mysql 基础整合大全
mysql 数据库操作:
创建数据库:
create database db_sanguo charset utf8;
切进db_sanguo
use db_sanguo
删除数据库:
drop database db_sanguo;
数据表的增删:
建表
create table t_hero(
id int unsigned auto_increment primary key,
name varchar(10) unique not null,
age tinyint unsigned default 0,
gender set("男", "女"),
state varchar(10)
);
查看表结构 desc t_hero;
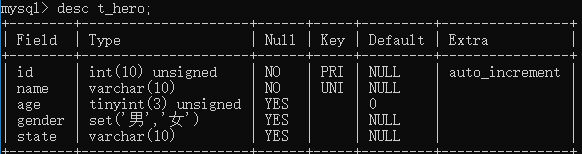
或:

MySQL的数据类型
MySQL的数据类型 分为四大类型: 整数和浮点数类型、时间和日期类型、字符串类型、二进制类型。
一、整数与浮点数类型
1. 整数类型:
| 类型名 | 字节 | 无符号(unsigned)取值范围 | 有符号(signed)取值范围(默认) |
|---|---|---|---|
| TINYINT | 1 | 0~255 | -128~127 |
| SMALLINT | 2 | 0~65535 | -32768 ~ 32767 |
| MEDIUMINT | 3 | 0~16777215 | -8388608 ~ 8388607 |
| INT | 4 | 0~4294967295 | -2147483648 ~ 2147483647 |
| INTEGER | 4 | 0~4294967295 | -2147483648 ~ 2147483647 |
| BIGINT | 8 | 0~18446744073709551615 | -9223372036854775808 ~ 9223372036854775807 |
2. 浮点数类型和精准数据类型:
| 类型名 | 字节 | 无符号(unsigned)取值范围 | 有符号(signed)取值范围(默认) |
|---|---|---|---|
| FLOAT | 4 | 0, 1.175494351E-38 ~3.402823466E+38 | -3.402823466E+38 ~1.175494351E-38, 0, 1.175494351E-38 ~ 3.402823466E+38 |
| DOUBLE | 8 | 2.2250738585072014E-308 ~ 1.7976931348623157E-308 | -1.7976931348623157E+308 ~ 2.2250738585072014E-308, 0, 2.2250738585072014E-308 ~ 1.7976931348623157E+308 |
| DECIMAL(M,D) | M+2 | 同 Double | 同 Double |
注意:DECIMAL(M, D) 精准数据类型:
M表示:数据的有效总长度(不包括小数点);D表示:小数位精度,按四舍五入计算如果使用时没有指定参数,则默认参数为 (10, 0)
二、日期和时间类型
| 类型名 | 字节 | 取值范围 | 零值 |
|---|---|---|---|
| YEAR | 1 | 1910~2155 | 0000 |
| DATE | 4 | 1000-01-01~9999-12-31 | 0000:00:00 |
| TIME | 3 | -838:59:59~838:59:59 | 00:00:00 |
| DATETIME | 8 | 1000-01-01 00:00:00 ~9999-12-31 23:59:59 | 0000-00-00 00:00:00 |
| TIMESTAMP | 4 | 19700101080001~20380119111407 | 00000000000000 |
三、字符串类型
| 类型名 | 说明 |
|---|---|
| CHAR | 固定长度字符串 |
| VARCHAR | 可变长度字符串 |
| TEXT | 大文本(TINYTEXT,TEXT,MEDIUMTEXT,LONGTEXT) |
| ENUM | 枚举类型(只能取一个元素) |
| SET | 集合类型(能取多个元素) |
四、二进制类型
| 类型名 | 说明 |
|---|---|
| BINARY(M) | 字节数为 M,允许长度为 0~M 的定长二进制字符串 |
| VARBINARY(M) | 允许长度为 0~M 的变长二进制字符串,字节数为值的长度加 1 |
| BIT(M) | M 位二进制数据,最多 255 个字节 |
| TINYBLOB | 可变长二进制数据,最多 255 个字节 |
| BLOB | 可变长二进制数据,最多(2 16 -1)个字节 |
| MEDIUMBLOB | 可变长二进制数据,最多(2 24 -1)个字节 |
| LONGBLOB | 可变长二进制数据,最多(2 32 -1)个字节 |
总结:
- MySQL支持所有标准SQL数值数据类型
- 可以通过查看帮助文档查阅所有支持的数据类型
