神经网络优化算法如何选择Adam,SGD
之前在tensorflow上和caffe上都折腾过CNN用来做视频处理,在学习tensorflow例子的时候代码里面给的优化方案默认很多情况下都是直接用的AdamOptimizer优化算法,如下:
optimizer = tf.train.AdamOptimizer(learning_rate=lr).minimize(cost)- 1
但是在使用caffe时solver里面一般都用的SGD+momentum,如下:
base_lr: 0.0001
momentum: 0.9
weight_decay: 0.0005
lr_policy: "step"- 1
- 2
- 3
- 4
加上最近看了一篇文章:The Marginal Value of Adaptive Gradient Methods
in Machine Learning文章链接,文中也探讨了在自适应优化算法:AdaGrad, RMSProp, and Adam和SGD算法性能之间的比较和选择,因此在此搬一下结论和感想。
Abstract
经过本文的实验,得出最重要的结论是:
We observe that the solutions found by adaptive methods generalize worse (often significantly worse) than SGD, even when these solutions have better training performance. These
results suggest that practitioners should reconsider the use of adaptive methods to train neural
networks- 1
- 2
- 3
翻译一下就是自适应优化算法通常都会得到比SGD算法性能更差(经常是差很多)的结果,尽管自适应优化算法在训练时会表现的比较好,因此使用者在使用自适应优化算法时需要慎重考虑!(终于知道为啥CVPR的paper全都用的SGD了,而不是用理论上最diao的Adam)
Introduction
作者继续给了干货结论:
Our experiments reveal three primary findings.
First,
with the same amount of hyperparameter tuning, SGD and SGD with momentum outperform
adaptive methods on the development/test set across all evaluated models and tasks. This is
true even when the adaptive methods achieve the same training loss or lower than non-adaptive
methods. Second, adaptive methods often display faster initial progress on the training set, but
their performance quickly plateaus on the development/test set. Third, the same amount of tuning
was required for all methods, including adaptive methods. This challenges the conventional wisdom
that adaptive methods require less tuning. - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
翻译:
1:用相同数量的超参数来调参,SGD和SGD +momentum 方法性能在测试集上的额误差好于所有的自适应优化算法,尽管有时自适应优化算法在训练集上的loss更小,但是他们在测试集上的loss却依然比SGD方法高,
2:自适应优化算法 在训练前期阶段在训练集上收敛的更快,但是在测试集上这种有点遇到了瓶颈。
3:所有方法需要的迭代次数相同,这就和约定俗成的默认自适应优化算法 需要更少的迭代次数的结论相悖!
Conclusion
贴几张作者做的实验结果图:
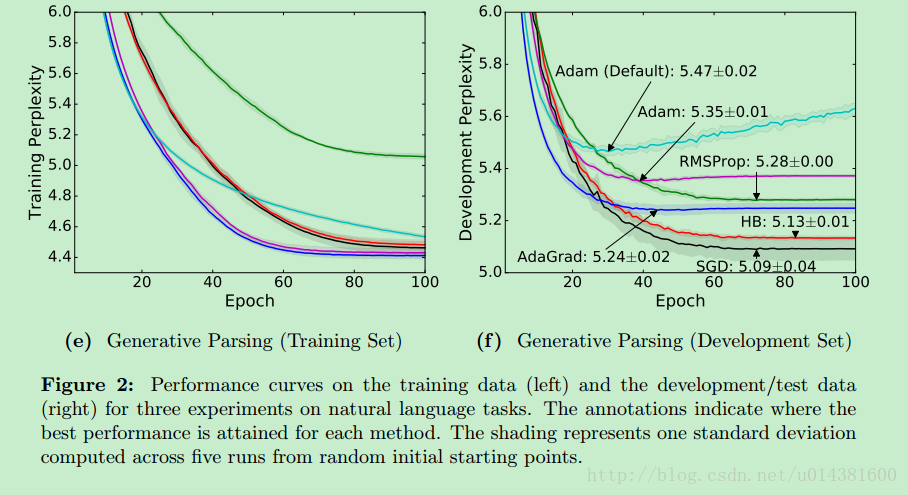
可以看到SGD在训练前期loss下降并不是最快的,但是在test set上的Perplexity 困惑度(这里写链接内容)是最小的。
在tensorflow中使用SGD算法:(参考)
# global_step
training_iters=len(data_config['train_label'])
global_step=training_iters*model_config['n_epoch']
decay_steps=training_iters*1
#global_step = tf.Variable(0, name = 'global_step', trainable=False)
lr=tf.train.exponential_decay(learning_rate=model_config['learning_rate'],
global_step=global_step, decay_steps=decay_steps, decay_rate=0.1, staircase=False, name=None)
optimizer=tf.train.GradientDescentOptimizer(lr).minimize(cost,var_list=network.all_params)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
神经网络优化算法如何选择Adam,SGD的更多相关文章
- 神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
最近回顾神经网络的知识,简单做一些整理,归档一下神经网络优化算法的知识.关于神经网络的优化,吴恩达的深度学习课程讲解得非常通俗易懂,有需要的可以去学习一下,本人只是对课程知识点做一个总结.吴恩达的深度 ...
