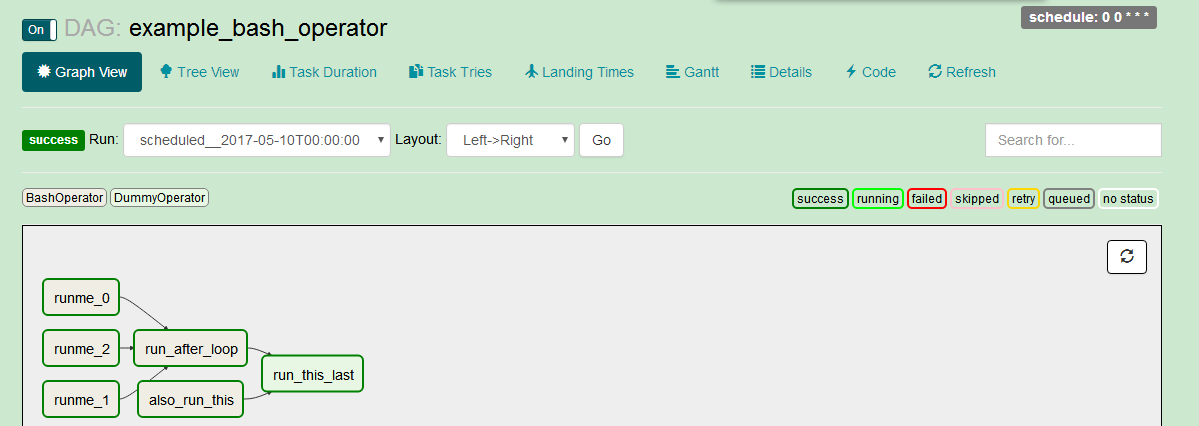
2.2.1. dag
主dag
即有向无图,相当于azkban中的project。dag中定义的了任务类型、任务依赖、调度周期等.dag由task组中,task定义了任务的类型、任务脚本等,dag定义task之间的依赖。airflow中的任务表现为一个个的dag.此外还有subdag,在dag中嵌套一个dag(具体作用需进一步研究)。
subdag
相当于azkban中project 中的flow.将dag中的某些task合并到一个子dag中,将这个子dag做为一个执行单元。
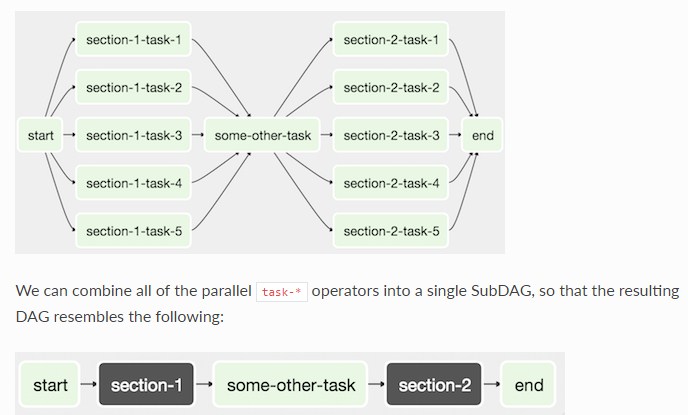
使用subdag时要注意:
1)by convention, a SubDAG’s dag_id should be prefixed by its parent and a dot. As in 'parent.child' 。
引用子dag时要加上父dag前缀,parent.child
2)share arguments between the main DAG and the SubDAG by passing arguments to the SubDAG operator (as demonstrated above)
通过向子dag的operator传入参数来实现在父dag和子dag信息共享。
3)SubDAGs must have a schedule and be enabled. If the SubDAG’s schedule is set to None or @once, the SubDAG will succeed without having done anything
子dag必须要设置scheduler,如果没有设置或者设置为@once,则子dag直接返回执行成功,但是不会执行任务操作
4)clearing a SubDagOperator also clears the state of the tasks within
清除子dag(的状态?)也会清除其中的task状态
5)marking success on a SubDagOperator does not affect the state of the tasks within
将子dag的状态标记为success不会影响所包含的task的状态
6)refrain from using depends_on_past=True! in tasks within the SubDAG as this can be confusing
不要在dag中使用depends_on_past=True!
