Hive数据类型及文本文件数据编码
本文参考Apache官网,更多内容请参考:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
1. 数值型
| 类型 | 支持范围 |
|---|---|
| TINYINT | 1-byte signed integer, from -128 to 127 |
| SMALLINT | 2-byte signed integer, from -32,768 to 32,767 |
| INT/INTEGER | 4-byte signed integer, from -2,147,483,648 to 2,147,483,647 |
| BIGINT | 8-byte signed integer, from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 |
| FLOAT | 4-byte single precision floating point number |
| DOUBLE | 8-byte double precision floating point number |
| DOUBLE | PRECISION |
| DECIMAL | Decimal datatype was introduced in Hive 0.11.0 (HIVE-2693) and revised in Hive 0.13.0 (HIVE-3976) |
1. Integral Types (TINYINT, SMALLINT, INT/INTEGER, BIGINT)
默认情况下,整数型为INT型,当数字大于INT型的范围时,会自动解释执行为BIGINT,或者使用以下后缀进行说明。
| 类型 | 后缀 | 例子 |
|---|---|---|
| TINYINT | Y | 100Y |
| SMALLINT | S | 100S |
| BIGINT | L | 100L |
INTEGER is introduced as a synonym for INT in Hive 2.2.0 (HIVE-14950).
2. Decimals
Hive的小数型是基于Java BigDecimal做的, BigDecimal在java中用于表示任意精度的小数类型。所有常规数字运算(例如+, - ,*,/)和相关的UDFs(例如Floor,Ceil,Round等等)都使用和支持Decimal。你可以将Decimal和其他数值型互相转换,且Decimal支持科学计数法和非科学计数法。因此,无论您的数据集是否包含如4.004E + 3(科学记数法)或4004(非科学记数法)或两者的组合的数据,可以使用Decimal。
从Hive 0.13开始,用户可以使用DECIMAL(precision, scale) 语法在创建表时来定义Decimal数据类型的precision和scale。 如果未指定precision,则默认为10。如果未指定scale,它将默认为0(无小数位)。
CREATE TABLE foo (
a DECIMAL, – Defaults to decimal(10,0)
b DECIMAL(9, 7)
)
大于BIGINT的数值,需要使用BD后缀以及Decimal(38,0)来处理,例:
select CAST(18446744073709001000BD AS DECIMAL(38,0)) from my_table limit 1;
Decimal在Hive 0.12.0 and 0.13.0之间是不兼容的,故0.12前的版本需要迁移才可继续使用,具体情况参见官网。
2. 日期型
| 类型 | 支持版本 |
|---|---|
| TIMESTAMP | Note: Only available starting with Hive 0.8.0 |
| DATE | Note: Only available starting with Hive 0.12.0 |
| INTERVAL | Note: Only available starting with Hive 1.2.0 |
1. Timestamps
支持传统的UNIX时间戳和可选的纳秒精度。
- 支持的转化:
- 整数数字类型:以秒为单位解释为UNIX时间戳
- 浮点数值类型:以秒为单位解释为UNIX时间戳,带小数精度
- 字符串:符合JDBC java.sql.Timestamp格式“YYYY-MM-DD HH:MM:SS.fffffffff”(9位小数位精度)
时间戳被解释为无时间的,并被存储为从Unix纪元的偏移量。 提供了用于转换到和从时区转换的便捷UDFs(to_utc_timestamp,from_utc_timestamp)。
所有现有的日期时间UDFs(月,日,年,小时等)都使用TIMESTAMP数据类型。
Text files中的时间戳必须使用格式yyyy-mm-dd hh:mm:ss [.f …]。 如果它们是另一种格式,请将它们声明为适当的类型(INT,FLOAT,STRING等),并使用UDF将它们转换为时间戳。
在表级别上,可以通过向SerDe属性”timestamp.formats”(自版本1.2.0 with HIVE-9298)提供格式来支持备选时间戳格式。 例如,yyyy-MM-dd’T’HH:mm:ss.SSS,yyyy-MM-dd’T’HH:mm:ss。
2. Dates
DATE值描述特定的年/月/日,格式为YYYY-MM-DD。 例如,DATE’2013-01-01’。 日期类型没有时间组件。 Date类型支持的值范围是0000-01-01到9999-12-31,这取决于Java Date类型的原始支持。
Date types只能在Date, Timestamp, or String types之间转换。
| 转换类型 | 结果 |
|---|---|
| cast(date as date) | Same date value |
| cast(date as string) | The year/month/day represented by the Date is formatted as a string in the form ‘YYYY-MM-DD’. |
| cast(date as timestamp) | A timestamp value is generated corresponding to midnight of the year/month/day of the date value, based on the local timezone. |