- 使用数据类型的原则是:够用就行,尽量使用取值范围小的,而不用大的,这样可以更多的节省存储空间
- 特别说明的类型如下:
- decimal表示浮点数,如decimal(5,2)表示共存5位数,小数占2位
- 字符串:char,varchar
- char表示固定长度的字符串,如char(3),如果填充'ab'时会补一个空格为'ab '
- varchar表示可变长度的字符串,如varchar(3),填充'ab'时就会存储'ab'
- 字符串text表示存储大本,当字符大于4000时推荐使用
- 对于图片、音频、视频等文件,不存储在数据库中,而是上传到某个服务器上,然后在表中存储这个文件的保存路径
- mysql支持枚举类型enum,但是enum的本质是tinyint类型,所以推荐使用tinyint类型而不用enum类型
约束
约束是在表中定义的用于维护数据库完整性的一些规则,通过为表中的列定义约束可以防止将错误的数据插入表中,也可以保持表之间数据的一致性。
| 约束条件 | 说明 |
|---|---|
| NOT NULL | 标识该属性不能为空 |
| UNIQUE | 标识该属性的值是唯一的 |
| AUTO_INCREMENT | 标识该属性的值自动增加 |
| DEFAULT | 为该属性设置默认值,当不填写此值时会使用默认值,如果填写则以填写为准 |
PRIMARY KEY |
标识该属性为该表的主键,能确定一条记录的唯一标识(满足第二范式) |
FOREIGN KEY |
标识该属性为该表的外键,与某表的主键关联。如果一个表中的某一列是另外一个表的中的主键,那么设置这列为外键。 |
数据表数据插入,
insert into t_hero(name, age, gender, state) values("曹操","","男","魏");
insert into t_hero(name, age, gender, state) values("刘备","","男","蜀");
insert into t_hero(name, age, gender, state) values("孙权","","男","吴");
insert into t_hero(name, age, gender, state) values("诸葛亮","","男","蜀");
insert into t_hero(name, age, gender, state) values("司马懿","","男","魏");
insert into t_hero(name, age, gender) values("貂蝉","","女");
insert into t_hero(name, age, gender) values("吕布","","男");
insert into t_hero(name, age, gender) values("小乔","","女");
insert into t_hero(name, age, gender, state) values("关羽","","男","蜀");
insert into t_hero(name, gender, state) values("孙尚香","女","吴");
insert into t_hero(name, age, gender, state) values("张飞","","男","蜀");
insert into t_hero(name, gender, state) values("小张飞","男","吴");
insert into t_hero(name, age, gender, state) values("小张飞儿","","男","蜀");
insert into t_hero(name, age, state) values("张小飞儿","","蜀");
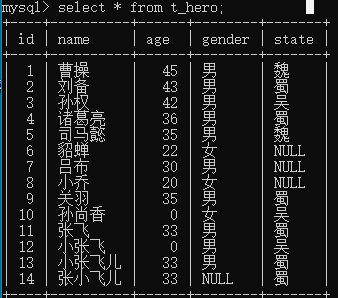
数据表结构的增删改查
增:
语法: alter table 表名 add 字段名 类型 约束;
alter table t_hero add address varchar(10);
更改字段名称:
语法: alter table 表名 change 旧字段 新字段 类型 约束;
alter table t_hero change address adds varchar(10);
修改类型或约束:
语法: alter table 表名 modify 字段 类型 约束;
alter table t_hero modify adds int;
删除字段:
语法: alter table 表名 drop 字段;
alter table t_hero drop adds;
删除数据表:
语法:delete from 表名
数据的增删改查,
增:
全列插入:值的顺序与表中字段的顺序对应(说明:主键列是自动增长,但是在全列插入时需要占位,通常使用0,插入成功后以实际数据为准)
语法:insert into 表名 values(...)
insert into students values(0,'郭靖',1,'蒙古','2015-1-2');
部分列插入:值的顺序与给出的列顺序对应语法:insert into 表名(列1,...) values(值1,...)