- 神经网络优化算法:Dropout、梯度消失/爆炸、Adam优化算法,一篇就够了!
1. 训练误差和泛化误差 机器学习模型在训练数据集和测试数据集上的表现.如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不⼀定更准确.这是为什么呢 ...
- 机器学习之路: 深度学习 tensorflow 神经网络优化算法 学习率的设置
在神经网络中,广泛的使用反向传播和梯度下降算法调整神经网络中参数的取值. 梯度下降和学习率: 假设用 θ 来表示神经网络中的参数, J(θ) 表示在给定参数下训练数据集上损失函数的大小. 那么整个优化 ...
- Adam那么棒,为什么还对SGD念念不忘 (3)—— 优化算法的选择与使用策略
在前面两篇文章中,我们用一个框架梳理了各大优化算法,并且指出了以Adam为代表的自适应学习率优化算法可能存在的问题.那么,在实践中我们应该如何选择呢? 本文介绍Adam+SGD的组合策略,以及一些比较 ...
- 【零基础】神经网络优化之Adam
一.序言 Adam是神经网络优化的另一种方法,有点类似上一篇中的“动量梯度下降”,实际上是先提出了RMSprop(类似动量梯度下降的优化算法),而后结合RMSprop和动量梯度下降整出了Adam,所以 ...
- Tensorflow学习:(三)神经网络优化
一.完善常用概念和细节 1.神经元模型: 之前的神经元结构都采用线上的权重w直接乘以输入数据x,用数学表达式即,但这样的结构不够完善. 完善的结构需要加上偏置,并加上激励函数.用数学公式表示为:.其中 ...
- zz图像、神经网络优化利器:了解Halide
动图示例实在太好 图像.神经网络优化利器:了解Halide Oldpan 2019年4月17日 0条评论 1,327次阅读 3人点赞 前言 Halide是用C++作为宿主语言的一个图像处理相 ...
- (转载)微软数据挖掘算法:Microsoft 神经网络分析算法(10)
前言 有段时间没有进行我们的微软数据挖掘算法系列了,最近手头有点忙,鉴于上一篇的神经网络分析算法原理篇后,本篇将是一个实操篇,当然前面我们总结了其它的微软一系列算法,为了方便大家阅读,我特地整理了一篇 ...
- Halide视觉神经网络优化
Halide视觉神经网络优化 概述 Halide是用C++作为宿主语言的一个图像处理相关的DSL(Domain Specified Language)语言,全称领域专用语言.主要的作用为在软硬层面上( ...
随机推荐
- Xception网络结构理解
Xception网络是由inception结构加上depthwise separable convlution,再加上残差网络结构改进而来/ 常规卷积是直接通过一个卷积核把空间信息和通道信息直接提取出 ...
- IntelliJ IDEA 2017.3/2018.1 激活
传统的License Server方式已经无法注册IntelliJ IDEA2017.3的版本了. http://idea.lanyus.com,这个网站有破解补丁和注册码两种方式,另外http:// ...
- 8.Thread的join方法
1.Thread类的join方法表示:当前线程执行结束再执行其它线程!在Thread类中有三个重载的方法分别是: public final synchronized void join(long mi ...
- Sitecore CMS中配置模板部分
如何在Sitecore CMS中配置模板部分. 注意: 本教程将扩展于“Sitecore CMS中创建模板”的章节. 配置折叠状态 配置模板部分的折叠状态允许用户选择默认折叠或展开哪些模板部分.此设置 ...
- 【Hive学习之八】Hive 调优【重要】
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 apache-hive-3.1.1 ...
- python 类似java的三目运算符
python中没有其他语言中的三元表达式,不过有类似的实现方法 其他语言中,例如java的三元表达式是这样 int a = 1; String b = ""; b = a > ...
- TensorFlow入门,基本介绍,基本概念,计算图,pip安装,helloworld示例,实现简单的神经网络
TensorFlow入门,基本介绍,基本概念,计算图,pip安装,helloworld示例,实现简单的神经网络
- 关于js闭包之小问题大错误
闭包是 JavaScript 开发的一个关键方面:匿名函数可以访问父级作用域的变量. 如果闭包的作用域中保存着一个 HTML 元素,则该元素无法被销毁.(下面代码来自高程) 刚看到一个关于闭包自己没注 ...
- render函数
vue2.0之render函数 虽然vue推荐用template来创建你的html,但是在某些时候你也会用到render函数. 虚拟DOM Vue 通过建立一个虚拟 DOM 对真实 DOM 发生的 ...
- 算法训练 P0505
一个整数n的阶乘可以写成n!,它表示从1到n这n个整数的乘积.阶乘的增长速度非常快,例如,13!就已经比较大了,已经无法存放在一个整型变量中:而35!就更大了,它已经无法存放在一个浮点型变量中.因此, ...