7)it is possible to specify an executor for the SubDAG. It is common to use the SequentialExecutor if you want to run the SubDAG in-process and effectively limit its parallelism to one. Using LocalExecutor can be problematic as it may over-subscribe your worker, running multiple tasks in a single slot
使用SequentialExecutor来运行子dag,其它的executor执行子dag会出问题
2.2.2.task
task定义任务的类型、任务内容、任务所依赖的dag等。dag中每个task都要有不同的task_id.
dag = DAG('testFile', default_args=default_args)
# t1, t2 and t3 are examples of tasks created by instantiating operators
t1 = BashOperator( #任务类型是bash
task_id='echoDate', #任务id
bash_command='echo date > /home/datefile', #任务命令
dag=dag)
t2 = BashOperator(
task_id='sleep',
bash_command='sleep 5',
retries=3,[]()
dag=dag)
t2.set_upstream(t1) #定义任务信赖,任务2依赖于任务1任务之间通过task.set_upstream\task.set_downstream来设置依赖,也可以用位运算:
t1>>t2<<t3 表示t2依赖于t1和t3.不建议用该种方式。
2.2.3.Operator
操作器,定义任务该以哪种方式执行。airflow有多种operator,如BashOperator、DummyOperator、MySqlOperator、HiveOperator以及社区贡献的operator等,其中BaseOperator是所有operator的基础operator。
| BaseOperator | 基础operator,设置baseoperator会影响所有的operator |
| BashOperator | executes a bash command |
| DummyOperator | 空操作 |
| PythonOperator | calls an arbitrary Python function |
| EmailOperator | sends an email |
| HTTPOperator | sends an HTTP request |
| SqlOperator | executes a SQL command |
| Sensor | waits for a certain time, file, database row, S3 key, etc… |
t1 = BashOperator( #任务类型是bash
task_id='echoDate', #任务id
bash_command='echo date > /home/datefile', #任务命令
dag=dag)2.2.4 scheduler
scheduler监控dag的状态,启动满足条件的dag,并将任务提交给具体的executor执行。dag通过scheduler来设置执行周期。
1.何时执行
注意:当使用schedule_interval来调度一个dag,假设执行周期为1天,startdate=2016-01-01,则会在2016-01-01T23:59后执行这个任务。 airflow只会在执行周期的结尾执行任务。
2.设置dag执行周期
在dag中设置schedule_interval来定义调度周期。该参数可以接收cron 表达式和datetime.timedelta对象,另外airflow还预置了一些调度周期。
| preset | Run once a year at midnight of January 1 | cron |
|---|---|---|
None |
Don’t schedule, use for exclusively “externally triggered” DAGs | |
