python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图
一、分析网站
1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏。
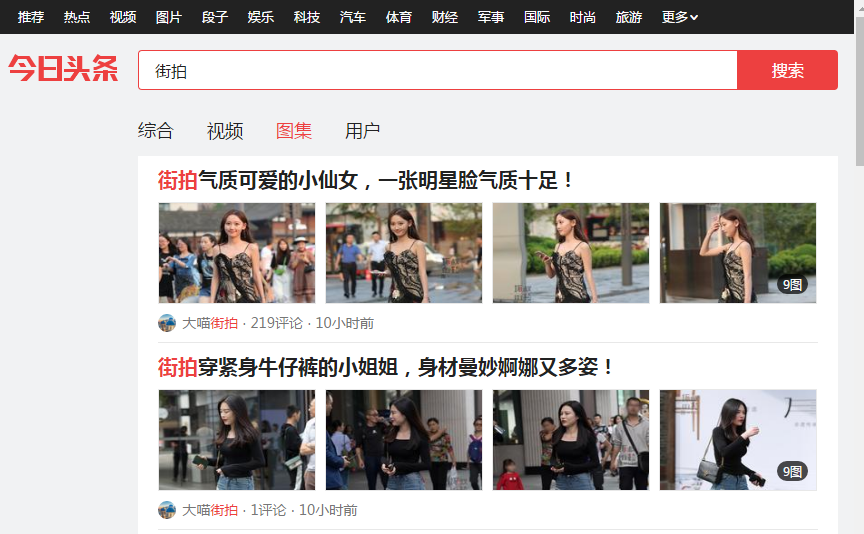
2.按F12打开开发者工具,刷新网页,这时网页回弹到综合这一栏,点击图集,在开发者工具中查看 XHR这个选项卡。
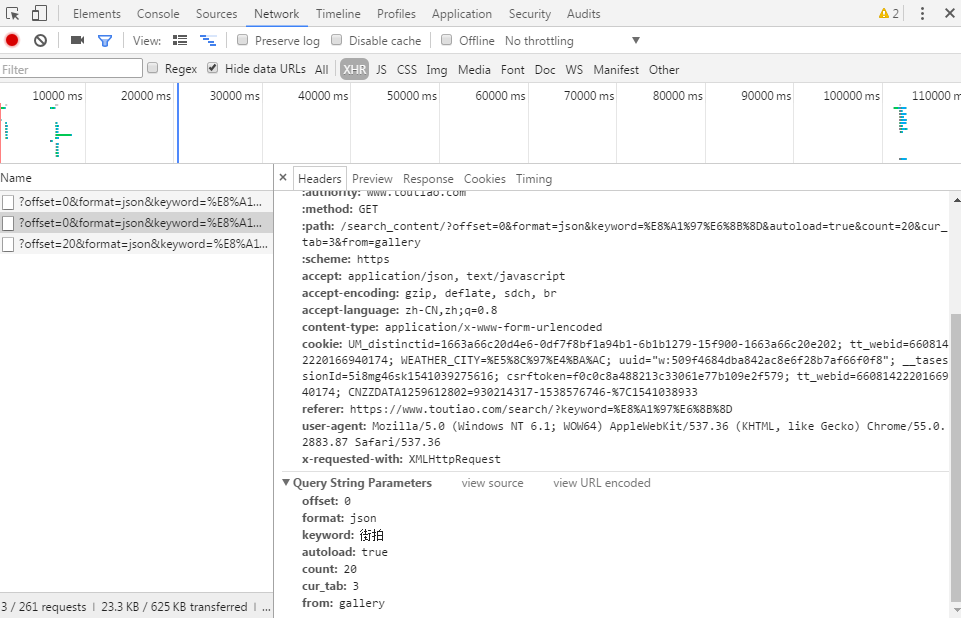
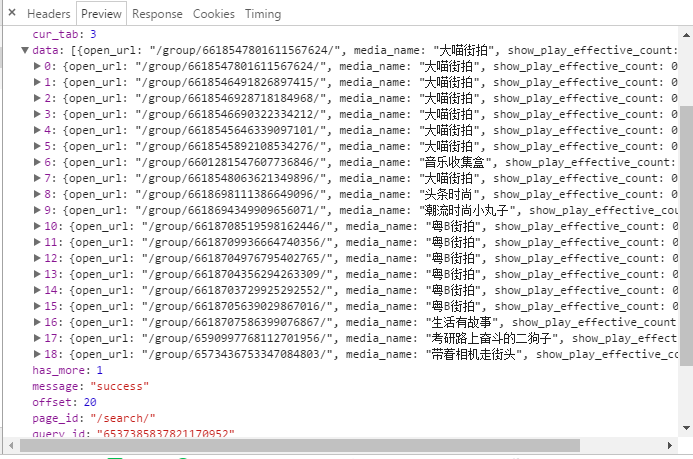
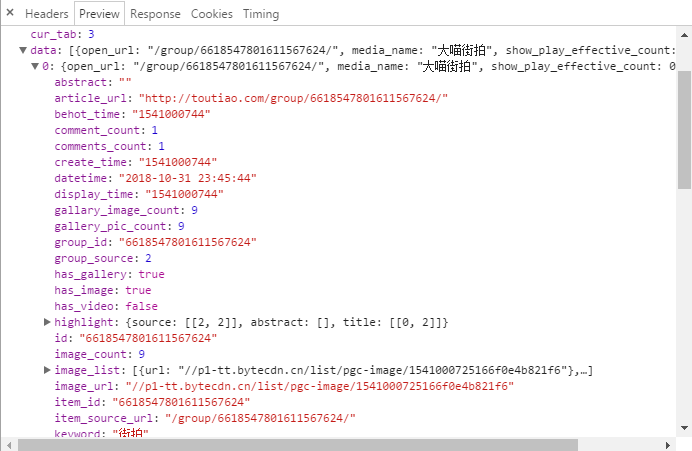
3.具体分析url,请求参数
当我们在请求图集这个页面时,url如下:

请求参数如下:
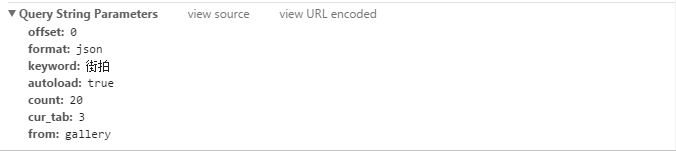
我们可以看到这个url的构成:
前面:https://www.toutiao.com/search_content/?
后面:offset=0&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=3&from=gallery
二、源代码
程序主体
import requests
from urllib.parse import urlencode
from requests.exceptions import RequestException
import json
import re
import os
import pymongo
from hashlib import md5
from bs4 import BeautifulSoup
from multiprocessing import Pool
from config import * #导入mongodb
client = pymongo.MongoClient(MOMGO_URL,connect=False)
#创建数据库对象
db = client[MOMGO_DB] #获取索引页内容
def get_page_index(offset,keyword):
#构造请求参数
data ={
'offset':offset,
'format':'json',
'keyword':keyword,
'autoload':'true',
'count':'20',
'cur_tab':'3',
'from':'gallery',
}
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko'}
#请求url, urlencode()将字典数据转为url请求
url = 'https://www.toutiao.com/search_content/?' + urlencode(data) try:
response = requests.get(url,headers=headers)
if response.status_code ==200:
return response.text
return None
except RequestException:
print('请求页出错')
return None #解析索引网页,获得详细页面url
def parse_page_index(html):
#解析json数据,转为json对象
data = json.loads(html)
#判断data是否存在,存在则返回所有的键名
if data and 'data' in data.keys():
for item in data.get('data'):
#提取article_url,把article_url循环取出来
yield item.get('article_url') #获取详细页面内容
def get_page_detail(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 QIHU 360SE'}
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求详细页出错')
return None #解析详细页面内容
def parse_page_Detail(html,url):
#生成BeautifulSoup对象,使用lxml解析
soup = BeautifulSoup(html,'lxml')
#匹配标题
