hadoop学习笔记之一步一步部署hadoop分布式集群
一、准备工作
- 同一个局域网中的三台linux虚拟机,我用的是redhat6.4,如果主机是windows操作系统,可以先安装vmware workstation, 然后在workstation中装上3台虚拟机,这样就形成了一个以物理机为DNS服务器的局域网,物理机和虚拟机都有一个局域网IP,互相之间可以通信。
- 因为hadoop是一个java开发者写的开源软件,所以你懂得,肯定用的是java语言编写的,所以要装jdk,当然还有一些perl语言写的东西,所以也要装perl,因为是个集群,所以互相之间要连接通信,需要安装ssh
- 如果用的是redhat,还需要关闭火墙,因为火墙会导致虚拟机之间无法连接,即关闭iptables,ip6tables,selinux,并设置开机不自启动
- 本次试验搭建的环境为:
node1:192.168.141.130 matser/namenode
node2:192.168.141.131 slave/datanode
node3:192.168.141.132 slave/datanode
二、配置hosts
首先在所有节点上(node1,node2,node3)上面编辑:vi /etc/hosts,添加如下内容:
192.168.141.130 node1
192.168.141.131 node2
192.168.141.132 node3
这样,在设置相应的IP时就可以用其解析名称代替,如需要写192.168.141.130:9000时,就可以直接写node1:9000,不仅书写方便,而且可以加快解析IP的速度,使集群运行更加流畅,但是不配置该项也不会影响集群正常工作。
三、jdk安装
- 去jdk官网http://www.oracle.com/technetwork/cn/java/javase/downloads/index-jsp-138363-zhs.html,根据自己操作系统32还是64位下载一个jdk,我下载的是jdk-8u11-linux-i586.gz
- 解压jdk-8u11-linux-i586.gz:
tar zxf jdk-8u11-linux-i586.gz
然后会看到出现了一个目录:jdk1.8.0_11
- 为了书写方便,去掉版本信息,并将之移动到/usr/local/目录下:
mv jdk1..0_11 jdk
mv jdk /usr/local/ 修改环境变量:vi /etc/profile,在文件末尾添加信息,然后退出保存:

- 执行source /etc/profile,使修改的文件生效
- 然后执行java -version,如果能显示如下版本信息,则安装成功:

注意:有可能执行该命令时会报错,那是因为在64位系统上运行了32位的jdk, 这时候只需执行安装命令:yum install glibc.i686 -y即可 glibc.i686是一个32位运行库。
每台虚拟机都要装!
四、ssh无密码连接
- 首先我们新添加一个用户专门用来管理运行hadoop,我新建了一个名为grid的用户,然后自己设定该用户密码

- su - grid切换到grid用户
- ssh-keygen生成公钥和私钥,一直回车默认就是了:

- 执行如下命令,可以看到生成的key,然后将公钥复制成authorized_keys:

- 然后在每一个节点上(虚拟机)执行上述所有步骤,这样就有了3个authorized_keys文件,我们把3个authorized_keys文件的内容复制到一起,形成一个authorized_keys,并用这个总的authorized_keys替换各个节点上原来的authorized_keys文件。
- 验证一下是否成,就是在任一节点上,用ssh连接其他任何节点,如果不出现提示让你输密码,而是直接连上,则表示成功。
五、hadoop安装
终于到正菜了,呼呼!
- 去hadoop.apache.org下载一个稳定的版本即可,这里以hadoop-1.2.1.tar.gz为例
- 解压,去掉名字中的版本信息,移至/usr/local(具体移至什么地方可以自随意,就是自己别忘了就好)
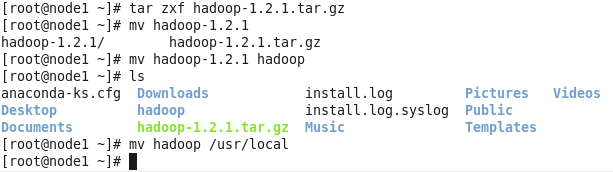
- cd /usr/local/hadoop/conf/ 转到hadoop配置目录下
- vi hadoop-env.sh,添加如下信息,告诉hadoop jdk的安装路径,然后保存退出:

- vi core-site.xml,写入如下信息,要注意,自己要在/home/grid/hadoop/ 目录下手动建立tmp目录,如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoop-dfs。而这个目录在每次重启后都会被删掉,必须重新执行format才行,否则会出错,hdfs后面的ip号就是名称节点的ip,即namenode的ip,端口号默认9000,不用改动。

