caffe SSD目标检测lmdb数据格式制作
一、任务
现在用caffe做目标检测一般需要lmdb格式的数据,而目标检测的数据和目标分类的lmdb格式的制作难度不同。就目标检测来说,例如准备SSD需要的数据,一般需要以下几步:
1.准备图片并标注groundtruth
2.将图像和txt格式的gt转为VOC格式数据
3.将VOC格式数据转为lmdb格式数据
本文的重点在第2、3步,第一步标注任务用小代码实现即可。网络上大家制作数据格式一般是仿VOC0712的,建立各种目录,很麻烦还容易出错,现我整理了一下代码,只要两个代码,就可以从图片+txt格式gt的数据转化为lmdb格式,不需要额外的文件夹,换其他数据库也改动非常少,特别方便。
二、准备工作
本文基于已经标注好的数据,以ICDAR2013库为例,起始数据格式如下:
图片目录:ICDAR2013\img\test\*.jpg和ICDAR2013\img\train\*.jpg
gt目录:ICDAR2013\img\test\gt_*.txt和ICDAR2013\img\train\gt_*.txt
gt的格式为:

三、转VOC格式
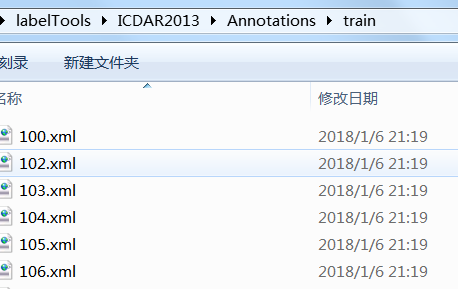
1.建立如下目录:Annotations、ImageSets、JPEGImages、label
其中Annotations里面建空文件夹test和train,用来存放转换好的gt的xml形式。当然,可以只建单个,比如只要制作train的数据那就只要建立train文件夹就好了。
ImageSets里面建空文件夹Main,里面存放train.txt和test.txt,txt内容是图片的名字,不带.jpg的名字,初始是空的,是通过代码生成的。
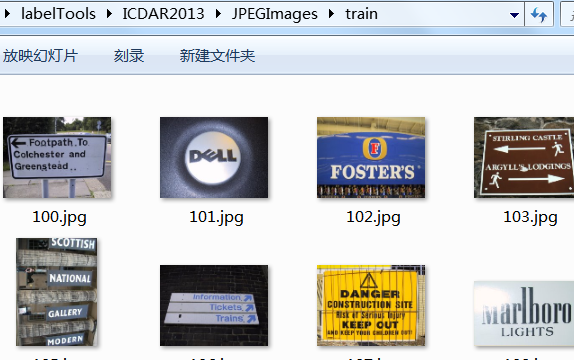
JPEGImages里面建文件夹train和test,并把训练和测试集图片对应扔进去。
里面建文件夹train和test,并把训练和测试集的groundtruth的txt文件对应扔进去。
现在格式如下:


2.使用下面的create_voc_data.py生成xml文件和后续需要的txt文件
import os
import numpy as np
import sys
import cv2
from itertools import islice
from xml.dom.minidom import Document
def create_list(dataName,img_list_txt,img_path,img_name_list_txt,type):
f=open(img_name_list_txt,'w')
fAll=open(img_list_txt,'w')
for name in os.listdir(img_path):
f.write(name[0:-4]+'\n')
fAll.write(dataName+'/'+'JPEGImages'+'/'+type+'/'+name[0:-4]+'.jpg'+' ')
fAll.write(dataName+'/'+'Annotations'+'/'+type+'/'+name[0:-4]+'.xml'+'\n')
f.close()
def insertObject(doc, datas):
obj = doc.createElement('object')
name = doc.createElement('name') name.appendChild(doc.createTextNode('text'))
obj.appendChild(name)
bndbox = doc.createElement('bndbox') xmin = doc.createElement('xmin')
xmin.appendChild(doc.createTextNode(str(datas[0]).strip(' ')))
bndbox.appendChild(xmin)
ymin = doc.createElement('ymin')
ymin.appendChild(doc.createTextNode(str(datas[1]).strip(' ')))
bndbox.appendChild(ymin)
xmax = doc.createElement('xmax')
xmax.appendChild(doc.createTextNode(str(datas[2]).strip(' ')))
bndbox.appendChild(xmax)
ymax = doc.createElement('ymax')
ymax.appendChild(doc.createTextNode(str(datas[3]).strip(' ')))
bndbox.appendChild(ymax)
obj.appendChild(bndbox)
return obj def txt_to_xml(labels_path,img_path,img_name_list_txt,xmlpath_path,bb_split,name_size):
