OpenCV支持向量机(SVM)介绍
支持向量机(SVM)介绍
什么是支持向量机(SVM)?
支持向量机 (SVM) 是一个类分类器,正式的定义是一个能够将不同类样本在样本空间分隔的超平面。 换句话说,给定一些标记(label)好的训练样本 (监督式学习), SVM算法输出一个最优化的分隔超平面。
如何来界定一个超平面是不是最优的呢? 考虑如下问题:
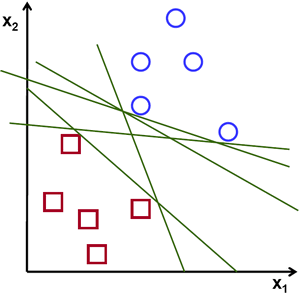
假设给定一些分属于两类的2维点,这些点可以通过直线分割, 我们要找到一条最优的分割线.
Note
在这个示例中,我们考虑卡迪尔平面内的点与线,而不是高维的向量与超平面。 这一简化是为了让我们以更加直觉的方式建立起对SVM概念的理解, 但是其基本的原理同样适用于更高维的样本分类情形。
在上面的图中, 你可以直觉的观察到有多种可能的直线可以将样本分开。 那是不是某条直线比其他的更加合适呢? 我们可以凭直觉来定义一条评价直线好坏的标准:
距离样本太近的直线不是最优的,因为这样的直线对噪声敏感度高,泛化性较差。 因此我们的目标是找到一条直线,离所有点的距离最远。
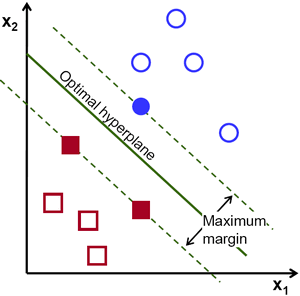
由此, SVM算法的实质是找出一个能够将某个值最大化的超平面,这个值就是超平面离所有训练样本的最小距离。这个最小距离用SVM术语来说叫做 间隔(margin) 。 概括一下,最优分割超平面 最大化 训练数据的间隔。
如何计算最优超平面?
下面的公式定义了超平面的表达式:
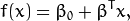
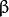 叫做 权重向量 ,
叫做 权重向量 , 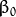 叫做 偏置(bias) 。
叫做 偏置(bias) 。
See also
关于超平面的更加详细的说明可以参考T. Hastie, R. Tibshirani 和 J. H. Friedman的书籍 Elements of Statistical Learning , section 4.5 (Seperating Hyperplanes)。
最优超平面可以有无数种表达方式,即通过任意的缩放 和 。 习惯上我们使用以下方式来表达最优超平面
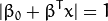
式中 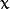 表示离超平面最近的那些点。 这些点被称为 支持向量**。 该超平面也称为 **canonical 超平面.
表示离超平面最近的那些点。 这些点被称为 支持向量**。 该超平面也称为 **canonical 超平面.
通过几何学的知识,我们知道点 到超平面 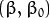 的距离为:
的距离为:
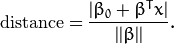
特别的,对于 canonical 超平面, 表达式中的分子为1,因此支持向量到canonical 超平面的距离是
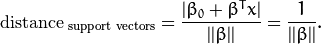
刚才我们介绍了间隔(margin),这里表示为 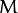 , 它的取值是最近距离的2倍:
, 它的取值是最近距离的2倍:
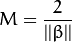
最后最大化 转化为在附加限制条件下最小化函数 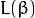 。 限制条件隐含超平面将所有训练样本
。 限制条件隐含超平面将所有训练样本 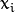 正确分类的条件,
正确分类的条件,

式中 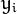 表示样本的类别标记。
表示样本的类别标记。
这是一个拉格朗日优化问题,可以通过拉格朗日乘数法得到最优超平面的权重向量 和偏置 。
源码
1 |
#include <opencv2/core/core.hpp> |
解释
- 建立训练样本
本例中的训练样本由分属于两个类别的2维点组成, 其中一类包含一个样本点,另一类包含三个点。
float labels[4] = {1.0, -1.0, -1.0, -1.0};
float trainingData[4][2] = {{501, 10}, {255, 10}, {501, 255}, {10, 501}};函数 CvSVM::train 要求训练数据储存于float类型的 Mat 结构中, 因此我们定义了以下矩阵:
Mat trainingDataMat(3, 2, CV_32FC1, trainingData);
Mat labelsMat (3, 1, CV_32FC1, labels);
设置SVM参数
此教程中,我们以可线性分割的分属两类的训练样本简单讲解了SVM的基本原理。 然而,SVM的实际应用情形可能复杂得多 (比如非线性分割数据问题,SVM核函数的选择问题等等)。 总而言之,我们需要在训练之前对SVM做一些参数设定。 这些参数保存在类 CvSVMParams 中。
CvSVMParams params;
params.svm_type = CvSVM::C_SVC;
params.kernel_type = CvSVM::LINEAR;
params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 100, 1e-6);SVM类型. 这里我们选择了 CvSVM::C_SVC 类型,该类型可以用于n-类分类问题 (n
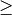 2)。 这个参数定义在 CvSVMParams.svm_type 属性中.