| cast(string as date) | If the string is in the form ‘YYYY-MM-DD’, then a date value corresponding to that year/month/day is returned. If the string value does not match this formate, then NULL is returned. |
| cast(timestamp as date) | The year/month/day of the timestamp is determined, based on the local timezone, and returned as a date value. |
3. Intervals
时间间隔在1.2.0之后版本支持,在2.2.0版本上进行了扩展,具体情况参见官网。
3. 字符型
1.Strings
字符串文字可以用单引号(’)或双引号(“)表示。Hive在字符串中使用C风格的转义。
2. Varchar
Varchar类型使用长度说明符(介于1和65355之间)创建,它定义字符串中允许的最大字符数。 如果要转换/分配给varchar值的字符串值超过length说明符,则字符串将被静默截断。 字符长度由字符串包含的代码点的数量确定。
像字符串一样,尾部空格在varchar中很重要,并且会影响比较结果。
非通用UDFs不能直接使用varchar类型作为输入参数或返回值。 可以创建字符串UDFs,而varchar值将被转换为strings并传递到UDF。 要直接使用varchar参数或返回varchar值,请创建GenericUDF。
如果基于reflection-based方法来获取数据类型信息,则可能存在不支持varchar的场景。 这包括一些SerDe函数实现。
3. Char
字符类型与Varchar类似,但它们是固定长度的,意味着比指定长度值短的值用空格填充,但尾随空格在比较期间不重要。 最大长度固定为255。
CREATE TABLE foo (bar CHAR(10))
4. 其他
- BOOLEAN
- BINARY (Note: Only available starting with Hive 0.8.0)
所有这些数据类型都是对java中接口的实现,因为这些类型的具体行为细节和Java中对应的类型是完全一致的。例如,String类型实现的是java中的String,FLOAT实现的是java中的float,等等。
5. 复杂类型(集合数据类型)
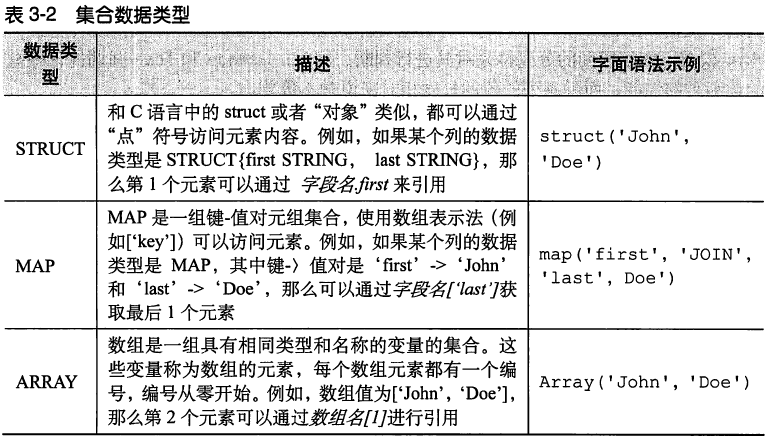
Hive中的列支持使用struct,map和array集合数据类型。语法示例实际上调用的是内置函数。和基本数据类型一样,这些类型同样是保留字。
| 类型 | 支持版本 | |
|---|---|---|
| arrays | ARRAY(data_type) | Note: negative values and non-constant expressions are allowed as of Hive 0.14. |
| maps | MAP(primitive_type, data_type) | Note: negative values and non-constant expressions are allowed as of Hive 0.14. |
| structs | STRUCTcol_name : data_type [COMMENT col_comment], …) | |
| union | UNIONTYPE(data_type, data_type, …) | Note: Only available starting with Hive 0.7.0. |
复杂类型包括ARRAY,MAP,STRUCT,UNION,这些复杂类型是由基础类型组成的。
MAP:MAP包含key->value键值对,可以通过key来访问元素。比如”userlist”是一个map类型,其中username是key,password是value;那么我们可以通过userlist['username']来得到这个用户对应的password;
STRUCT:STRUCT可以包含不同数据类型的元素。这些元素可以通过”点语法”的方式来得到所需要的元素,比如user是一个STRUCT类型,那么可以通过user.address得到这个用户的地址。
UNION: UNIONTYPE,他是从Hive 0.7.0开始支持的。
示例:一张虚构的人力资源应用程序中的员工表:
CREATE TABLE employees (
name STIRNG,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING, FLOAT>,
address STRUCT<street:STRING, city:STRING,state:STRING,zip:INT>);
说明:
subordinates 下属员工,是个数组,
deductions 扣除额:是一个map,记录每次的扣除额
address:雇员地址,使用struct数据类型存储,其中每个城都被作了命名,并且具有一个特定类型。
集合类型也可以嵌套使用,类似如:ARRAY<STRUCT>表示数组中的每个元素都是STRUCT结构。
文本文件数据编码
hive书用几个很少出现在字段值中的控制字符,使用术语field来表示替换默认分隔符的字符
常使用分隔符
| 分隔符 | 名称 | 说明 |
|---|---|---|
| \n | 换行符 | 对于文本文件而言,每一行是一条记录,因此换行符可以分割数据。 |
| ^A | <Ctrl>+A |
常用于分隔列,在CREATE TABLE语句中可以使用八进制编码\001表示。 |
| ^B | <Ctrl>+B |
常用于分隔ARRAY与STRUCT元素,或用于MAP中键值对之间的分隔。CREATE TABLE语句中可以使用八进制编码\002表示 |
| ^C | <Ctrl+C> |
MAP中键值对的分隔。 |
| \t | 制表符 | 常用 |
| , | 逗号 | 常用 |
在使用的过程中,可以不使用Hive提供的默认分隔符,而使用其他的分隔符。
Hive数据类型及文本文件数据编码的更多相关文章
- Hive 数据类型与文件格式
一.基本数据类型 1.基本数据类型 Tinyint 1byte有符号整数 比如20 Smalint 2byte有符号整数 比如20 Int 4byte有符号整数 比如20 Big ...