img_name_list=np.loadtxt(img_name_list_txt,dtype=str)
name_size_file=open(name_size,'w')
for img_name in img_name_list:
print(img_name)
imageFile = img_path + img_name + '.jpg'
img = cv2.imread(imageFile)
imgSize = img.shape
name_size_file.write(img_name+' '+str(imgSize[0])+' '+str(imgSize[1])+'\n') sub_label=labels_path+'gt_'+img_name+'.txt'
fidin = open(sub_label, 'r')
flag=0
for data in islice(fidin, 1, None):
flag=flag+1
data = data.strip('\n')
datas = data.split(bb_split)
if 5 != len(datas):
print img_name+':bounding box information error'
exit(-1)
if 1 == flag:
xml_name = xmlpath_path+img_name+'.xml'
f = open(xml_name, "w")
doc = Document()
annotation = doc.createElement('annotation')
doc.appendChild(annotation) folder = doc.createElement('folder')
folder.appendChild(doc.createTextNode(dataName))
annotation.appendChild(folder) filename = doc.createElement('filename')
filename.appendChild(doc.createTextNode(img_name+'.jpg'))
annotation.appendChild(filename) size = doc.createElement('size')
width = doc.createElement('width')
width.appendChild(doc.createTextNode(str(imgSize[1])))
size.appendChild(width)
height = doc.createElement('height')
height.appendChild(doc.createTextNode(str(imgSize[0])))
size.appendChild(height)
depth = doc.createElement('depth')
depth.appendChild(doc.createTextNode(str(imgSize[2])))
size.appendChild(depth)
annotation.appendChild(size)
annotation.appendChild(insertObject(doc, datas))
else:
annotation.appendChild(insertObject(doc, datas))
try:
f.write(doc.toprettyxml(indent=' '))
f.close()
fidin.close()
except:
pass
name_size_file.close()
if __name__ == '__main__':
dataName = 'ICDAR2013' # dataset name
type = 'test' # type
bb_split=' '
img_path = dataName + '/JPEGImages/' + type + '/' # img path
img_name_list_txt = dataName + '/ImageSets/Main/'+type+'.txt'
img_list_txt=type+'.txt'
create_list(dataName,img_list_txt,img_path,img_name_list_txt,type)
labels_path = dataName+'/label/'+type+'/'
xmlpath_path = dataName+'/Annotations/'+type+'/'
name_size=type+'_name_size.txt'
#txt_to_xml(labels_path,img_path,img_name_list_txt,xmlpath_path,bb_split,name_size)
执行上面的代码就得到了