@once |
Schedule once and only once | |
@hourly |
Run once an hour at the beginning of the hour | 0 * * * * |
@daily |
Run once a day at midnight | 0 0 * * * |
@weekly |
Run once a week at midnight on Sunday morning | 0 0 * * 0 |
@monthly |
Run once a month at midnight of the first day of the month | 0 0 1 * * |
@yearly |
Run once a year at midnight of January 1 | 0 0 1 1 * |
3.backfill和catchup
backfill:填充任务,手动重跑过去失败的任务(指定日期)。
catchup:如果历史任务出错,调度器尝试按调度顺序重跑历史任务(而不是按照当前时间执行当前任务)。可以在dag中设置dag.catchup = False或者参数文件中设置catchup_by_default = False来禁用这个功能。
4.External Triggers
我还没整明白(等我翻下书再告诉你啊~)
2.2.5.worker
worker指工作节点,类似于yarn中的nodemanager。work负责启动机器上的executor来执行任务。使用celeryExecutor后可以在多个机器上部署worker服务。
2.2.6.executor
执行任务的进程,dag中的task由executor来执行。有三个executor:SequentialExecutor(顺序执行)、LocalExecutor(本地执行)、CeleryExecutor(远程执行)。
2.2.7.Task Instances
dag中被实例化的任务。
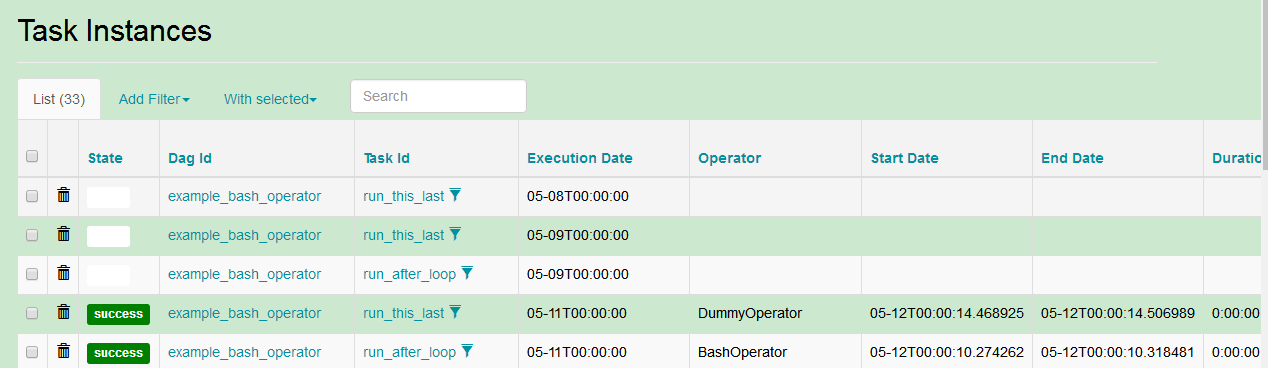
2.2.8.pool
池用来控制同个pool的task并行度。
aggregate_db_message_job = BashOperator(
task_id='aggregate_db_message_job',
execution_timeout=timedelta(hours=3),
pool='ep_data_pipeline_db_msg_agg',
bash_command=aggregate_db_message_job_cmd,
dag=dag)
aggregate_db_message_job.set_upstream(wait_for_empty_queue)上例中,aggregate_db_message_job设置了pool,如果pool的最大并行度为1,当其它任务也设置该池时,如果aggregate_db_message_job在运行,则其它任务必须等待。
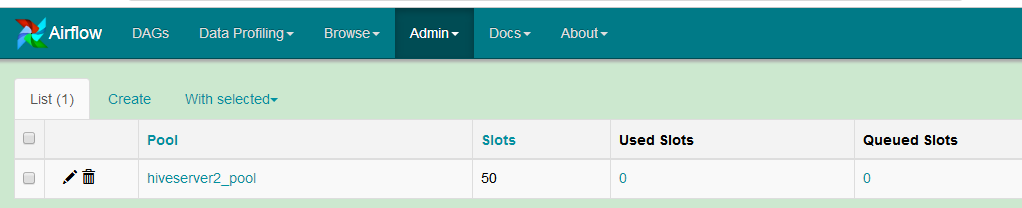
2.2.9.connection
定义对airflow之外的连接,如对mysql hive hdfs等工具的连接。airflow中预置了一些连接类型,如mysql hive hdfs postgrey等。
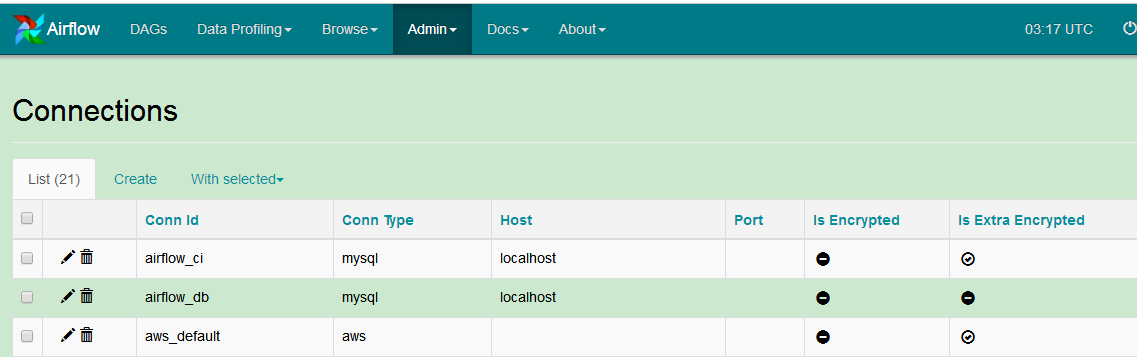
2.2.10.Hooks
Hooks 是对外的connection接口,通过自定义hooks实现connection中不支持的连接。
2.2.11.Queues
airflow中的队列严格来说不叫Queues,叫"lebal"更为合适。在operator中,可以设置queue参数如queue=spark,然后在启动worker时:airflow worker -q spark,那么该worker只会执行spark任务。相当于节点标签。、
2.2.12.XComs
默认情况下,dag与dag之间 、task与task之间信息是无法共享的。如果想在dag、task之间实现信息共享,要使用XComs,通过设置在一个dag(task)中设置XComs参数在另一个中读取来实现信息共享。
2.2.13.Variables
在airflow中可以设置一些变量,在dag和task中可以引用这些变量:
from airflow.models import Variable
foo = Variable.get("foo")
bar = Variable.get("bar", deserialize_json=True)设置变量:
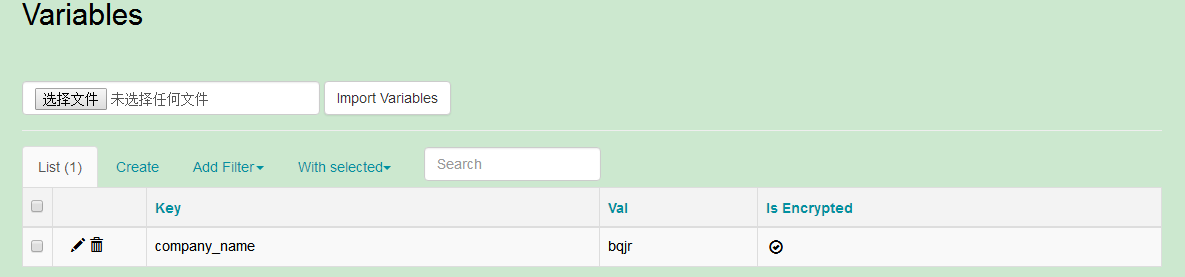
此外,airflow预置了一些变量:

具体参考:http://airflow.incubator.apache.org/code.html#macros
2.2.14.Branching
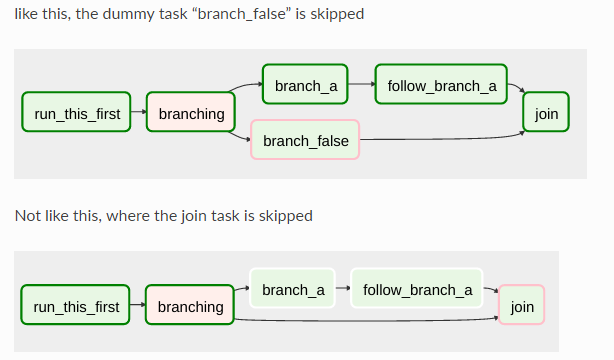
dag中的任务可以选择分支! BranchPythonOperator允许用户通过函数返回下一步要执行的task的id,从而根据条件选择执行的分支。azkaban没有该功能。注意,BranchPythonOperator下级task是被"selected"或者"skipped"的分支。
2.2.15.SLAs (Service Level Agreements)
SLAs指在一段时间内应该完全的操作,比如在一个小时内dag应该执行成功,如果达不目标可以执行其它任务比如发邮件发短信等。
2.2.16.Trigger Rules
Trigger Rules定义了某个task在何种情况下执行。默认情况下,某个task是否执行,依赖于其父task(直接上游任务)全部执行成功。airflow允许创建更复杂的依赖。通过设置operator中的trigger_rule参数来控制:
all_success: (default) all parents have succeeded 父task全failedall_failed: all parents are in afailedorupstream_failedstate 父task全failed或者upstream_failed状态all_done: all parents are done with their execution 父task全执行过,不管success or failedone_failed: fires as soon as at least one parent has failed, it does not wait for all parents to be done 当父task中有一个是failed状态时执行,不必等到所有的父task都执行one_success: fires as soon as at least one parent succeeds, it does not wait for all parents to be done 当父task中有一个是success状态时执行,不必等到所有的父task都执行dummy: dependencies are just for show, trigger at will 无条件执行
该参数可以和depends_on_past结合使用,当设置为true时,如果上一次没有执行成功,这一次无论如何都不会执行。
2.2.17 宏
airflow中内置了一些宏,可以在代码中引用。
通用宏:

airflow特定的宏:
| airflow.macros.ds_add(ds, days) |
| airflow.macros.ds_format(ds, input_format, output_format) |
| airflow.macros.random() → x in the interval [0, 1) |
| airflow.macros.hive.closest_ds_partition(table, ds, before=True, schema='default', metastore_conn_id='metastore_default') |
| airflow.macros.hive.max_partition(table, schema='default', field=None, filter=None, metastore_conn_id='metastore_default') |
详细说明:
http://airflow.incubator.apache.org/code.html#macros
2.2.18 jinja2
airflow支持jinja2语法。Jinja2是基于python的模板引擎,功能比较类似于于PHP的smarty,J2ee的Freemarker和velocity。关于jinja2:
http://10.32.1.149:7180/cmf/login
2.2.19 Latest Run Only
这个太复杂,待近一步研究
3. 命令行
airflow命令的语法结构:
airflow 子命令 [参数1][参数2]….