insert into students(name,hometown,birthday) values('黄蓉','桃花岛','2015-3-2');
注:上面的语句一次可以向表中插入一行数据,还可以一次性插入多行数据,这样可以减少与数据库的通信全列多行插入:值的顺序与给出的列顺序对应语法:insert into 表名 values(...),(...)...;
insert into classes values(0,'python'),(0,'linux'),(0,'mysql'),(0,'js');
还可以:
语法:insert into 表名(列1,...) values(值1,...),(值1,...)...;
insert into students(name) values('杨康'),('杨过'),('小龙女');
改:
语法:update 表名 set 列1=值1,列2=值2... where 条件
update t_hero set name='孙悟空' where id=14;
注:没有where条件 则代表修改全部
删:
语法:delete from 表名 where 条件
delete from t_hero where id=14;
注:没有where条件 则代表删除全部
另外一种删除全部数据的方法,TRUNCATE
truncate table 你的表名
注:这样不但将数据全部删除,而且重新定位自增的字段查:
在进行后面的操作之前我们先建立一个新的数据表student2,如下:
CREATE TABLE student2(
id INT(3) PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
grade FLOAT,
gender CHAR(2));
INSERT INTO student2(name,grade,gender) VALUES ('songjiang',40,'男'),('wuyong',100,'男'),('qinming',90,'男'),('husanniang',88,'女'),('sunerniang',66,'女'),('wusong',86,'男'),('linchong',92,'男'),('yanqing',90,NULL);
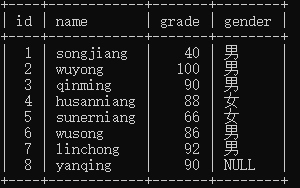
1,查询指定的字段
语法:SELECT 字段名1,字段名2,… FROM 表名;
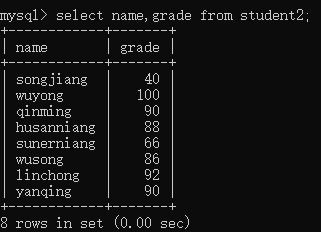
2,查询所有的字段
语法:SELECT * FROM 表名;
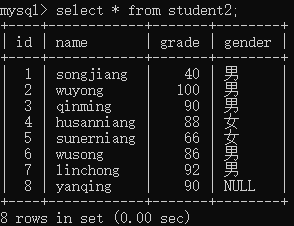
3,按条件查询
1,带关系运算符的查询
语法:SELECT 字段名1,字段名2,…
FROM 表名
WHERE 条件表达式
在WHERE子句中可以使用如下关系运算符:
| 关系运算符 | 说 明 |
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
举例:查询student2表中id为4的人的id和name字段
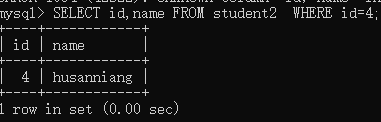 ,
,
2,带 IN 关键字的查询
N关键字用于判断某个字段的值是否在指定集合中,若在,则该字段所在的记录将会被查询出来.
语法:SELECT * | 字段名1,字段名2,…
FROM 表名
WHERE 字段名 [ NOT ] IN (元素1,元素2,…)
举例:查询student2表中id值为1,2,3的记录
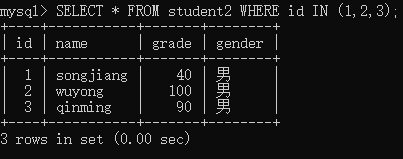
注意:NOT IN 与 IN 相反,查询的是不在指定范围内的记录
3,带 BETWEEN AND 关键字的查询
