[Python] 03 - Lists, Dictionaries, Tuples, Set
List 列表
一、基础知识
基础功能
初始化方法
特例:初始化字符串
>>> sList = list("hello")
>>> sList
['h', 'e', 'l', 'l', 'o']
功能函数
append # 添加一个元素
pop # 拿走一个元素
sort
reverse
In [11]: dir(list)
Out[11]:
['__add__',
'__class__',
'__contains__',
'__delattr__',
'__delitem__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
'__gt__',
'__hash__',
'__iadd__',
'__imul__',
'__init__',
'__iter__',
'__le__',
'__len__',
'__lt__',
'__mul__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__reversed__',
'__rmul__',
'__setattr__',
'__setitem__',
'__sizeof__',
'__str__',
'__subclasshook__',
'append',
'clear',
'copy',
'count',
'extend',
'index',
'insert',
'pop',
'remove',
'reverse',
'sort']
dir(list)
强引用 & 弱应用
弱引用
与apend的区别是:extend只作用于List。
>>> L = [1, 2]
>>> M = L
>>> L += [3, 4] # 还是原来的对象,只是变大了
>>> L, M # M sees the in-place change too!
([1, 2, 3, 4], [1, 2, 3, 4])
强引用 --> 复制
>>> L = [1, 2]
>>> M = L # L and M reference the same object
>>> L = L + [3, 4] # 其实是新对象
>>> L, M # Changes L but not M
([1, 2, 3, 4], [1, 2])
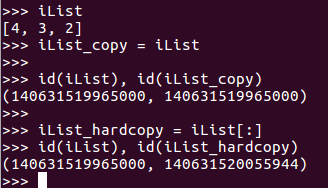
强引用 --> [ : ] 代表了 ‘拷贝’
第一个变了;第二个没变,以为 [:] 代表了‘拷贝’ 的意思。

通过地址查看
二、元素遍历
直接遍历
For 循环
[ 某行第一个元素 for 某行 in 矩阵 ]
实例1:提取其中一列column.
>>> col2 = [row[1] for row in M] # Collect the items in column 2
>>> col2
[2, 5, 8]
>>> M # The matrix is unchanged
[[1, 2, 3], [4, 5, 6], [7, 8, 9]] >>> [row[1] for row in M if row[1] % 2 == 0] # Filter out odd items
[2, 8]
实例2:有点pipeline的意思
>>> [[x ** 2, x ** 3] for x in range(4)] # Multiple values, "if" filters
[[0, 0], [1, 1], [4, 8], [9, 27]]
>>> [[x, x / 2, x * 2] for x in range(−6, 7, 2) if x > 0]
[[2, 1, 4], [4, 2, 8], [6, 3, 12]]
while ... else
while test: # Loop test
statements # Loop body
else: # Optional else
statements # Run if didn't exit loop with break
这个else是个很好的东西,表示循环走到头了;有益代码阅读。
for ... else
for target in object: # Assign object items to target
statements # Repeated loop body: use target
else: # Optional else part
statements # If we didn't hit a 'break'
lambda 迭代遍历
map() 会根据提供的函数对"指定序列"做映射。
<返回list类型> = map(function, iterable, ...)
# 1. 独立函数
>>>def square(x) : # 计算平方数
... return x ** 2
...
>>> map(square, [1,2,3,4,5]) # 计算列表和:1+2+3+4+5
[1, 4, 9, 16, 25] ----------------------------------------------------------------
# 2. 匿名函数
>>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数
[1, 4, 9, 16, 25] ----------------------------------------------------------------
# 3. 提供了两个列表,对相同位置的列表数据进行相加
>>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])
[3, 7, 11, 15, 19]
不同的类型是否Iterable的判断.
>>> from collections import Iterable
>>> isinstance('abc', Iterable) # str是否可迭代
True
>>> isinstance([1,2,3], Iterable) # list是否可迭代
True
>>> isinstance(123, Iterable) # 整数是否可迭代
False
map & reduce
(1) map
>>> def f(x):
... return x * x
...
>>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> list(r)
[1, 4, 9, 16, 25, 36, 49, 64, 81]
(2) reduce
>>> from functools import reduce
>>> def fn(x, y):
... return x * 10 + y
...
