Scala集合(一)
Scala集合的主要特质

Iterator,用来访问集合中所有元素
val coll = ... // 某种Iterable val iter = col.iterator while(iter.hasNext) iter.next()
Seq是一个有先后次序的值得序列,比如数组或列表。
IndexSeq允许我们通过整型的下标快速访问任意元素,如ArrayBuffer是带下标的。
Set是一组没有先后次序的值,在SortedSet中,元素以某种排过序的顺序被访问。
Map是一组(K,V)对偶,SortedMap按照键的排序访问。
每个Scala集合特质或类,都有一个带有apply方法的伴生对象,这个apply方法可以用来构建该集合中的实例。
Iterable(0xFF, 0xFF00, 0xFF0000)
set(color.RED, color.GREEN, Color.BLUE)
Map(color.RED -> -0xFF0000, Color.GREEN -> 0xFF00, Color.BLUE -> 0xFF)
SortedSet("Hello" , "World")
可变和不可变集合
scala.collection.mutable.Map //可变
scala.collection.immutable.Map //不可变
scala.collection.Map //超类
Scala优先采用不可变集合, scala.collection 包中的伴生对象产出不可变的集合
scala.collection.Map("Hello" -> ) //不可变映射
因为Scala包和Predef对象总是被引入,他们都指向不可变特质的类型别名List、Set和Map.
Preedef.Map和scala.collection.immutable.Map是一回事
import scala.collection.mutable
用Map得到不可变,用mutable.Map得到可变的。
序列
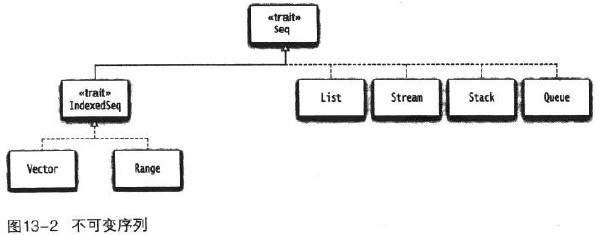
Vector是ArrayBuffer的不可变版本,一个带下标的序列,支持快捷的随机访问,以树形结构的形式实现。 Range表示一个整数序列,只存储起始值,结束值和增值, 用 to 和 until 方法来构造Range对象。
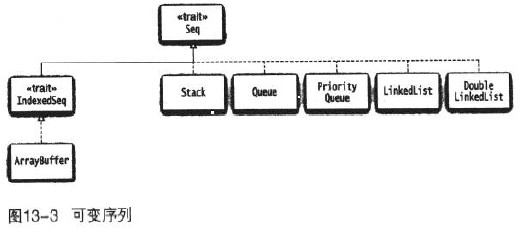
列表
列表要么是Nil(空表),要么是一个head元素和一个tail,tail又是一个列表。
val digits = List(,)
digits.head //
digits.tail// List(2)
digits.tail.head//
digits.tail.tail //Nil
:: 操作符从给定的头和尾创建一个新的列表。
:: List(,) // List(9,4,2)
:: :: :: Nil // :: 是右结合,列表从末端开始构建
:: ( :: ( :: Nil ) )
迭代, 除了遍历外,可以用 递归 模式匹配
def sum(lst : List[Int]): Int =
if( lst == Nil) else lst.head + sum(lst.tail)
def sum(lst:List[Int]): Int = lst match{
case Nil =>
case h :: t => h+sum(t) // h 是 lst.head, 而t是lst.tail, ::将列表“析构”成头部和尾部
}
直接使用List的方法
List(,,).sum
可变列表
LinkedList, elem指向当前值,next指向下一个元素
DoubleLinkedList多带一个prev
val lst = scala.collection.mutable.LinkedList(,-,,-)