如 airflow test example_dag print_date 2017-05-06
子命令
子命令包括:
resetdb
Burn down and rebuild the metadata database
render
Render a task instance’s template(s)
variables
CRUD operations on variables
connections
List/Add/Delete connections
pause
Pause a DAG
task_failed_deps
Returns the unmet dependencies for a task instance from the perspective of the scheduler
version
Show the version
trigger_dag
Trigger a DAG run
initdb
Initialize the metadata database
test
Test a task instance. This will run a task without checking for dependencies or recording it’s state in the database.
unpause
Resume a paused DAG
dag_state
Get the status of a dag run
run
Run a single task instance
list_tasks
List the tasks within a DAG
backfill
Run subsections of a DAG for a specified date range
list_dags
List all the DAGs
kerberos
Start a kerberos ticket renewer
worker
Start a Celery worker node
webserver
Start a Airflow webserver instance
flower
Start a Celery Flower
scheduler
Start a scheduler instance
task_state
Get the status of a task instance
pool
CRUD operations on pools
serve_logs
Serve logs generate by worker
clear
Clear a set of task instance, as if they never ran
upgradedb
Upgrade the metadata database to latest version
airflow命令的语法结构:
airflow 子命令 [参数1][参数2]….
如 airflow test example_dag print_date 2017-05-06
子命令
子命令包括:
| resetdb | Burn down and rebuild the metadata database |
| render | Render a task instance’s template(s) |
| variables | CRUD operations on variables |
| connections | List/Add/Delete connections |
| pause | Pause a DAG |
| task_failed_deps | Returns the unmet dependencies for a task instance from the perspective of the scheduler |
| version | Show the version |
| trigger_dag | Trigger a DAG run |
| initdb | Initialize the metadata database |
| test | Test a task instance. This will run a task without checking for dependencies or recording it’s state in the database. |
| unpause | Resume a paused DAG |
| dag_state | Get the status of a dag run |
| run | Run a single task instance |
| list_tasks | List the tasks within a DAG |
| backfill | Run subsections of a DAG for a specified date range |
| list_dags | List all the DAGs |
| kerberos | Start a kerberos ticket renewer |
| worker | Start a Celery worker node |
| webserver | Start a Airflow webserver instance |