BETWEEN AND 用于判断某个字段的值是否在指定范围之内,若在,则该字段所在的记录会被查询出来,反之不会。
语法:SELECT * | { 字段名1,字段名2,… }
FROM 表名
WHERE 字段名 [ NOT ] BETWEEN 值1 AND 值2;
举例:查询student2表中id值在2~5之间的人的id和name
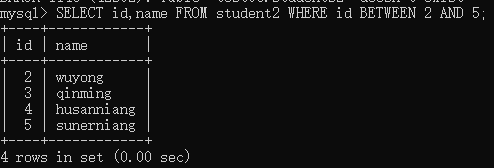
注意:NOT BETWEEN AND 表示查询指定范围外的记录。
4,空值查询
在数据表中有些值可能为空值(NULL),空值不同于0,也不同于空字符串,需要使用 IS NULL 来判断字段的值是否为空值。
语法:SELECT * | 字段名1,字段名2,…
FROM 表名
WHERE 字段名 IS [ NOT ] NULL
举例:查询student2表中gender值为空值的记录。
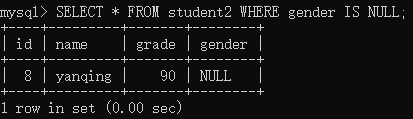
注意:IS NOT NULL 关键字用来查询字段不为空值的记录。
5,带 DISTINCT 关键字的查询
很多表中某些字段的数据存在重复的值,可以使用DISTINCT关键字来过滤重复的值,只保留一个值。
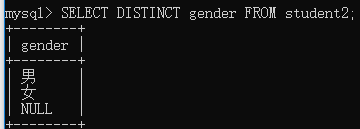
语法:SELECT DISTINCT 字段名 FROM 表名;
举例:查询student2表中gender字段的值,结果中不允许出行重复的值。
6,带link关键字查询
语法:SELECT * | 字段名1,字段名2,…
FROM 表名
WHERE 字段名 [ NOT ] LIKE ‘匹配字符串’;
1)百分号(%)通配符
匹配任意长度的字符串,包括空字符串。例如,字符串“ c% ”匹配以字符 c 开始,任意长度的字符串,如“ ct ”,“ cut ”,“ current ”等;字符串“ c%g ”表示以字符 c 开始,以 g 结尾的字符串;字符串“ %y% ”表示包含字符“ y ”的字符串,无论“ y ”在字符串的什么位置。
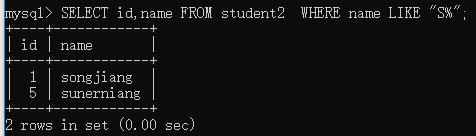
举例1:查询student2表中name字段以字符“ s ”开头的人的id,name
2)下划线(_)通配符
下划线通配符只匹配单个字符,若要匹配多个字符,需要使用多个下划线通配符。例如,字符串“ cu_ ”匹配以字符串“ cu ”开始,长度为3的字符,如“ cut ”,“ cup ”;字符串“ c__l”匹配在“ c ”和“ l ”之间包含两个字符的字符串,如“ cool ”。需要注意的是,连续的“_”之间不能有空格,例如“M_ _QL”只能匹配“My SQL”,不能匹配“MySQL”。
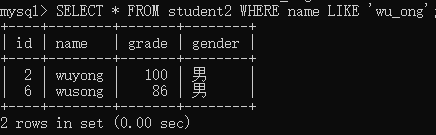
举例:查询在student2表中name字段值以“ wu ”开始,以“ ong ”结束,并且中间只有一个字符的记录。
7,带 AND 关键字的多条件查询
在使用SELECT语句查询数据时,优势为了使查询结果更加精确,可以使用多个查询条件,如使用 AND 关键字可以连接两个或多个查询条件。
语法:SELECT * | 字段名1,字段名2,…
FROM 表名
WHERE 条件表达式1 AND 条件表达式2 [ … AND 条件表达式 n ];
举例:查询student2表中 id 字段小于5,并且 gender 字段值为“ 女 ”的人的id和name
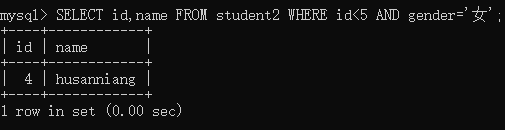
8,带 OR 关键字的多条件查询
与 AND 关键字不同,OR 关键字只要满足任意一个条件就会被查询出来
语法:SELECT * | 字段名1,字段名2,…
FROM 表名
WHERE 条件表达式1 OR 条件表达式2 [ … OR 条件表达式 n ];
举例:查询student2表中 id 字段小于3,或者 gender 字段值为“ 女 ”的人的id,name和gender