- Hive数据类型与文件存储格式
Hive数据类型 基础数据类型: TINYINT,SMALLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE,STRING,BINARY,TIMESTAMP,DECIMAL,CH ...
- Hive基础之Hive数据类型
Hive数据类型 参考:中文博客:http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2843448.html 英文:https: ...
- [Hive_add_2] Hive 数据类型
Hive 数据类型 正常数据类型 # 整型,4个字节 int # 大整型,8个字节 bigint # 字符串,最大长度2G String 复杂数据类型 # 数组,相同类型元素的数组 array< ...
- Hive 数据类型及操作数据库
3. Hive 数据类型 3.1 基本数据类型 Hive 数据类型 Java 数据类型 长度 TINYINT byte 1 byte 有符号整数 SMALINT short 2 byte 有符号整数 ...
- Hive 数据类型 + Hive sql
Hive 数据类型 + Hive sql 基本类型 整型 int tinyint (byte) smallint(short) bigint(long) 浮点型 float double 布尔 boo ...
- 第3章 Hive数据类型
第3章 Hive数据类型 3.1 基本数据类型 对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB ...
- 自定义hive文件和记录格式及文本文件数据编码
(1)一段 建表语句: [ROW FORMAT row_format] [STORED AS file_format] | STORED BY 'storage.handler.class.name' ...
- hive数据类型学习
Hive的内置数据类型可以分为两大类:(1).基础数据类型:(2).复杂数据类型.其中,基础数据类型包括: TINYINT, SMALLINT, INT, BIGINT, BOOLEAN, FLOAT ...
随机推荐
- java transient 知识点学习
今天看源码的时候看到这个关键字,完全没见过,不懂.好吧!学习一下. 我们都知道实现了Serilizable接口的类,便可以序列化,那么其中某些成员变量不想被序列化怎么办?就是利用transient这个 ...
- ionic后台返回的数据是html模板的时候,解析html文件的方法:
1.后台返回来的数据格式是: { "state":"100", "data":[ {"Content": "\ ...
- JavaEE开发的颠覆者 Spring Boot实战--笔记
1.Spring boot的三种启动模式 Spring 的问题 Spring boot的特点,没有特别的地方 1.Spring 基础 PS:关于spring配置 PS: 现在都已经使用 java配置, ...
- xencenter如何安装系统
首先点击增加服务器 输入xenserver的ip和用户名以及密码 添加资源池,注意下面那个add new server也要指定一个server,例如刚刚创建的那个 还要搞一个存储的,注意iso要选择s ...
- 关于kafka的新的group无法订阅到topic中历史消息的问题
今天在写kafka的java api例子时候,遇到一个问题,比如我创建了一个test主题,往里面写了1,2,3,4,5条消息,在这个时候,我用一个新的group启动了一个消费者,发现该消费者只能读到5 ...
- 区块链 blockchain
区块链是去中心化的记账方式.没有中心,安全,高效.区块链是属于分布式计算的一种.是一种数据库. 区块链不是什么比特币,xx币.而是比特币他们用了区块链的技术. 区块链具有去中心化.无须中心信任.不可篡 ...
- 理解Lambda表达式和闭包
了解由函数指针到Lambda表达式的演化过程 Lambda表达式的这种简洁的语法并不是什么古老的秘法,因为它并不难以理解(难以理解的代码只有一个目的,那就是吓唬程序员) #include " ...
- DevExpress开发win8风格界面
由于近期在对项目软件界面进行优化,找到了一款效果挺炫的插件,DevExpress15.2,可以制作win8可以滑动图标那个界面的效果,不多说,先贴图: (你没看错,这是用C#winform实现的) 可 ...
- day4 大纲笔记
01 上周内容回顾 int bool str int <---> str: i1 = 100 str(i1) s1 = '10' int(s1) 字符串必须是数字组成. int <- ...
- hadoop 常见 命令
一 hadoop namenode 命令 1 格式化namanode 磁盘 hadoop namenode -format 二 hadoop fs 命令 和 linux 命令 非常类似 ...