| flower | Start a Celery Flower |
| scheduler | Start a scheduler instance |
| task_state | Get the status of a task instance |
| pool | CRUD operations on pools |
| serve_logs | Serve logs generate by worker |
| clear | Clear a set of task instance, as if they never ran |
| upgradedb | Upgrade the metadata database to latest version |
使用:
[bqadm@sitbqbm1~]$ airflow webserver -p 8080详细命令参考:
http://airflow.incubator.apache.org/cli.html#
4. API
airflow的api分为Operator、Macros、Modles、Hooks、Executors几个部分,主要关注Operator、Modles这两部分
详细API文档:
http://airflow.incubator.apache.org/code.html
5. 使用
5.1 创建dag
1.创建一个pthon文件testBashOperator.py:
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'yangxw',
'depends_on_past': False,
'start_date': datetime(2017, 5, 9),
'email': ['xiaowen.yang@bqjr.cn'],
'email_on_failure': True,
'email_on_retry': True,
'retries': 1,
'retry_delay': timedelta(minutes=5),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
}
dag = DAG('printDate', default_args=default_args,schedule_interval='*/1 * * * *')
# t1, t2 and t3 are examples of tasks created by instantiating operators
t1 = BashOperator(
task_id='datefile',
bash_command='date > /home/bqadm/datefile',
dag=dag)
t2 = BashOperator(
task_id='sleep',
bash_command='sleep 5',
retries=3,
dag=dag)
t2.set_upstream(t1)
2.编译该文件
把文件放到$AIRFLOW_HIME/dags下,然后执行:
[bqadm@bqdpsit1 dags]$ python testFile.py
[2017-05-18 10:04:17,422] {__init__.py:57} INFO - Using executor CeleryExecutor这样dag就被创建了
3.启动dag
在web上,点击最左边按钮,将off切换为on

这样dag就启动了。dag启后,会根据自生的调度情况执行。上列中的dag每分钟执行一次,将时间写入/home/bqadm/datafile里。
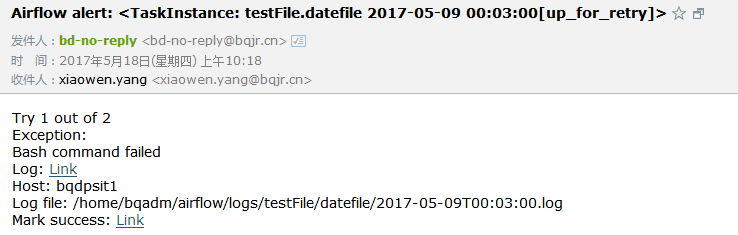
如果执行出错还会发邮件通知:
5.2 示例dag
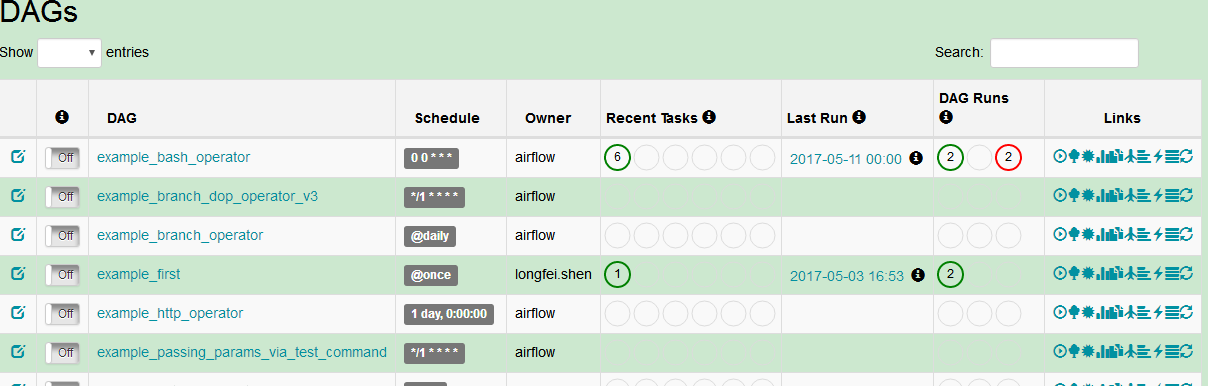
airflow内置了16个示例dag,通过学习这些dag的源码可掌握operator、调度、任务依赖的知识,能快速入门。
6. 总结
airflow是功能强大并且极其灵活的pipeline工具,通过python脚本能控制ETL中各个环节,其缺点是使用比较复杂,需要一定的编程水平。此外,当一个dag中有数十个task时,python文件将变的非常长导致维护不便。airflow在国内并未广泛使用,面临一定的技术风险。
3.Airflow使用的更多相关文章
- 灵活可扩展的工作流管理平台Airflow
1. 引言 Airflow是Airbnb开源的一个用Python写就的工作流管理平台(workflow management platform).在前一篇文章中,介绍了如何用Crontab管理数据流, ...
- airflow 优化
1. 页面默认加载数据过多,加载慢. 修改 .../python2.7/site-packages/airflow/www/views.py文件, 1823行, page_size参数, 比如改成18 ...
- airflow 部署
环境 : ubuntu 14.04 LTS python 2.7 script: 设置环境变量: export AIRFLOW_HOME=~/airflow 安装相关依赖包: sudo apt-get ...