A.Annotations/test下的xml格式文件,只要修改type=train就可以得到训练集的xml格式的gt文件,下同。
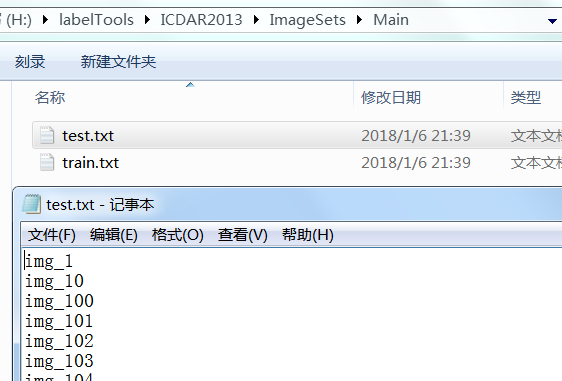
B.ImageSets\Main下的test.txt文件
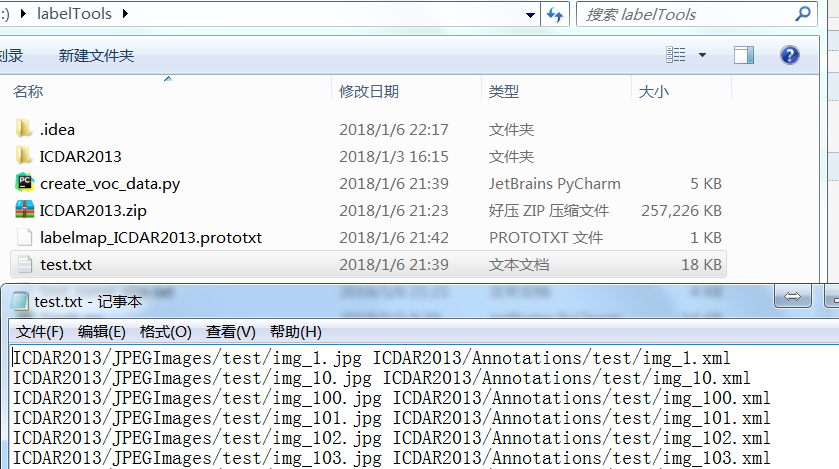
C.执行代码同级目录下的test.txt和test_name_size.txt。这两个文件本应该是用VOCDevit的create_data.sh实现的,此处用python脚本替代了,更方便。注意B和C中的txt文件内容不同,区别如下图:
四、制作lmdb格式数据。
现在需要的目录格式是这样的:(mydataset里面存VOC数据,result里面存转好的Lmdb格式的数据和通过上述代码产生的中间结果文件)
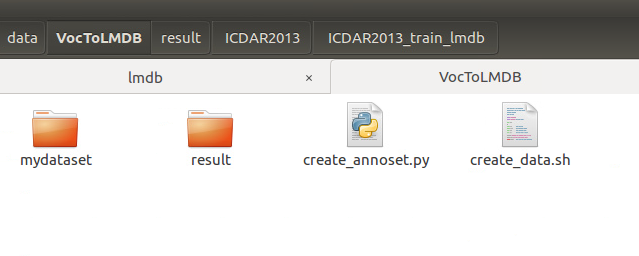
所以需要:
1、建立mydataset文件夹,把刚才制作好的VOC整个文件夹丢进去。以后换其他数据库同样整个丢进mydataset里面就可以。
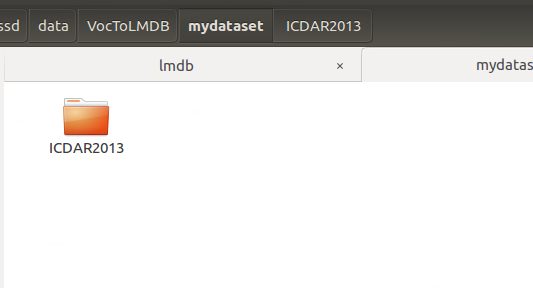
2、建立result文件夹,下面建立$dataset_name文件夹,(比如ICDAR2013,跟VOC格式里面的名字一致就可以),并把刚才产生的几个文件丢进去。
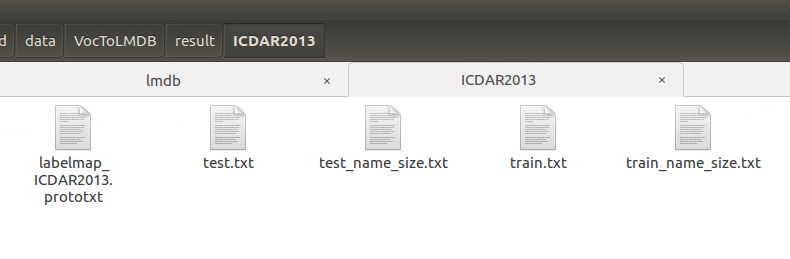
其中的labelmap_ICDAR2013.prototxt是自己建的类别文件,可以仿照VOC0712里面的,如果做文字检测就只需要两类,那么内容就如下所示:
item {
name: "none_of_the_above"
label: 0
display_name: "background"
}
item {
name: "text"
label: 1
display_name: "text"
}
3.create_data.sh是VOC0712示例修改过来的,代码如下:
cur_dir=$(cd $( dirname ${BASH_SOURCE[0]} ) && pwd )
redo=1
#VOC格式数据存放的文件夹
data_root_dir="$cur_dir/mydataset"
#训练集还是测试集,只是标识一下,就是放在一个文件夹里,放test或者train都是可以的,这样只是为了方便切换相同数据库的不同文件夹
type=test
#数据库名称,只是标记VOC数据在mydataset下面的哪个文件夹里面,结果又放在哪个文件夹里面。
dataset_name="ICDAR2013"
mapfile="$cur_dir/result/$dataset_name/labelmap_$dataset_name.prototxt"
anno_type="detection"
db="lmdb"
min_dim=0
max_dim=0
width=0
height=0
extra_cmd="--encode-type=jpg --encoded"
if [ $redo ]
then
extra_cmd="$extra_cmd --redo"
fi
for subset in $type
do
#最后一个参数是快捷方式所在的位置,不用建这个文件夹,但是为了代码改的少参数还是要有,我们在下面的create_annoset.py注释掉了生成快捷方式那句。
python create_annoset.py --anno-type=$anno_type --label-map-file=$mapfile --min-dim=$min_dim --max-dim=$max_dim --resize-width=$width --resize-height=$height --check-label $extra_cmd $data_root_dir result/$dataset_name/$subset.txt result/$dataset_name/$dataset_name"_"$subset"_"$db result/$dataset_name
done
4、create_annoset.py是在SSD框架的build/tools里面的,为了方便我们直接把它复制过来放在我们当前文件夹下,再稍微修改几个地方,修改后如下:
import argparse
import os
import shutil
import subprocess
import sys from caffe.proto import caffe_pb2
from google.protobuf import text_format if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Create AnnotatedDatum database")
parser.add_argument("root",
help="The root directory which contains the images and annotations.")