title_pattern = re.compile('BASE_DATA.galleryInfo = {.*?title: (.*?),',re.S)
#匹配图片
images_pattern = re.compile('BASE_DATA.galleryInfo = {.*?gallery: JSON.parse\("(.*?)"\)',re.S)
result =re.search(images_pattern,html)
title = re.search(title_pattern,html)
if result:
data =json.loads(result.group(1).replace('\\',''))
#如果sub_images存在,返回所有键名
if data and 'sub_images' in data.keys():
#获取sub_images的所有内容
sub_images = data.get('sub_images')
#获取一组图,构造列表
images = [item.get('url') for item in sub_images]
#下载图片,保存图片
for image in images: down_images(image)
return {
'title':title.group(1),
'url':url,
'images':images
} def save_to_mongo(result):
if db[MOMG_TABLE].insert(result):
print('存储到mongodb成功')
return True
return False #下载图片
def down_images(url):
print('正在下载图片:'+ url)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 QIHU 360SE'}
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
sava_images(response.content)
return None
except RequestException:
print('请求图片出错')
return None #保存图片
def sava_images(content):
file_path = "{0}/{1}.{2}".format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(str(file_path),'wb') as f:
f.write(content)
f.close() def main(offset):
#获取索引页内容
#传入第一个变量为offset值,第二个为关键字,网页通过滑动,offset值会发生改变
html = get_page_index(offset,KEYWORD)
#解析索引页内容,获取详细页面URL
for url in parse_page_index(html):
#将详细页面内容赋值给html
html = get_page_detail(url)
#如果详细页面内容不为空,则解析详细内容
if html:
result = parse_page_Detail(html,url)
print(result)
if result:
save_to_mongo(result) if __name__=='__main__': groups = [x * 20 for x in range(GROUP_START,GROUP_END + 1)]
#创建进程池
pool=Pool()
#开启多进程
pool,map(main(offset=0), groups)
配置文件
#链接地址
MOMGO_URL='localhost'
#数据库名字
MOMGO_DB='toutiao'
#表名
MOMG_TABLE='toutiao' GROUP_START=1
GROUP_END=20
KEYWORD="街拍"
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)的更多相关文章
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- 分析Ajax请求并抓取今日头条街拍美图
项目说明 本项目以今日头条为例,通过分析Ajax请求来抓取网页数据. 有些网页请求得到的HTML代码里面并没有我们在浏览器中看到的内容.这是因为这些信息是通过Ajax加载并且通过JavaScript渲 ...
