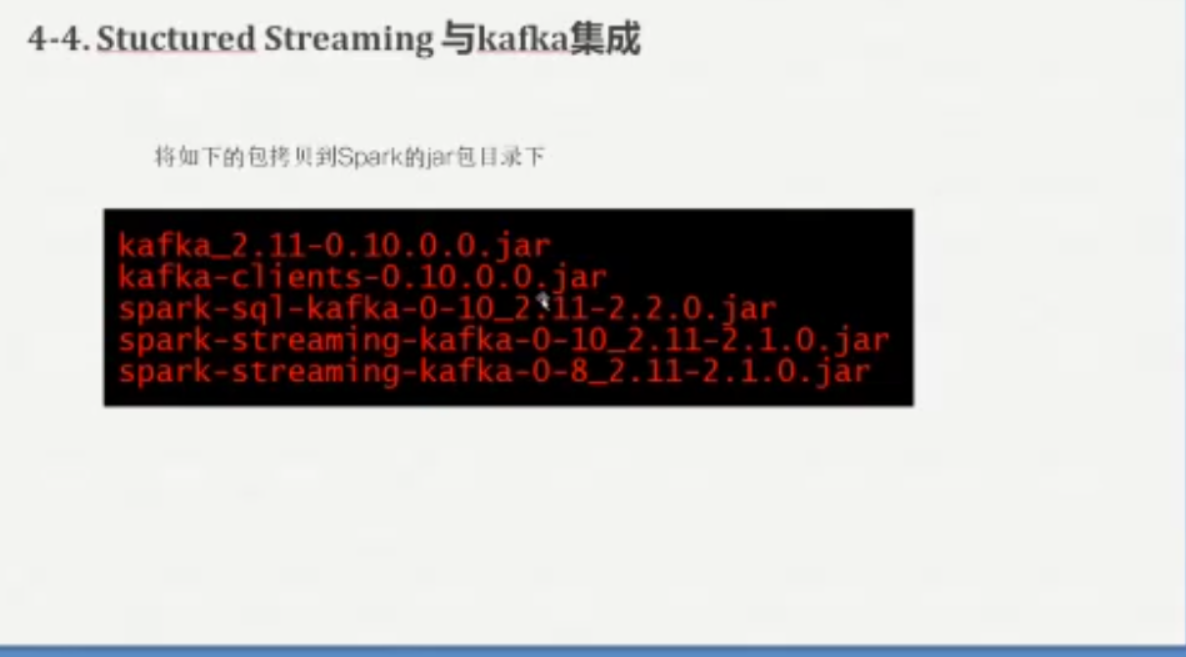
StructureStreaming与kafka集成读取数据必要的jar包
<dependency>
<!--structurStreaming读取kafka1.0以下必须的jar-->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>2.2.1</version>
</dependency>
StructureStreaming与kafka集成读取数据必要的jar包的更多相关文章
- Kafka消费者 从Kafka中读取数据并写入文件
Kafka消费者 从Kafka中读取数据 最近有需求要从kafak上消费读取实时数据,并将数据中的key输出到文件中,用于发布端的原始点进行比对,以此来确定是否传输过程中有遗漏数据. 不废话,直接上代 ...
- Flink 使用(一)——从kafka中读取数据写入到HBASE中
1.前言 本文是在<如何计算实时热门商品>[1]一文上做的扩展,仅在功能上验证了利用Flink消费Kafka数据,把处理后的数据写入到HBase的流程,其具体性能未做调优.此外,文中并未就 ...
- flume从kafka中读取数据
a1.sources = r1 a1.sinks = k1 a1.channels = c1 #使用内置kafka source a1.sources.r1.type = org.apache.flu ...
- python读取数据文件:pandas包详解
本文转载自https://blog.csdn.net/brucewong0516/article/details/79092579 pandas包是一个高效的文件读取工具,适用于txt,excel,等 ...
- java加载外部文件数据到代码中:外部数据文件放到jar包中,调用方法getResourceAsStream
任务要将数据文件geo.txt加载进行.因为是别人写的总体项目,不能乱动位置.只能将geo.txt打包到jar中某目录.比如,放到.class文件下怎么加载:http://riddickbryant. ...
- Kafka集成SparkStreaming
Spark Streaming + Kafka集成指南 Kafka项目在版本0.8和0.10之间引入了一个新的消费者API,因此有两个独立的相应Spark Streaming包可用.请选择正确的包, ...
- 解析SparkStreaming和Kafka集成的两种方式
spark streaming是基于微批处理的流式计算引擎,通常是利用spark core或者spark core与spark sql一起来处理数据.在企业实时处理架构中,通常将spark strea ...
- Spark Streaming和Kafka整合保证数据零丢失
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制.为了体验这个关键的特性,你需要满足以下几个先决条件: 1.输入的数据来自可靠的数据源 ...
- Spark Streaming之四:Spark Streaming 与 Kafka 集成分析
前言 Spark Streaming 诞生于2013年,成为Spark平台上流式处理的解决方案,同时也给大家提供除Storm 以外的另一个选择.这篇内容主要介绍Spark Streaming 数据接收 ...
随机推荐
- Python3学习之路~8.1 socket概念及参数介绍
一 socket介绍 TCP/IP 基于TCP/IP协议栈的网络编程是最基本的网络编程方式,主要是使用各种编程语言,利用操作系统提供的套接字网络编程接口,直接开发各种网络应用程序. socket概念 ...
- 帝国cms判断某一字段是否为空
<?php if(empty($navinfor[buy])) { ?> <? } else { ?> <h2 class="buy">< ...
- tomcat调试之固定步骤自动化
前端开发,使用tomcat调试,大致需要进行如下几个步骤.其中,第一步,进入项目所在目录敲sbt命令来打包,第二步,拷贝lib文件夹,第四步重启tomcat,反反复复已经让我不胜其烦,那么做个简单的b ...
- sap 查看自己代码的结构
1:进入系统X3C:然后输入T-CODE bsp_wd_cmpwb
- 机器人meta标签和X-Robots-Tag HTTP标头规格
抽象 本文档详细介绍了页级索引设置如何让您控制Google如何通过搜索结果提供内容.您可以通过在(X)HTML页面或HTTP标头中包含元标记来指定这些标记. 笔记 请注意,只有当抓取工具被允许访问包含 ...
- python获取当前,昨天,明天时间
import datetime nowTime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')#现在 pastTimeMinutes = ...
- cocos2d-x JS 获取屏幕大小或中点
以一张背景图为例: var HelloWorldLayer = cc.Layer.extend({ ctor:function () { this._super(); var bg = new cc. ...
- redis_bj_01
windows下安装redis 下载地址https://github.com/dmajkic/redis/downloads.下载到的Redis支持32bit和64bit.根据自己实际情况选择,我选择 ...
- Unity shader学习之半兰伯特光照模型
半兰伯特光照模型,为Valve公司在开发游戏<半条命>时提出的一种技术,用于解决漫反射光无法到达区域无任凭明暗变化,丢失模型细节表现的问题. 其公式如下: Cdiffuse = Cligh ...
- Python 3 -- 数据结构(list, dict, set,tuple )
看了<Head First Python>后,觉得写的很不错,适合新手.此处为读书笔记,方便日后查看. Python 提供了4中数据结构:list,dict,set,tuple. 每种结构 ...