>>> reduce(fn, [1, 3, 5, 7, 9])
13579
(3) map + reduce
典型的例子:第一步map,解析字符串数字;第二步reduce,求数字的和.
from functools import reduce
DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
def str2int(s):
def fn(x, y):
return x * 10 + y
def char2num(s):
return DIGITS[s]
return reduce(fn, map(char2num, s))
Iterable 遍历
Goto: [Advanced Python] 14 - "Generator": calculating prime
next
In [13]: M = [[1, 2, 3], # A 3 × 3 matrix, as nested lists
...:
...: [4, 5, 6], # Code can span lines if bracketed
...:
...: [7, 8, 9]]
In [14]: G = (sum(row) for row in M) # <----这里使用元组,返回的是iterable的结构 In [16]: next(G) # 输出一行
Out[16]: 6 In [17]: next(G) # 再输出一行
Out[17]: 15 In [18]: next(G) # 再输出一行
Out[18]: 24
列表(方括号),集合(大括号),字典(大括号),元组(圆括号) 效果对比,只有元组是Iterable的.

generator
yield x: Generator function send protocol
From: https://www.jianshu.com/p/d09778f4e055
带有 yield 的函数不再是一个普通函数,而是一个生成器 generator,可用于迭代,工作原理同next()。
类似 return 的关键字。
send(msg)与next()的区别在于send可以传递参数给yield表达式,这时传递的参数会作为yield表达式的值,而yield的参数是返回给调用者的值。
其实就是让一个函数分步执行:
>>> def get_0_1_2():
... yield 0
... yield 1
... yield 2
...
>>> get_0_1_2
<function get_0_1_2 at 0x00B2CB70>
generator = get_0_1_2() # 绑定了函数后就开始执行>>> generator.next()
0
>>> generator.next()
1
>>> generator.next()
2
api有了稍许变化!【这个貌似好用】
generator = get_0_1_2() # 必须这么绑定一下,直接用函数名不行 In [83]: next(generator)
Out[83]: 0 In [84]: next(generator)
Out[84]: 1 In [85]: next(generator)
Out[85]: 2 In [86]: next(generator)
Error.
迭代越界 StopIteration
>>> from itertools import chain
>>> it = chain([1,2,3],[4,5,6],[7,8,9])
>>> while True:
... try:
... elem = it.next()
... except StopIteration:
... print "Last element was:", elem, "... do something special now"
... break
... print "Got element:", elem
...
...
Got element: 1
Got element: 2
Got element: 3
Got element: 4
Got element: 5
Got element: 6
Got element: 7
Got element: 8
Got element: 9
Last element was: 9 ... do something special now
>>>
嵌套遍历
"二级列表"处理
一来效率高;二来支持多列表。注意,解开”嵌套“的顺序。
matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
flat = [x for row in matrix for x in row]
print(flat)
"多条件"设置
matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
filtered = [[x for x in row if x % 3 == 0] for row in matrix if sum(row) >= 10]
print(filtered)
>>>
[[6], [9]]
高性能测量
查看内存占用
import sys
sys.getsizeof([1,2,3])
耗时对比
In [1]: %timeit l = [1,2,3,4,5,6,7,8,9,0]
58.1 ns ± 1.42 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each) In [2]: %timeit l = (1,2,3,4,5,6,7,8,9,0)
9.78 ns ± 0.114 ns per loop (mean ± std. dev. of 7 runs, 100000000 loops each)
三、排序
内部方法
改变了自己本身。
>>> L = ['abc', 'ABD', 'aBe']
>>> L.sort() # Sort with mixed case
>>> L
['ABD', 'aBe', 'abc']
>>> L = ['abc', 'ABD', 'aBe']
>>> L.sort(key=str.lower) # Normalize to lowercase 忽略大小写
>>> L
['abc', 'ABD', 'aBe'] >>> L = ['abc', 'ABD', 'aBe']
>>> L.sort(key=str.lower, reverse=True) # Change sort order 反过来
>>> L
['aBe', 'ABD', 'abc']
Bisect 模块:一个有趣的python排序模块:bisect
>>> import bisect
>>> data = [1,2,3,4]
>>> bisect.bisect(data, 2)
2
>>> bisect.bisect_left(data, 2)
1
>>> bisect.bisect_right(data, 2)
2
系统方法
生成了新的列表。
>>> L = ['abc', 'ABD', 'aBe']
>>> sorted(L, key=str.lower, reverse=True) # Sorting built-in
['aBe', 'ABD', 'abc']
>>> L = ['abc', 'ABD', 'aBe']
>>> sorted([x.lower() for x in L], reverse=True) # Pretransform items: differs!