2)。 这个参数定义在 CvSVMParams.svm_type 属性中.Note
CvSVM::C_SVC 类型的重要特征是它可以处理非完美分类的问题 (及训练数据不可以完全的线性分割)。在本例中这一特征的意义并不大,因为我们的数据是可以线性分割的,我们这里选择它是因为它是最常被使用的SVM类型。
SVM 核类型. 我们没有讨论核函数,因为对于本例的样本,核函数的讨论没有必要。然而,有必要简单说一下核函数背后的主要思想, 核函数的目的是为了将训练样本映射到更有利于可线性分割的样本集。 映射的结果是增加了样本向量的维度,这一过程通过核函数完成。 此处我们选择的核函数类型是 CvSVM::LINEAR 表示不需要进行映射。 该参数由 CvSVMParams.kernel_type 属性定义。
算法终止条件. SVM训练的过程就是一个通过 迭代 方式解决约束条件下的二次优化问题,这里我们指定一个最大迭代次数和容许误差,以允许算法在适当的条件下停止计算。 该参数定义在 cvTermCriteria 结构中。
训练支持向量机
调用函数 CvSVM::train 来建立SVM模型。
CvSVM SVM;
SVM.train(trainingDataMat, labelsMat, Mat(), Mat(), params);SVM区域分割
函数 CvSVM::predict 通过重建训练完毕的支持向量机来将输入的样本分类。 本例中我们通过该函数给向量空间着色, 及将图像中的每个像素当作卡迪尔平面上的一点,每一点的着色取决于SVM对该点的分类类别:绿色表示标记为1的点,蓝色表示标记为-1的点。
Vec3b green(0,255,0), blue (255,0,0); for (int i = 0; i < image.rows; ++i)
for (int j = 0; j < image.cols; ++j)
{
Mat sampleMat = (Mat_<float>(1,2) << i,j);
float response = SVM.predict(sampleMat); if (response == 1)
image.at<Vec3b>(j, i) = green;
else
if (response == -1)
image.at<Vec3b>(j, i) = blue;
}
支持向量
这里用了几个函数来获取支持向量的信息。 函数 CvSVM::get_support_vector_count 输出支持向量的数量,函数 CvSVM::get_support_vector 根据输入支持向量的索引来获取指定位置的支持向量。 通过这一方法我们找到训练样本的支持向量并突出显示它们。
int c = SVM.get_support_vector_count(); for (int i = 0; i < c; ++i)
{
const float* v = SVM.get_support_vector(i); // get and then highlight with grayscale
circle( image, Point( (int) v[0], (int) v[1]), 6, Scalar(128, 128, 128), thickness, lineType);
}
结果
- 程序创建了一张图像,在其中显示了训练样本,其中一个类显示为白色圆圈,另一个类显示为黑色圆圈。
- 训练得到SVM,并将图像的每一个像素分类。 分类的结果将图像分为蓝绿两部分,中间线就是最优分割超平面。
- 最后支持向量通过灰色边框加重显示。

翻译者¶
niesu@ OpenCV中文网站 <sisongasg@hotmail.com>
from: http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/ml/introduction_to_svm/introduction_to_svm.html#introductiontosvms
OpenCV支持向量机(SVM)介绍的更多相关文章
- OpenCV支持向量机SVM对线性不可分数据的处理
支持向量机对线性不可分数据的处理 目标 本文档尝试解答如下问题: 在训练数据线性不可分时,如何定义此情形下支持向量机的最优化问题. 如何设置 CvSVMParams 中的参数来解决此类问题. 动机 为 ...