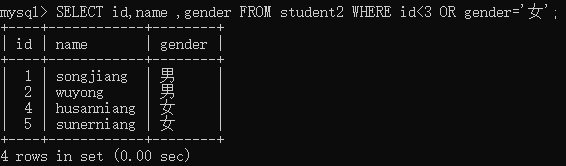
9 OR 和 AND 一起使用的情况
OR 和 AND 一起使用的时候,AND 的优先级高于 OR,因此二者一起使用时,会先运算 AND 两边的表达式,再运算 OR 两边的表达式。
举例:查询student2表中gender值为“女”或者gender值为“男”并且grade字段值为100的人的记录

3 高级查询
1,聚合查询
| 函数名称 | 作用 |
| COUNT() | 返回某列的行数 |
| SUM() | 返回某列值的和 |
| AVG() | 返回某列的平均值 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
1) COUNT()函数:统计记录的条数
语法:SELECT COUNT(*) FROM 表名
举例:查询student2表中一共有多少条记录
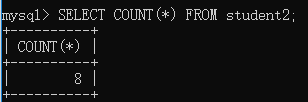
2) SUM()函数:求出表中某个字段所有值的总和
语法:SELECT SUM(字段名) FROM 表名;
举例:求出student2表中grade字段的总和
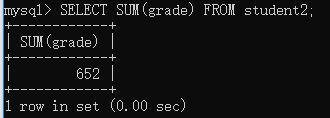
......其它几个函数用法一样,在这里我就不一一列举了
2,排序查询
语法:SELECT 字段名1,字段名2,…
FROM 表名
ORDER BY 字段名1 [ ASC | DESC ],字段名2 [ ASC | DESC ]…
在该语法中指定的字段名是对查询结果进行排序的依据,ASC表示升序排列,DESC 表示降序排列,默认情况是升序排列。
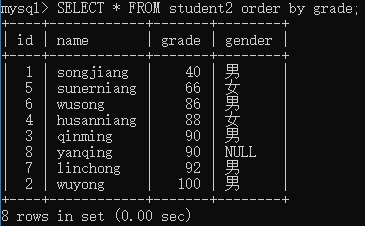
举例1:查出student2表中的所有记录,并按照grade字段进行升序排序
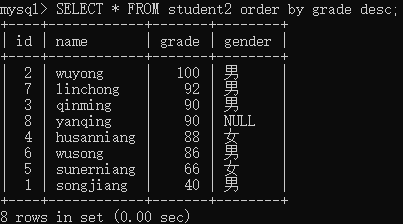
或者倒序
2,分组查询
在对表中数据进行统计的时候,可以使用GROUP BY 按某个字段或者多个字段进行分组,字段中值相同的为一组,如男生分为一组,女生分为一组。
语法:SELECT 字段名1,字段名2,…
FROM 表名
GROUP BY 字段名1,字段名2,… [ HAVING 条件表达式 ];
1) 单独使用 GROUP BY 进行分组
单独使用GROUP BY 关键字,查询的是每个分组中的一条记录
举例:查询student2表中的数据,按照gender字段进行分组。

2) GROUP BY 和聚合函数一起使用
GROUP BY 和聚合函数一起使用,可以统计出某个或者某些字段在一个分组中的最大值、最小值、平均值等。
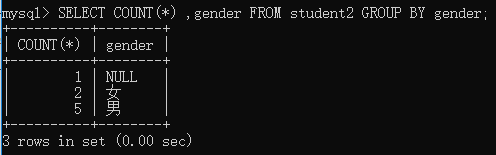
举例:将student2表按照gender字段进行分组查询,计算出每组共有多少个人。
3)GROUP BY 和 HAVING 关键字一起使用
HAVING关键字和WHERE关键字的作用相同,区别在于HAVING 关键字可以跟聚合函数,而WHERE 关键字不能。通常HAVING 关键字都和GROUP BY一起使用,用于对分组后的结果进行过滤。
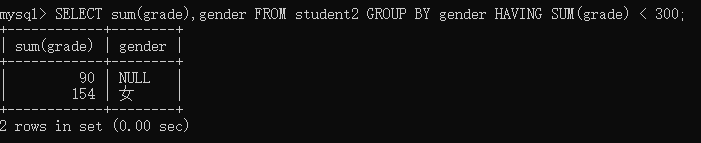
举例:将student2表按照gender字段进行分组查询,查询出grade字段值之和小于300的分组
3 使用 LIMIT 限制查询结果的数量
SELECT 字段名2,字段名2,…
FROM 表名
LIMIT [ OFFSET ,] 记录数
在此语法中,LIMIT 后面可以跟两个参数,第一个参数“ OFFSET ”表示偏移量,如果偏移量为0,则从查询结果的第一条记录开始,偏移量为1则从查询结果中的第二条记录开始,以此类推。OFFSET为可选值,默认值为0,第二个参数“记录数”表示指定返回查询记录的条数。