['abe', 'abd', 'abc']
Dictionaries 字典
一、初始化的几种方式
(1) 显式初始化
>>> D = {'spam': 2, 'ham': 1, 'eggs': 3} # 显式初始化
>>> bob1 = dict(name='Bob', job='dev', age=40) # 参数初始化
>>> bob1
{'age': 40, 'name': 'Bob', 'job': 'dev'}
(2) 只有key值
-----------------------------------------------------------------------
------------------------------ 数字 -----------------------------------
----------------------------------------------------------------------- >>> D = dict.fromkeys(['a', 'b', 'c'], 0) # Initialize dict from keys
>>> D
{'b': 0, 'c': 0, 'a': 0} -----------------------------------------------------------------------
>>> D = {k:0 for k in ['a', 'b', 'c']} # Same, but with a comprehension
>>> D
{'b': 0, 'c': 0, 'a': 0} -----------------------------------------------------------------------
------------------------------ 字符串 ----------------------------------
----------------------------------------------------------------------- >>> D = dict.fromkeys('spam') # Other iterables, default value
>>> D
{'s': None, 'p': None, 'a': None, 'm': None} -----------------------------------------------------------------------
>>> D = {k: None for k in 'spam'}
>>> D
{'s': None, 'p': None, 'a': None, 'm': None}
(3) key, value 都知道
>>> bob2 = dict( zip(['name', 'job', 'age'], ['Bob', 'dev', 40]) ) # Zipping
>>> bob2
{'job': 'dev', 'name': 'Bob', 'age': 40}
zip操作
>>> list( zip(['a', 'b', 'c'], [1, 2, 3]) ) # Zip together keys and values
[('a', 1), ('b', 2), ('c', 3)]
>>> D = dict( zip(['a', 'b', 'c'], [1, 2, 3]) ) # Make a dict from zip result
>>> D
{'b': 2, 'c': 3, 'a': 1} # 进一步,在配对的过程中可以做一些lamdb的操作
>>> D = {k: v for (k, v) in zip(['a', 'b', 'c'], [1, 2, 3])}
>>> D
{'b': 2, 'c': 3, 'a': 1}
zip的反操作
>>> a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
[(1, 2, 3), (4, 5, 6)]
二、插入操作
单元素添加
a = {‘age’: 23, ‘name’: ‘lala}
a[school] = ‘nanhaizhongxue’
print a
>>> {‘age’: 23, ‘name’: ‘lala’, ‘school’: ‘nanhaizhongxue’}
字典合并
>>> D
{'eggs': 3, 'spam': 2, 'ham': 1}
>>> D2 = {'toast':4, 'muffin':5} # Lots of delicious scrambled order here
>>> D.update(D2)
>>> D
{'eggs': 3, 'muffin': 5, 'toast': 4, 'spam': 2, 'ham': 1}
三、遍历键值
间接遍历
单独输出所有的key;单独输出所有的value;单独输出所有的(key, value);
print(dic.keys()) # dict_keys(['赵四', '刘能', '王木生']) 像列表. 山寨列表
for k in dic.keys(): # 拿到的是字典中的每一个key
print(k)
print(dic.values()) # dict_values(['刘晓光', '王晓利', '范伟']) 所有的value的一个数据集
for v in dic.values():
print(v)
print(dic.items()) # 所有的键值对 dict_items([('赵四', '刘晓光'), ('刘能', '王晓利'), ('王木生', '范伟')])
for k, v in dic.items(): # 遍历字典最简单的方案
print(item) # ('赵四', '刘晓光')
k, v = item # 解构
k = item[0]
v = item[1]
print(k, v)
直接遍历
默认的是直接遍历key值。
dic = {"赵四":"刘晓光", "刘能":"王晓利", "王木生":"范伟"}
# 直接for循环
for key in dic: # 直接循环字典拿到的是key, 有key直接拿value
print(key)
print(dic[key])
获取 value 的第二种方式
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 27}
print "Value : %s" % dict.get('Age')
print "Value : %s" % dict.get('Sex', "Never")
四、排序
排序key值
先取出key值,再排序。
>>> Ks = list( D.keys() ) # Unordered keys list
>>> Ks # A list in 2.X, "view" in 3.X: use list()
['a', 'c', 'b']
>>> Ks.sort() # Sorted keys list
>>> Ks
['a', 'b', 'c']
>>> for key in Ks: # Iterate though sorted keys
print(key, '=>', D[key]) # <== press Enter twice here (3.X print)
a => 1
b => 2
c => 3
排序value值
默认是排序value值。
# 键
>>> list( D.items() )
[('eggs', ), ('spam', ), ('ham', )]
五、判断 key 是否存在
有么?