- 【Python3网络爬虫开发实战】 分析Ajax爬取今日头条街拍美图
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:haoxuan10 本节中,我们以今日头条为例来尝试通过分析Ajax请求 ...
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 爬虫(八):分析Ajax请求抓取今日头条街拍美图
(1):分析网页 分析ajax的请求网址,和需要的参数.通过不断向下拉动滚动条,发现请求的参数中offset一直在变化,所以每次请求通过offset来控制新的ajax请求. (2)上代码 a.通过aj ...
- 2.分析Ajax请求并抓取今日头条街拍美图
import requests from urllib.parse import urlencode # 引入异常类 from requests.exceptions import RequestEx ...
- 分析 ajax 请求并抓取今日头条街拍美图
首先分析街拍图集的网页请求头部: 在 preview 选项卡我们可以找到 json 文件,分析 data 选项,找到我们要找到的图集地址 article_url: 选中其中一张图片,分析 json 请 ...
随机推荐
- dbeaver can't connect HBase1.2 using phoenix driver #1863
1 第一个问题 Unexpected version format: 10.0.2 Unexpected version format: 10.0.2 Unexpected version forma ...
- python - 迭代器(迭代协议/可迭代对象)
迭代器 # 迭代器协议 # 迭代协议:对象必须提供一个next方法,执行该方法要么返回迭代中的下一项,要么就触发一个 StopIteration 异常,以终止迭代(只能往后走不能往前退) # 可迭代对 ...
- [转]xargs命令详解,xargs与管道的区别
为什么要用xargs,问题的来源 在工作中经常会接触到xargs命令,特别是在别人写的脚本里面也经常会遇到,但是却很容易与管道搞混淆,本篇会详细讲解到底什么是xargs命令,为什么要用xargs命令以 ...
- SpringBoot2.x过滤器Filter和使用Servlet3.0配置自定义Filter实战
补充:SpringBoot启动日志 1.深入SpringBoot2.x过滤器Filter和使用Servlet3.0配置自定义Filter实战(核心知识) 简介:讲解SpringBoot里面Filter ...
- SpringMVC——SpringMVC简介
Spring web mvc 和Struts2 都属于表现层的框架,它是Spring 框架的一部分,我们可以从Spring 的整体结构中看得出来:
- select 1
select 1 from mytable;与select anycol(目的表集合中的任意一行) from mytable;与select * from mytable 作用上来说是没有差别的,都是 ...
- 简单透彻理解JSONP原理及使用
首先提一下JSON这个概念,JSON是一种轻量级的数据传输格式,被广泛应用于当前Web应用中.JSON格式数据的编码和解析基本在所有主流语言中都被实现,所以现在大部分前后端分离的架构都以JSON格式进 ...
- W-GAN系 (Wasserstein GAN、 Improved WGAN)
学习总结于国立台湾大学 :李宏毅老师 WGAN前作:Towards Principled Methods for Training Generative Adversarial Networks W ...
- SSD win7优化步骤
随着固态硬盘价格不断下降,目前固态硬盘也得到了广泛了应用,一些新笔记本以及组装电脑也开始普遍采用固态硬盘平台,超级本就更不用说了,采用固态硬盘已经成标配化,虽然固态硬盘速度很快,但不懂的优化,依然无法 ...
- springboot系列七:springboot 集成 MyBatis、事物配置及使用、druid 数据源、druid 监控使用
一.MyBatis和druid简介 MyBatis 是一款优秀的持久层框架,它支持定制化 SQL.存储过程以及高级映射.MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集.M ...