举例1:查询student2表中的前四条记录。

举例2:查询student2表中grade字段从第五位到第八位的人(从高到低)

4 为表和字段取别名
1)为表起别名
在进行查询操作时,如果表名很长使用起来不方便,可以为表取一个别名来代替表的名称。
语法:SELECT * FROM 表名 [ AS ] 别名;
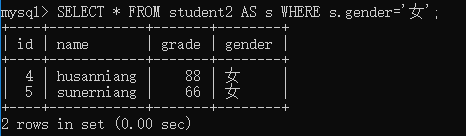
举例:为student2表起一个别名s,并查询student2表中gender字段值为“女”的记录
2)为字段起别名
语法:SELECT 字段名 [ AS ] 别名 [ ,字段名 [AS] 别名,…] FROM 表名 ;
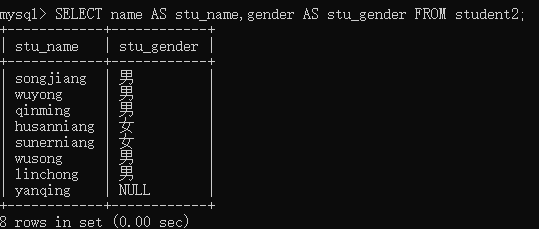
举例:查询student2表中的所有记录的name和gender字段值,并未这两个字段起别名stu_name和stu_gender
 、
、
上面是一些我们经常会用到的一些查询,接下来我要大家了解一下连表查询,先建表插数据。
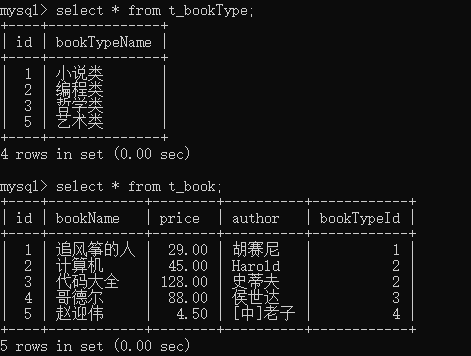
create table t_book(
id int unsigned auto_increment primary key,
bookName varchar(255) default null,
price decimal(6,2) default null,
author varchar(255) default null,
bookTypeId int(11) default null
);
insert into t_book values(1, '追风筝的人', '29.00', '胡赛尼', 1);
insert into t_book values(2, '计算机', '45.00', 'Harold', 2);
insert into t_book values(3, '代码大全', '128.00', '史蒂夫', 2);
insert into t_book values(4, '哥德尔 ', '88.00', '侯世达', 3);
insert into t_book values(5, '赵迎伟', '4.50', '[中]老子', 4); create table t_bookType(
id int(11) auto_increment not null primary key,
bookTypeName varchar(10) default null
);
insert into t_bookType values(1, '小说类');
insert into t_bookType values(2, '编程类');
insert into t_bookType values(3, '哲学类');
insert into t_bookType values(5, '艺术类');
1. 内连接:默认是内连接
内连接特点:
相连接的两张表地位平等
如果一张表中在另一张表中不存在对应数据,则不做连接
连接查询:表示查询所有数据的非NULL部分
select * from t_book, t_bookType where t_book.bookTypeId = t_bookType.id;

注:书面为赵**的书籍外键不存在,所有查询不出来
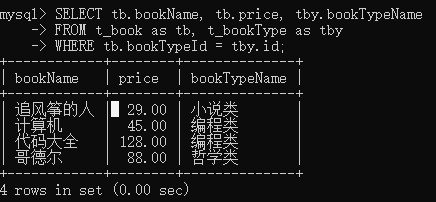
给每张表起别名用:as
SELECT tb.bookName, tb.price, tby.bookTypeName
FROM t_book as tb, t_bookType as tby
WHERE tb.bookTypeId = tby.id;
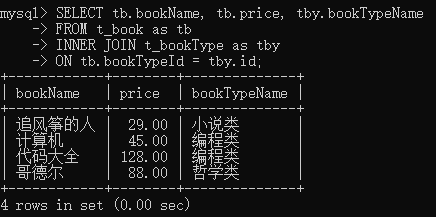