- 系统研究Airbnb开源项目airflow
开源项目airflow的一点研究 调研了一些几个调度系统, airflow 更满意一些. 花了些时间写了这个博文, 这应该是国内技术圈中最早系统性研究airflow的文章了. 转载请注明出处 htt ...
- Airflow Comman Line 测试
官网文档:https://incubator-airflow.readthedocs.io/en/latest/cli.html clear (1)clear 指定日期某一个dag下的任务,任务名可以 ...
- Airflow 重跑dag中部分失败的任务
重跑dag中部分失败的任务 例如 dagA 中, T1 >> T2 >> T3 >> T4 >> T5 ,其中 T1 T2 成功, T3 失败, T4 ...
- airflow 笔记
首先是一个比较好的英文网站,可能要fq:http://site.clairvoyantsoft.com/installing-and-configuring-apache-airflow/ ===== ...
- Airflow Python工作流引擎的重要概念介绍
Airflow Python工作流引擎的重要概念介绍 - watermelonbig的专栏 - CSDN博客https://blog.csdn.net/watermelonbig/article/de ...
- 【原创】大数据基础之Airflow(1)简介、安装、使用
airflow 1.10.0 官方:http://airflow.apache.org/ 一 简介 Airflow is a platform to programmatically author, ...
- 【原创】大数据基础之Ambari(3)通过Ambari部署Airflow
ambari2.7.3(hdp3.1) 安装 airflow1.10 ambari的hdp中原生不支持airflow安装,下面介绍如何通过mpack方式使ambari支持airflow安装: 1 下载 ...
随机推荐
- Xcode 提交APP时遇到 “has one iOS Distribution certificate but its private key is not installed”
解决办法:登录Apple开发证书后台,把发布版证书.cer文件下载到本地,双击安装即可.若还没有设置发布证书文件,则创建一个后下载. Ref: https://blog.csdn.net/dingqk ...
- 多线程编程初探——OO第二单元作业回顾
一.作业设计策略 1)执行FAFS策略的单部电梯 由于对多线程不是很了解,于是采用了理论课上介绍的生产者消费者模型作为设计模板(也是很多同学一开始的做法):将请求队列作为共享对象(托盘),名为In ...
- JBDC—③数据库连接池的介绍、使用和配置
首先要知道数据库连接(Connection对象)的创建和关闭是非常浪费系统资源的,如果是使用常规的数据库连接方式来操作数据库,当用户变多时,每次访问数据库都要创建大量的Connnection对象,使用 ...
- python散记
1.AOP 将不同的类的内部中雷同的代码和重复的功能,提取出来以重用. 装饰器是一个很著名的设计模式,经常被用于有切面需求的场景,较为经典的有插入日志.性能测试.事务处理等 2.新式类,经典类 新式类 ...
- Python学习 :面向对象(一)
面向对象 一.定义 面向对象:面向对象为类和对象之间的应用 class + 类名: #在类中的函数称作 “方法“ def + 方法名(self,arg): #方法中第一个参数必须是 self prin ...
- Linux CentOS Python开发环境搭建教程
CentOS安装Python 1.CentOS已经自带安装了2.x版本,先尝试python命令检查已安装的版本.如果你使用rpm.yum或deb命令安装过,请使用相对命令查询. 2.复制安装文件链 ...
- 理解 ajax、fetch和axios
背景 ajax fetch.axios 优缺点 ajax基于jquery,引入时需要引入庞大的jquery库,不符合当下前端框架,于是fetch替代了ajax 由于fetch是比较底层,需要我们再次封 ...
- 20155211 2016-2017-2 《Java程序设计》第一周学习总结
20155211 2006-2007-2 <Java程序设计>第1周学习总结 教材学习内容总结 首先根据博客上的指导安装了jdk,并且首次尝试了设置环境变量path和classpath. ...
- 20155216 2016-2017-2 《Java程序设计》第九周学习总结
20155216 2016-2017-2 <Java程序设计>第九周学习总结 教材学习内容总结 JDBC架构 JDBC API的使用 JDBC连接数据库 1.导入JDBC包: 添加impo ...
- 20155327 学习基础和C语言基础调查
20155327 学习基础和C语言基础调查 通过阅读老师推荐的五篇文章之后,其中有几个点引发了我的思考,便是"量变引起质变""循序渐进"以及"坚持&q ...