parser.add_argument("listfile",
help="The file which contains image paths and annotation info.")
parser.add_argument("outdir",
help="The output directory which stores the database file.")
parser.add_argument("exampledir",
help="The directory to store the link of the database files.")
parser.add_argument("--redo", default = False, action = "store_true",
help="Recreate the database.")
parser.add_argument("--anno-type", default = "classification",
help="The type of annotation {classification, detection}.")
parser.add_argument("--label-type", default = "xml",
help="The type of label file format for detection {xml, json, txt}.")
parser.add_argument("--backend", default = "lmdb",
help="The backend {lmdb, leveldb} for storing the result")
parser.add_argument("--check-size", default = False, action = "store_true",
help="Check that all the datum have the same size.")
parser.add_argument("--encode-type", default = "",
help="What type should we encode the image as ('png','jpg',...).")
parser.add_argument("--encoded", default = False, action = "store_true",
help="The encoded image will be save in datum.")
parser.add_argument("--gray", default = False, action = "store_true",
help="Treat images as grayscale ones.")
parser.add_argument("--label-map-file", default = "",
help="A file with LabelMap protobuf message.")
parser.add_argument("--min-dim", default = 0, type = int,
help="Minimum dimension images are resized to.")
parser.add_argument("--max-dim", default = 0, type = int,
help="Maximum dimension images are resized to.")
parser.add_argument("--resize-height", default = 0, type = int,
help="Height images are resized to.")
parser.add_argument("--resize-width", default = 0, type = int,
help="Width images are resized to.")
parser.add_argument("--shuffle", default = False, action = "store_true",
help="Randomly shuffle the order of images and their labels.")
parser.add_argument("--check-label", default = False, action = "store_true",
help="Check that there is no duplicated name/label.") args = parser.parse_args()
root_dir = args.root
list_file = args.listfile
out_dir = args.outdir
example_dir = args.exampledir redo = args.redo
anno_type = args.anno_type
label_type = args.label_type
backend = args.backend
check_size = args.check_size
encode_type = args.encode_type
encoded = args.encoded
gray = args.gray
label_map_file = args.label_map_file
min_dim = args.min_dim
max_dim = args.max_dim
resize_height = args.resize_height
resize_width = args.resize_width
shuffle = args.shuffle
check_label = args.check_label # check if root directory exists
if not os.path.exists(root_dir):
print "root directory: {} does not exist".format(root_dir)
sys.exit()
# add "/" to root directory if needed
if root_dir[-1] != "/":
root_dir += "/"
# check if list file exists
if not os.path.exists(list_file):
print "list file: {} does not exist".format(list_file)
sys.exit()
# check list file format is correct
with open(list_file, "r") as lf:
for line in lf.readlines():
img_file, anno = line.strip("\n").strip("\r").split(" ") if not os.path.exists(root_dir + img_file):
print "image file: {} does not exist".format(root_dir + img_file)
if anno_type == "classification":
if not anno.isdigit():
print "annotation: {} is not an integer".format(anno)
elif anno_type == "detection":
#print(root_dir + anno)
#print(os.path.exists(root_dir + anno))
if not os.path.exists(root_dir + anno):