2,显示连接:
显示内连接比隐式内连接相同情况下更快。on是连接条件的限定
SELECT tb.bookName, tb.price, tby.bookTypeName
FROM t_book as tb
INNER JOIN t_bookType as tby
ON tb.bookTypeId = tby.id;
3,外连接:
外链接分为左外连接和有外连接
外连接特点:
做连接的两个表地位不相等,其中有一张是基础表
基础表中的每条数据必须出现,即使另外一张表中没有数据与之匹配,也要用Null补齐
左外连接时左表为基础表,右外连接时右表为基础表
1,左连接: LEFT JOIN ON
两张表连接查询,无论二者是否有数据缺失,一定会把左边的表数据全部显示出来
SELECT *
FROM t_book
LEFT JOIN t_bookType
ON t_book.bookTypeId = t_bookType.id

2,右连接: RIGHT JOIN ON
两张表连接查询,无论二者是否有数据缺失,一定会把右边的表数据全部显示出来
SELECT *
FROM t_book
RIGHT JOIN t_bookType
ON t_book.bookTypeId = t_bookType.id

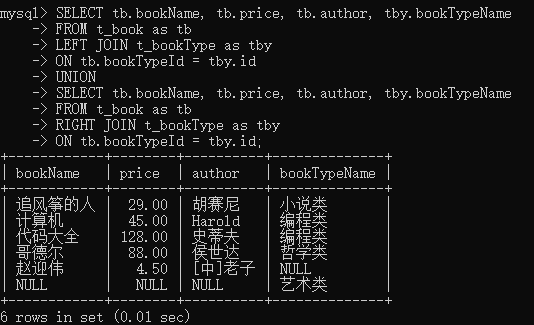
3. 全连接: UNION :
两张表连接查询,无论二者是否有数据缺失,一定会都显示表数据全部显示出来SELECT tb.bookName, tb.price, tb.author, tby.bookTypeName
FROM t_book as tb
LEFT JOIN t_bookType as tby
ON tb.bookTypeId = tby.id
UNION
SELECT tb.bookName, tb.price, tb.author, tby.bookTypeName
FROM t_book as tb
RIGHT JOIN t_bookType as tby
ON tb.bookTypeId = tby.id
4,子查询
1. 子查询: IN
在 select 语句的返回值的集合里里查找,复合集合里的数据的部分,才会匹配成功。SELECT *
FROM t_book
WHERE bookTypeId
IN (SELECT id FROM t_bookType);

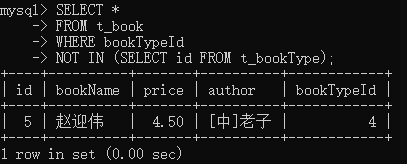
2. 子查询: NOT IN:
和 in相反,不在集合里的数据,才会匹配成功SELECT *
FROM t_book
WHERE bookTypeId
NOT IN (SELECT id FROM t_bookType);
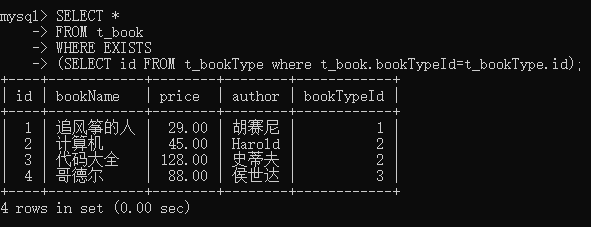
3. 子查询:EXISTS 返回Bool值,如果子查询语句里查询成功,则返回True,否则返回FalseSELECT *
FROM t_book
WHERE EXISTS
(SELECT id FROM t_bookType where t_book.bookTypeId=t_bookType.id);
4. 子查询:NOT EXISTS: 对子查询语句返回的结果取反。
SELECT *
FROM t_book
WHERE NOT EXISTS
(SELECT id FROM t_bookType where t_book.bookTypeId=t_bookType.id);

就算是一条咸鱼,也要做最咸的那一条
mysql 基础整合大全的更多相关文章
- mysql基础知识大全
前言:本文主要为mysql基础知识的大总结,mysql的基础知识很多,这里作简单概括性的介绍,具体的细节还是需要自行搜索.当然本文还有很多遗漏的地方,后续会慢慢补充完善. 数据库和数据库软件 数据库是 ...