第一种方法:使用自带函数实现:
在 python 的字典的属性方法里面有一个 has_key() 方法:
#生成一个字典
d = {'name':Tom, 'age':10, 'Tel':110}
#打印返回值
print d.has_key('name')
#结果返回True
在里面么?
第二种方法:使用 in 方法: 【推荐,更快】
#生成一个字典
d = {'name':'Tom', 'age':10, 'Tel':110} #打印返回值,其中d.keys()是列出字典所有的key,以下两个结果一样,返回True
print(‘name’ in d.keys())
print('name' in d) #一个例子:多维数据使用 dict.
>>> if (2, 3, 6) in Matrix: # Check for key before fetch
... print(Matrix[(2, 3, 6)]) # See Chapters 10 and 12 for if/else
... else:
... print(0)
...
0
除了使用 in 还可以使用 not in。
异常了么?
第三种方法:try...except方法:
如果不在,造成错误,大不了走except路线。
>>> try:
... print(Matrix[(2, 3, 6)]) # Try to index
... except KeyError: # Catch and recover
... print(0) # See Chapters 10 and 34 for try/except
...
0
稀疏矩阵
妙,表示稀疏矩阵:Using dictionaries for sparse data structures: Tuple keys
>>> Matrix = {}
>>> Matrix[(2, 3, 4)] = 88
>>> Matrix[(7, 8, 9)] = 99
>>>
>>> X = 2; Y = 3; Z = 4 # ; separates statements: see Chapter 10 这里更灵活!
>>> Matrix[(X, Y, Z)]
88
Tuples 元组
一、不变性 immutability
携带一些比较类似list的性质,但功能较少。
>>> T.index(4) # Tuple methods: 4 appears at offset 3
3
>>> T.count(4) # 4 appears once
1
Why Lists and Tuples?:
Frankly, tuples are not generally used as often as lists in practice, but their immutability is the whole point.
If you pass a collection of objects around your program as a list, it can be changed anywhere; if you use a tuple, it cannot.
不变性,可能就是其存在的意义。
二、tuple歧义
小括号中一个元素
括号()既可以表示tuple,又可以表示数学公式中的小括号。
只有一个元素的tuple必须跟着“逗号”
>>> t = (1)
>>> t
1 >>> t = (1,)
>>> t
(1,)
“相对” 不变性
tuple的第一级元素不能变,但控制不了元素内部的“可变”。
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
Sets 集合
一、常见集合运算
拆分字符串
>>> X = set('spam') # Make a set out of a sequence in 2.X and 3.X
>>> Y = {'h', 'a', 'm'} # Make a set with set literals in 3.X and 2.7
>>> X, Y # A tuple of two sets without parentheses
({'m', 'a', 'p', 's'}, {'m', 'a', 'h'})
集合逻辑运算
>>> X & Y # Intersection
{'m', 'a'}
>>> X | Y # Union
{'m', 'h', 'a', 'p', 's'}
>>> X - Y # Difference
{'p', 's'}
>>> X > Y # Superset
False
二、集合遍历
注意,这里是大括号。
>>> {n ** 2 for n in [1, 2, 3, 4]} # Set comprehensions in 3.X and 2.7
{16, 1, 4, 9}
三、与List的相互转化
Goto: Python列表、元组、集合、字典的区别和相互转换
End.