var cur = lst
while(cur != Nil){
if(cur.elem<) cur.elem =
cur = cur.next
} // (1,0,7,0) ,将所有负值改为0
var cur = lst
while(cur != Nil && cur.next != Nil){
cur.next = cur.next.next
cur = cur.next
}// 去除每两个元素中的一个
注:当要把某个节点变为列表中的最后一个节点,不能将next 设为Nil 或 null, 而将它设为LinkedList.empty。
集
不重复元素的集合,以哈希集实现,元素根据hashCode方法的值进行组织 Set(,,) + // (2,0,1) LinkedHashSet,链式哈希集 记住元素被插入的顺序 val weekdays = scala.collection.mutable.LinkedHashSet(,,,) 排序的集 scala.collection.immutable.SortedSet(,,,) // 用红黑树实现的 Scala .9没有可变的已排序集,用java.util.TreeSet 位集(bit set), 以一个字位序列的方式存放非负整数,如果集中有i,则第i个字位是1 高效的实现,只要最大元素不是特别大。 Scala提供 可变和不可变的两个 BitSet类 contains 检查是否包含, subsetOf 检查集的所有元素是否被另一个集包含 val digits = Set(,,,) digits contains // false Set(,) subsetOf digits // true
union intersect diff 方法,也可写作| ,&, &~ union 还可以写成 ++, diff 写作 -- val primes = Set(, , , ) digits union primes // Set(1,2,3,5,7,9) digits & primes // Set (2,7) digits -- primes // Set(1,9)
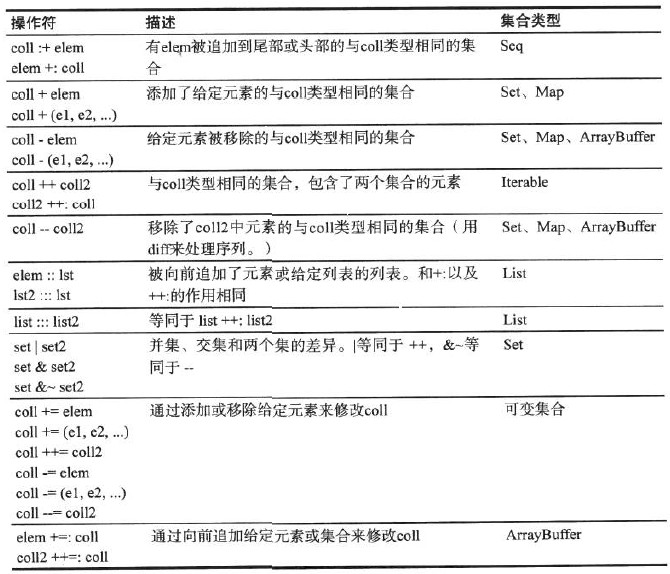
一般而言,+用于将元素添加到无先后次序的集合,而+:和:+则是将元素添加到有先后次序的集合的开头或末尾。 Vector(,,) :+ //Vector(1,2,3,5) +: Vector(,,) //Vector(1,1,2,3) 以冒号结尾的操作符,+:是右结合的,这些操作符都返回新的集合 可变集合有 +=操作符 用于修改左侧操作元 val numbers = ArrayBuffer(,,) numbers += // 将 5 添加到 numbers 不可变集合,可以在var上使用+=或:+= var numbers = Set(,,) numbers += // numbers 设为不可变的集numbers + 5 var numberVector = Vector(,,) numbersVector :+= // 向量没有+操作符,只有:+ 移除元素 Set(,,) - // Set(1,3) ++来一次添加多个元素, -- 一次移除多个元素 col1 ++ col2

Scala集合(一)的更多相关文章
- Scala集合操作
大数据技术是数据的集合以及对数据集合的操作技术的统称,具体来说: 1.数据集合:会涉及数据的搜集.存储等,搜集会有很多技术,存储技术现在比较经典方案是使用Hadoop,不过也很多方案采用Kafka. ...
- Spark:scala集合转化为DS/DF
scala集合转化为DS/DF case class TestPerson(name: String, age: Long, salary: Double) val tom = TestPerson( ...