- MYSQL查询语句大全集锦
MYSQL查询语句大全集锦 1:使用SHOW语句找出在服务器上当前存在什么数据库: mysql> SHOW DATABASES; 2:2.创建一个数据库MYSQLDATA mysql> C ...
- MySQL基础知识
一.MySQL安装 MySQL的下载 http://dev.mysql.com/downloads/mysql/ MySQL版本选择 MySQL功能自定义选择安装 1.功能自定义选择 2.路径自定义选 ...
- Mysql基础代码(不断完善中)
Mysql基础代码,不断完善中~ /* 启动MySQL */ net start mysql /* 连接与断开服务器 */ mysql -h 地址 -P 端口 -u 用户名 -p 密码 /* 跳过权限 ...
- MYSQL基础操作
MYSQL基础操作 [TOC] 1.基本定义 1.1.关系型数据库系统 关系型数据库系统是建立在关系模型上的数据库系统 什么是关系模型呢? 1.数据结构可以规定,同类数据结构一致,就是一个二维的表格 ...
- MySql 及 MySql WorkBench使用大全
Mysql安装步骤 1. 下载MySQL Community Server 5.6.13 2. 解压MySQL压缩包 将以下载的MySQL压缩包解压到自定义目录下,我的解压目录是: "D:\ ...
- 【夯实Mysql基础】记一次mysql语句的优化过程
1. [事件起因] 今天在做项目的时候,发现提供给客户端的接口时间很慢,达到了2秒多,我第一时间,抓了接口,看了运行的sql,发现就是 2个sql慢,分别占了1秒多. 一个sql是 链接了5个表同时使 ...
- MySQL基础(非常全)
MySQL基础 一.MySQL概述 1.什么是数据库 ? 答:数据的仓库,如:在ATM的示例中我们创建了一个 db 目录,称其为数据库 2.什么是 MySQL.Oracle.SQLite.Access ...
- mysql 基础篇5(mysql语法---数据)
6 增删改数据 -- ********一.增删改数据********* --- -- 1.1 增加数据 -- 插入所有字段.一定依次按顺序插入 INSERT INTO student VALUES(1 ...
随机推荐
- log.error(msg)和log.error(msg,e)的显示区别
log.error(msg): [2017-10-18 11:31:07,652] [Thread-7] (CmsCtlDataUploadFileExchange.java:50) ERROR co ...
- java编写binder服务实例
文件目录结果如下: 一. 编写AIDL文件 IHelloService.aidl: /** {@hide} */ interface IHelloService { void sayhello(); ...
- Excel VBA入门(八)单元格边框
本文基于以下文件 http://pan.baidu.com/s/1nvJtsu9 (部分)内容预览: 1. 边框样式 Sub cell_format() Dim sht As Worksheet Di ...
- CTC Loss原理
https://blog.csdn.net/left_think/article/details/76370453 1. 背景介绍 在传统的语音识别的模型中,我们对语音模型进行训练之前,往往都要将文 ...
- 130. Surrounded Regions (Graph; DFS)
Given a 2D board containing 'X' and 'O', capture all regions surrounded by 'X'. A region is captured ...
- Android工程目录结构
----------siwuxie095 首先创建一个简单的项目:MainActivity 工程目录结构一览: 工程目录结构介绍: 1.manifests目录 里面有一个AndroidManifest ...
- centos7 ntp服务器配置
一.ntp服务是什么 1. 定义 NTP是网络时间协议(Network Time Protocol),它是用来同步网络中各个计算机的时间的协议. 2. 发展 首次记载在Internet Enginee ...
- HTML 页面中的 SVG
SVG 文件可通过以下标签嵌入 HTML 文档:<embed>.<object> 或者 <iframe>. 1>使用 <embed> 标签 < ...
- C语言日志处理
一.简介 zlog是一个高可靠性.高性能.线程安全.灵活.概念清晰的纯C日志函数库,在效率.功能.安全性上大大超过了log4c,并且是用c写成的,具有比较好的通用性. 二.安装 下载 https:// ...
- knn的python代码
import heapq import random class Classifier: def __init__(self, bucketPrefix, testBucketNumber, data ...