print "annofation file: {} does not exist".format(root_dir + anno)
sys.exit()
break
# check if label map file exist
if anno_type == "detection":
if not os.path.exists(label_map_file):
print "label map file: {} does not exist".format(label_map_file)
sys.exit()
label_map = caffe_pb2.LabelMap()
lmf = open(label_map_file, "r")
try:
text_format.Merge(str(lmf.read()), label_map)
except:
print "Cannot parse label map file: {}".format(label_map_file)
sys.exit()
out_parent_dir = os.path.dirname(out_dir)
if not os.path.exists(out_parent_dir):
os.makedirs(out_parent_dir)
if os.path.exists(out_dir) and not redo:
print "{} already exists and I do not hear redo".format(out_dir)
sys.exit()
if os.path.exists(out_dir):
shutil.rmtree(out_dir) # get caffe root directory
#caffe_root = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
#print(caffe_root)
caffe_root='/dataL/ljy/caffe-ssd'
if anno_type == "detection":
cmd = "{}/build/tools/convert_annoset" \
" --anno_type={}" \
" --label_type={}" \
" --label_map_file={}" \
" --check_label={}" \
" --min_dim={}" \
" --max_dim={}" \
" --resize_height={}" \
" --resize_width={}" \
" --backend={}" \
" --shuffle={}" \
" --check_size={}" \
" --encode_type={}" \
" --encoded={}" \
" --gray={}" \
" {} {} {}" \
.format(caffe_root, anno_type, label_type, label_map_file, check_label,
min_dim, max_dim, resize_height, resize_width, backend, shuffle,
check_size, encode_type, encoded, gray, root_dir, list_file, out_dir)
elif anno_type == "classification":
cmd = "{}/build/tools/convert_annoset" \
" --anno_type={}" \
" --min_dim={}" \
" --max_dim={}" \
" --resize_height={}" \
" --resize_width={}" \
" --backend={}" \
" --shuffle={}" \
" --check_size={}" \
" --encode_type={}" \
" --encoded={}" \
" --gray={}" \
" {} {} {}" \
.format(caffe_root, anno_type, min_dim, max_dim, resize_height,
resize_width, backend, shuffle, check_size, encode_type, encoded,
gray, root_dir, list_file, out_dir)
print cmd
process = subprocess.Popen(cmd.split(), stdout=subprocess.PIPE)
output = process.communicate()[0] if not os.path.exists(example_dir):
os.makedirs(example_dir)
link_dir = os.path.join(example_dir, os.path.basename(out_dir))
print(link_dir)
'''
if os.path.exists(link_dir):
os.unlink(link_dir) os.symlink(out_dir, link_dir)
'''
上面代码修改的地方是:
A.注释掉了最后三句。最后三句是创建快捷方式,可以注释掉。这里不注释掉会报错,原因不明,反正也不需要快捷方式,lmdb有了就万事俱备了。
B.img_file, anno = line.strip("\n").strip("\r").split(" ") ,这句加了("\r")。这句一般情况下改不改都行,但是如果create_voc_data.py是在windows上执行的,后面这个sh在Linux上执行报错就要改,因为windows和linux系统对换行的处理不同,完全按上述步骤会发现到Linux系统上把换号当回车处理了,导致明明路径是对的缺找不到相应文件。
C.caffe_root='/dataL/ljy/caffe-ssd'。这句是把caffe目录切过来。因为原来的代码是严格按照VOC0712数据做的,那么caffe_root就会跟我们不一样,就需要改。
执行create_data.sh就可以在result/ICDAR2013/下面看到我们得到的lmdb格式的数据了。对于相同数据集只要改type=test或者train就行,不用数据集只要改数据集名字就可以。
五、总结。
从无到有生成目标检测Lmdb的步骤为:
1. 获得待制作的图片
2. 用标记工具标记groundtruth,为txt类型的gt。
3. 按上面的步骤三建立VOC目录结构并用create_voc_data.py将2中的数据转为VOC格式。
4. 按上面的步骤四建立结果目录结构并用create_data.py将3中的数据转为lmdb格式,完成。
需要注意下面几点:
1.如何换数据集:只要在上面两个需要建目录的地方把ICDAR2013改成其他库,并把两个代码中的dataset_name改成相应数据集名称就行。
2.如何换相同数据集的的不同部分:比如把ICDAR2013的测试集换成训练集,只要在相应的目录下建立train文件夹,并改代码里面的type=train就可以。
caffe SSD目标检测lmdb数据格式制作的更多相关文章
- TF项目实战(SSD目标检测)-VOC2007
TF项目实战(SSD目标检测)-VOC2007 训练好的模型和代码会公布在网上: 步骤: 1.代码地址:https://github.com/balancap/SSD-Tensorflow 2.解压s ...
- 从零开始实现SSD目标检测(pytorch)(一)
目录 从零开始实现SSD目标检测(pytorch) 第一章 相关概念概述 1.1 检测框表示 1.2 交并比 第二章 基础网络 2.1 基础网络 2.2 附加网络 第三章 先验框设计 3.1 引言 3 ...