- opencv 支持向量机SVM分类器
支持向量机SVM是从线性可分情况下的最优分类面提出的.所谓最优分类,就是要求分类线不但能够将两类无错误的分开,而且两类之间的分类间隔最大,前者是保证经验风险最小(为0),而通过后面的讨论我们看到,使分 ...
- 支持向量机SVM介绍
SVM为了达到更好的泛化效果,会构建具有"max-margin"的分类器(如下图所示),即最大化所有类里面距离超平面最近的点到超平面的距离,数学公式表示为$$\max\limits ...
- OPENCV SVM介绍和自带例子
依据机器学习算法如何学习数据可分为3类:有监督学习:从有标签的数据学习,得到模型参数,对测试数据正确分类:无监督学习:没有标签,计算机自己寻找输入数据可能的模型:强化学习(reinforcement ...
- OpenCV 学习笔记 07 支持向量机SVM(flag)
1 SVM 基本概念 本章节主要从文字层面来概括性理解 SVM. 支持向量机(support vector machine,简SVM)是二类分类模型. 在机器学习中,它在分类与回归分析中分析数据的监督 ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
- 以图像分割为例浅谈支持向量机(SVM)
1. 什么是支持向量机? 在机器学习中,分类问题是一种非常常见也非常重要的问题.常见的分类方法有决策树.聚类方法.贝叶斯分类等等.举一个常见的分类的例子.如下图1所示,在平面直角坐标系中,有一些点 ...
- 一步步教你轻松学支持向量机SVM算法之案例篇2
一步步教你轻松学支持向量机SVM算法之案例篇2 (白宁超 2018年10月22日10:09:07) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 一步步教你轻松学支持向量机SVM算法之理论篇1
一步步教你轻松学支持向量机SVM算法之理论篇1 (白宁超 2018年10月22日10:03:35) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
随机推荐
- 配置本地无密码 SSH登录远程服务器
下面这幅图简单来说就是你本地有一把钥匙,服务器也有一把钥匙,当登录的时候本地的钥匙与服务器的进行对比,通过算法的判定,监测是否具有权限的用户 第一步,在本地配置这把钥匙生成私钥与公钥: 打开.ssh目 ...
- C++ code:浮点数的比较(Floating-Pointing Number Comparison)
浮点数可以进行比较,但是浮点数由于表示精度在不同浮点数类型中的差异,所以会被误用.例如: #include <iostream> using namespace std; int main ...
- linux 创建用户和密码
:useradd -m 用户名//添加用户 :passwd 用户名 //然后设置密码 :userdel -r newuser1 //删除用户 newuser1,同时删除其自家目录 samba 设置账号 ...
- python 线程间通信之Condition, Queue
Event 和 Condition 是threading模块原生提供的模块,原理简单,功能单一,它能发送 True 和 False 的指令,所以只能适用于某些简单的场景中. 而Queue则是比较高级的 ...
- [转] Sublime Text3 配置 NodeJs 环境
前言 大家都知道,Sublime Text 安装插件一般从 Package Control 中直接安装即可,当我安装 node js 插件时候,直接通过Package Control 安装,虽然插件安 ...
- 023 SpringMVC拦截器
一:拦截器的HelloWorld 1.首先自定义拦截器 只要实现接口就行. package com.spring.it.interceptors; import javax.servlet.http. ...
- 068 Oozie任务调度框架
一:概述 1.大数据协作框架 2.Hadoop的任务调度 这个是常见的任务调度框架. 3.azkaban 4..Oozie的三大功能 Oozie Workflow jobs :工作流任务,可以生成DA ...
- [OpenCV-Python] OpenCV 中的图像处理 部分 IV (四)
部分 IVOpenCV 中的图像处理 OpenCV-Python 中文教程(搬运)目录 21 OpenCV 中的轮廓 21.1 初识轮廓目标 • 理解什么是轮廓 • 学习找轮廓,绘制轮廓等 • 函数: ...
- vue+axios实现移动端图片上传
在利用vue做一些H5页面时,或多或少会遇到有图片上传的操作,主要是运用html5里面的input[type=file]来实现,传递到后端的数据是以二进制的格式传递,所以上传图片的请求与普通的请求稍微 ...
- 基于Vue.js的uni-app前端框架结合.net core开发跨平台project
一.由来 最近由于业务需要要开发一套公益的APP项目,因此结合所给出的需求最终采用uni-app这种跨平台前端框架以及.netcore快速搭建我们的项目,并且能做到一套代码跨多个平台. 当然在前期技术 ...