- Scala集合常用方法解析
Java 集合 : 数据的容器,可以在内部容纳数据 List : 有序,可重复的 Set : 无序,不可重复 Map : 无序,存储K-V键值对,key不可重复 scala 集合 : 可变集合( ...
- Scala集合笔记
Scala的集合框架类比Java提供了更多的一些方便的api,使得使用scala编程时代码变得非常精简,尤其是在Spark中,很多功能都是由scala的这些api构成的,所以,了解这些方法的使用,将更 ...
- Scala集合类型详解
Scala集合 Scala提供了一套很好的集合实现,提供了一些集合类型的抽象. Scala 集合分为可变的和不可变的集合. 可变集合可以在适当的地方被更新或扩展.这意味着你可以修改,添加,移除一个集合 ...
- 再谈Scala集合
集合!集合!一个现代语言平台上的程序员每天代码里用的最多的大概就是该语言上的集合类了,Scala的集合丰富而强大,至今无出其右者,所以这次再回过头再梳理一下. 本文原文出处: 还是先上张图吧,这是我 ...
- Spark记录-Scala集合
Scala列表 Scala列表与数组非常相似,列表的所有元素都具有相同的类型,但有两个重要的区别. 首先,列表是不可变的,列表的元素不能通过赋值来更改. 其次,列表表示一个链表,而数组是平的. 具有类 ...
- scala集合与java集合的转换应用
今天在业务开发中遇到需要Scala集合转为Java集合的场景: 因为业务全部是由Scala开发,但是也避免不了调用Java方法的场景,所以将此记录下来加深记忆: import scala.collec ...
- Scala集合学习总结
遍历集合可以使用迭代器iterator的那套迭代方式.Seq是一个有先后次序的序列,比如数组或列表.IndexedSeq可以通过下标进行任意元素的访问.例如ArrrayBuffer. Set是一组没有 ...
随机推荐
- Using Information Fragments to Answer the Questions Developers Ask
content : 1.采访了11个开发者,获得78个常问的问题:2.对78个问题进行分类,分为8类:These questions span eight domains of information ...
- Qt编写守护程序保证程序一直运行(开源)
没有任何人敢保证自己写的程序没有任何BUG,尤其是在商业项目中,程序量越大,复杂度越高,出错的概率越大,尤其是现场环境千差万别,和当初本地电脑测试环境很可能不一样,有很多特殊情况没有考虑到,如果需要保 ...
- C# 如何提取字符串中的数字
下面讲解如何在字符串当中抓取到数字 方法一.使用正则表达式 1.纯数字提取 string str = "提取123abc提取"; //我们抓取当前字符当中的123 string r ...
- 题目1015:还是A+B(简单判断)
题目链接:http://ac.jobdu.com/problem.php?pid=1015 详解链接:https://github.com/zpfbuaa/JobduInCPlusPlus 参考代码: ...
- autolayout 高度自适应
https://lvwenhan.com/ios/449.html #import "ViewController.h" #import "MyTableViewCell ...
- Excel制作考勤管理
一.在选择年月 在选择年月的下拉菜单,有Excel中的——数据——数据有效性——序列——来源(用逗号分开) 二.在Excel中显示今天的时间及时间 函数代码:(="今天是:"& ...
- TIScript 代码Demo
var filelist = null; function alert(msg) { view.msgbox(null,msg); } self.on("click", " ...
- node_readline (逐行读取)
node官方文档 用于逐行读取文件流, 和终端交互 读取文件流 const fs = require('fs'); const readline = require('readline'); var ...
- linux 关闭笔记本自带键盘
linux 命令行工具 xinput list 找到 AT Translated Set 2 keyboard,其 id为 13 设置值为 0 xinput 如果想恢复,对应的值设为1即可 xinpu ...
- html学习_html5 新增标签和属性
html5 新增标签和属性 1.html发展历程(html有很多版本) 2.快捷键生成不同版本(html4.xhtml.html5) 文档类型不同.字符设定 3.常用新标签 (只有html5才识别的标 ...