- TF项目实战(基于SSD目标检测)——人脸检测1
SSD实战——人脸检测 Tensorflow 一 .人脸检测的困难: 1. 姿态问题 2.不同种族人, 3.光照 遮挡 带眼睛 4.视角不同 5. 不同尺度 二. 数据集介绍以及转化VOC: 1. F ...
- AI SSD目标检测算法
Single Shot multibox Detector,简称SSD,是一种目标检测算法. Single Shot意味着SSD属于one stage方法,multibox表示多框预测. CNN 多尺 ...
- 动手创建 SSD 目标检测框架
参考:单发多框检测(SSD) 本文代码被我放置在 Github:https://github.com/XinetAI/CVX/blob/master/app/gluoncvx/ssd.py 关于 SS ...
- 如何使用 pytorch 实现 SSD 目标检测算法
前言 SSD 的全称是 Single Shot MultiBox Detector,它和 YOLO 一样,是 One-Stage 目标检测算法中的一种.由于是单阶段的算法,不需要产生所谓的候选区域,所 ...
- 使用SSD目标检测c++接口编译问题解决记录
本来SSD做测试的Python接口用起来也是比较方便的,但是如果部署集成的话,肯定要用c++环境,于是动手鼓捣了一下. 编译用的cmake,写的CMakeList.txt,期间碰到一些小问题,简单记录 ...
- SSD目标检测实战(TF项目)——人脸检测2
数据转化为VOC格式: 一.我们先看 VOC格式的数据是什么??? Annotations:存放xml 包括 文件夹信息 图片名称. 图片尺寸信息. 图片中object的信息. JPEGImage ...
- 【目标检测实战】目标检测实战之一--手把手教你LMDB格式数据集制作!
文章目录 1 目标检测简介 2 lmdb数据制作 2.1 VOC数据制作 2.2 lmdb文件生成 lmdb格式的数据是在使用caffe进行目标检测或分类时,使用的一种数据格式.这里我主要以目标检测为 ...
随机推荐
- 4、一、Introduction(入门):3、System Permissions(系统权限)
3.System Permissions(系统权限) Android is a privilege-separated operating system, in which each applic ...
- Kafka 1.1新功能:数据的路径间迁移
经常有小伙伴有这样的疑问:为什么线上Kafka机器各个磁盘间的占用不均匀,经常出现“一边倒”的情形? 这是因为Kafka只保证分区数量在各个磁盘上均匀分布,但它无法知晓每个分区实际占用空间,故很有可能 ...
- 用CSS里的 viewport-fit 标签应对iPhone X 的刘海
iPhone X 配备一个覆盖整个手机的全面屏,顶部的“刘海”为相机和其他组件留出了空间.然而结果就是会出现一些尴尬的情景:网站被限制在一个“安全区域”,在两侧边缘会出现白条儿.移除这个白条儿也不难, ...
- 解决UEFI启动模式下无法使用U盘启动WIN7安装界面
问题场景 现在很多人都习惯使用U盘进行安装系统,主要是快捷方便.本文主要是讲解一下U盘在UEFI模式下无法启动Windows7安装界面的问题,可能很多人会说使用PE系统进行安装,但是因为我的主板只有独 ...
- webpack 配置
https://segmentfault.com/a/1190000009454172
- easyui---修改删除查询
修改:在toolsbar 修改工具中 { text:"编辑用户", iconCls:"icon-edit", handler:function(){ var s ...
- Codeforces 835C - Star sky - [二维前缀和]
题目链接:http://codeforces.com/problemset/problem/835/C 题意: 在天空上划定一个直角坐标系,有 $n$ 颗星星,每颗星星都有坐标 $(x_i,y_i)$ ...
- php字符串操作
1.字符串的格式化 按照从表单提交数据之后,php处理的不同:接受,显示,存储.也有三种类型的格式化方法. 1.1字符串的接收之后的整理: trim(),ltrim(),rtrim() 当数据从表单中 ...
- tensorflow的ckpt文件总结
1.TensorFlow的模型文件 --checkpoint_dir | |--checkpoint | |--MyModel.meta | |--MyModel.data-00000-of-0000 ...
- iOS知识点持续更新。。。
1.自动布局拉伸和压缩优先级 Autolayout中每个约束都有一个优先级,优先级的范围是1~1000.创建一个约束,默认的优先级最高是1000. Content Hugging Priority:该 ...