[Python] 03 - Lists, Dictionaries, Tuples, Set的更多相关文章
- python arguments *args and **args ** is for dictionaries, * is for lists or tuples.
below is a good answer for this question , so I copy on here for some people need it By the way, the ...
- Python 列表(Lists)
Python 列表(Lists) 序列是Python中最基本的数据结构.序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推. Python有6个序列的内置类 ...
- Think Python - Chapter 11 - Dictionaries
Dictionaries A dictionary is like a list, but more general. In a list, the indices have to be intege ...
- Python 系列:1 - Tuples and Sequences
5.3 Tuples and Sequences We saw that lists and strings have many common properties, e.g., indexing a ...
- Lists and tuples
zip is a built-in function that takes two or more sequence and ‘zips’ them into a list of tuples, wh ...
- python 03
数据结构 在 python 中有4种内建数据结构, 列表, 元组, 字典和集合. 列表 list 有序项目的数据结构, 类似数组, 是对象. 列表用中括号中用逗号分隔的项目定义.例如 ['apple' ...
- 【Python 03】程序设计与Python语言概述
人生苦短,我用Python. Python在1990年诞生于荷兰,2010年Python2发布最后一版2.7,Python核心团队计划在2020年停止支持 Python2,目前Python3是未来. ...
- python 03 字符串详解
1.制表符 \t str.expandtabs(20) 可相当于表格 2.def isalpha(self) 判断是否值包含字母(汉字也为真),不包含数字 3.def isdecimal(se ...
- headfirst python 03, 04
文件与异常 python中的输入机制是基于行的, open()函数与for 语句结合使用, 可以非常容易的读取文件.(打开->处理->关闭) #!/usr/bin/env python # ...
随机推荐
- thinkphp5 学习笔记
一.开发规范: 二.API: 1.数据输出:新版的控制器输出采用 Response 类统一处理,而不是直接在控制器中进行输出,通过设置 default_return_type 就可以自动进行数据转换处 ...
- Linux使用命令 笔记
1.解压缩 tar -zxvf hadoop.xx.tar.gz2.重命名 mv hadoop-1.1.2 hadoop 3.创建文件夹 mkdir 文件夹名 4.vi编辑器 在一般模式下输入“ZZ” ...
- spring cloud:Edgware.RELEASE版本中zuul回退方法的变化
Edgware.RELEASE以前的版本中,zuul网关中有一个ZuulFallbackProvider接口,代码如下: public interface ZuulFallbackProvider { ...
- Scala:Method 小技巧,忽略result type之后的等号
var x = 0 def IncreaseOne(): Int = { x += 1 x } def IncreaseOne() = { x += 1 x } def IncreaseOne = { ...
- 线程安全的CopyOnWriteArrayList介绍
证明CopyOnWriteArrayList是线程安全的 先写一段代码证明CopyOnWriteArrayList确实是线程安全的. ReadThread.java import java.util. ...
- python3 requests获取某网站折线图上数据
比如要抓取某网站折线图上数据,如下截图: 借助Chrome开发者工具Network.经过分析发现获取上面的热度数据,找到对应的事件url:https://pcw-api.iqiyi.com/video ...
- Std::map too few template arguments
在上述的代码中,红色波浪线的部分编译的时候报错: error C2976: 'std::map' : too few template arguments 换成std::map<std::str ...
- MDX Cookbook 06 - GENERATE 循环遍历
有时候需要从集合中取出特定的成员但是又不能执行遍历操作,这个时候就可以使用 GENERATE 函数来解决这个问题. 根据地区查询每年的销售额 - SELECT NON EMPTY { , NON EM ...
- 每天一个linux命令(1):pwd命令
1.命令简介 pwd(print work directory 打印当前目录)命令以绝对路径的方式显示用户当前工作目录. 2.用法 pwd [-LP] 3.选项 -L --logical 当目录为连接 ...
- 迁移ORACLE_HOME引发的登录sqlplus无法加载类库错误
在10g以后,一般情况下环境变量中没有必要设置LD_LIBRARY_PATH,但是一旦将ORACLE_HOME迁移到其他目录,则环境变量中还需要添加这个变量. Linux和Unix支持TAR方式迁移O ...