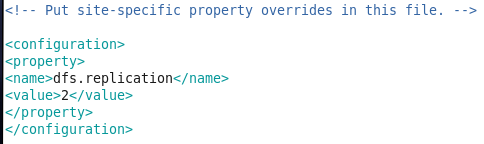
- vi hdfs-site.xml,设置数据备份数目,这里我们有有一个namenode,两个datanode,所以备份数目设置为2:
- vi mapreduce-site.xml,设置map-reduce的作业跟踪器(job tracker)所在节点,这里我们同样将其放置在node1(192.168.141.130)上,端口号9001:

- vi master,指定namenode所在节点,直接把节点名写进去:
node1
退出保存
注意,倘若没有像配置过/etc/hosts,这里就要直接写IP:192.168.141.130
- vi slave,指定datanode所在节点:
node2
node3
退出保存
同样注意,倘若没有像配置过/etc/hosts,这里就要直接写IP:
192.168.141.131
192.168.141.132
- 配置完毕,拷贝配置好的hadoop目录到指定位置(可以自定义,但是最好统一一个自己好记住的位置):

- 在node1上切换到grid, cd /home/grid/hadoop/,然后执行文件系统格式化:bin/hadoop namenode -format,如果没有任何warning,error,fatal等并且最后出现,format successfully字样,则格式化成。
- 启动hadoop:
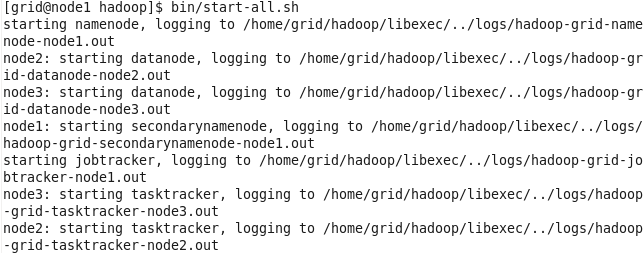
- 检查是否启动成功,如果名称节点namenode(node1)有如下所示:

并且数据节点(node2,node3)有如下所示:

 ,则启动成功!
,则启动成功!
六、集群测试
- 在node1上的,grid用户下,cd /home/grid/,建立一个目录mkdir input,然后进入目录input:cd input/,执行如下两条命令:
echo "hello world" > test1.txt
echo "hello hadoop" > test2.txt
- 将上述input目录下的文件上传到dfs文件系统,cd /home/grid/hadoop/,作如下操作:

- 查看是否上传成功:

上传成功,表示文件系统可以正常工作!
- 检查map-reduce功能是否正常,用hadoop包里面自带的单词统计jar包统计我们刚才上传的文件中不同单词的个数,看看是否正确:

- 执行完毕后查看结果:

可以看出统计单词数与我们上传的文件时一致的,说明map-reduce可以正常工作!
- 至此,我们可以自信我们的hadoop已经完全部署好了!
七、总结
对于第一次玩hadoop的读者来说,在安装的过程中,必定会出现,这样或者那样的问题,但是,我们要抱着一个解决问题的心,学习过程本就是在错误中成长,我自己在安装过程中也出现了不少问题,如datanode无法启动。或者那么namenode无法启动等等一系列问题,千万不要烦躁而放弃,自己慢慢在网上查资料还是可以解决的,最重要是细心,要学会根据系统的报错,检查配置文件是否写错,初学者都不怎么会看日志,但是要迈出这一步,硬着头皮看,当通过看日志解决了某个bug时,那种进步的愉悦感是很爽的,最后希望大家都犯点错,一次就配置成功不一定是好事,最后热烈欢迎大家给我留言,我们一起交流,学习!
2014-08-15
hadoop学习笔记之一步一步部署hadoop分布式集群的更多相关文章
- hadoop学习第二天-了解HDFS的基本概念&&分布式集群的搭建&&HDFS基本命令的使用
一.HDFS的相关基本概念 1.数据块 1.在HDFS中,文件诶切分成固定大小的数据块,默认大小为64MB(hadoop2.x以后是128M),也可以自己配置. 2.为何数据块如此大,因为数据传输时间 ...
- Hadoop学习笔记1 - 使用Java API访问远程hdfs集群
转载请标注原链接 http://www.cnblogs.com/xczyd/p/8570437.html 2018年3月从新司重新起航了.之前在某司过了的蛋疼三个月,也算给自己放了个小假了. 第一个小 ...
- RocketMQ学习笔记(4)----RocketMQ搭建双Master集群
前面已经学习了RockeMQ的四种集群方式,接下来就来搭建一个双Master(2m)的集群环境. 1. 双Master服务器环境 序号 ip 用户名 密码 角色 模式 (1) 47.105.145.1 ...
- 三、Linux部署MinIO分布式集群
MinIO的官方网站非常详细,以下只是本人学习过程的整理 一.MinIO的基本概念 二.Windows安装与简单使用MinIO 三.Linux部署MinIO分布式集群 四.C#简单操作MinIO 一. ...
- k8s学习笔记之二:使用kubeadm安装k8s集群
一.集群环境信息及安装前准备 部署前操作(集群内所有主机): .关闭防火墙,关闭selinux(生产环境按需关闭或打开) .同步服务器时间,选择公网ntpd服务器或者自建ntpd服务器 .关闭swap ...
- Linux Centos7 环境搭建Docker部署Zookeeper分布式集群服务实战
Zookeeper完全分布式集群服务 准备好3台服务器: [x]A-> centos-helios:192.168.19.1 [x]B-> centos-hestia:192.168.19 ...
- docker swarm快速部署redis分布式集群
环境准备 四台虚拟机 192.168.2.38(管理节点) 192.168.2.81(工作节点) 192.168.2.100(工作节点) 192.168.2.102(工作节点) 时间同步 每台机器都执 ...
- Hadoop入门学习笔记-第三天(Yarn高可用集群配置及计算案例)
什么是mapreduce 首先让我们来重温一下 hadoop 的四大组件:HDFS:分布式存储系统MapReduce:分布式计算系统YARN: hadoop 的资源调度系统Common: 以上三大组件 ...
- K8S学习笔记之二进制的方式创建一个Kubernetes集群
0x00 单节点搭建和简述 minikube Minikube是一个工具,可以在本地快速运行一个单点的Kubernetes,尝试Kubernetes或日常开发的用户使用.不能用于生产环境. 官方地址: ...
- 大数据学习笔记03-HDFS-HDFS组件介绍及Java访问HDFS集群
HDFS组件概述 NameNode 存储数据节点信息及元文件,即:分成了多少数据块,每一个数据块存储在哪一个DataNode中,每一个数据块备份到哪些DataNode中 这个集群有哪些DataNode ...
随机推荐
- day12 max min zip 用法
max min ,查看最大值,最小值 基础玩法 l = [1,2,3,4,5] print(max(l)) print(min(l)) 高端玩法 默认字典的取值是key的比较 age_dic={'al ...
- 有趣的electron(一)
跟我一起实现一个基于electron的hello-world吧- Come with me to implement an electron-based project hello-world. 先看 ...
- Windows7 64下搭建Caffe+python接口环境
参考链接: http://www.cnblogs.com/yixuan-xu/p/5858595.html http://www.cnblogs.com/zf-blog/p/6139044.html ...
- printf 中的 %.*s
printf("message arrived %.*s\n", length, str); .*代表length 当 str 长度大于等于 length,打印出 str 前 le ...
- maveb安装与配置(win10)
转载:https://www.cnblogs.com/eagle6688/p/7838224.html 看了几篇博客,感觉这篇博客写的含金量最高了,因为我电脑的系统是win10的,所以配置有细微的差别 ...
- selenium_采集药品数据2_采集所有表格
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- P2885 [USACO07NOV]电话线Telephone Wire
P2885 [USACO07NOV]电话线Telephone Wire 最近,Farmer John的奶牛们越来越不满于牛棚里一塌糊涂的电话服务于是,她们要求FJ把那些老旧的电话线换成性能更好的新电话 ...
- 20190311 Windows上ZooKeeper伪集群的实现
1. 复制并修改conf/zoo.cfg文件 以zoo1.cfg为例: dataDir=E:\\Develop\\zookeeper\\3.4.6\\zookeeper-3.4.6\\data1 da ...
- TCP和UDP基本原理
TCP和UDP基本原理 传输层的主要任务就是建立应用程序间的端到端连接,并且为数据传输提供可靠或不可靠的通信服务,TCP/IP协议族的传输层协议主要包括TCP和UDP ,TCP是面向连接的可靠的传输层 ...
- OS + CentOS 7 / centos 7 / VirtualBox /vegrant
s VirtualBox:解决VirtualBox安装时libSDL-1.2.so.0()错误的问题. http://www.sklinux.com/983 为Centos6.2安装VirtualBo ...