CBAM: 卷积块注意模块
CBAM: Convolutional Block Attention Module
论文地址:https://arxiv.org/abs/1807.06521
简介:我们提出了卷积块注意模块 (CBAM), 一个简单而有效的注意模块的前馈卷积神经网络。给出了一个中间特征映射, 我们的模块按照两个独立的维度、通道和空间顺序推断出注意力映射, 然后将注意力映射相乘为自适应特征细化的输入特征映射。因为 CBAM 是一个轻量级和通用的模块, 它可以无缝地集成到任何 CNN 架构只增加微不足道的间接开销, 可以集成到端到端的CNN里面去。通过对 ImageNet-1K、COCO、MS 检测和 VOC 2007 检测数据集的广泛实验, 我们验证了我们的 CBAM。我们的实验表明, 各种模型的分类和检测性能都有了一致的改进, 证明了 CBAM 的广泛适用性。这些代码和模型将公开提供。
2 相关工作
网络架构的构建,一直是计算机视觉中最重要的研究之一, 因为精心设计的网络确保了在各种应用中显著的性能提高。自成功实施大型 CNN以来, 已经提出了一系列广泛的体系结构。一种直观而简单的扩展方法是增加神经网络的深度如 VGG-NET、ResNet及其变体,如 WideResNet和 ResNeXt。GoogLeNet展现了增加网络的宽度对于结果的提升的帮助,典型的分类网络都在提升深度与宽度上下了很大功夫。
众所周知, 注意力在人的知觉中起着重要的作用。一个人并不是试图一次处理整个场景。相反, 人类注意部分场景, 并有选择地专注于突出部分, 以便更好地捕捉视觉结构。
最近, 有几次尝试加入注意处理, 以提高CNNs在大规模分类任务的性能。Residual attention network for image classification中使用 encoder-decoder 样式的注意模块的Residual attention network。通过细化特征映射,不仅网络性能良好, 而且对噪声输入也很健壮。我们不直接计算3d 的注意力映射, 而是分解了单独学习通道注意和空间注意的过程。对于3D 特征图, 单独的注意生成过程的计算和参数开销要小得多, 因此可以作为CNN的前置基础架构的模块使用。
Squeeze-and-excitation networks引入一个紧凑模块来利用通道间的关系。在他们的压缩和激励模块中, 他们使用全局平均池功能来计算通道的注意力。然而, 我们表明, 这些都是次优特征, 以推断良好的通道注意, 我们使用最大池化的特点。然而,他们也错过了空间注意力机制, 在决定 "Where"。在我们的 CBAM 中, 我们利用一个有效的体系结构来开发空间和通道的注意力, 并通过经验验证, 利用两者都优于仅使用通道的注意作为。此外, 我们的实验表明, 我们的模块在检测任务 (MS COCO和 VOC2017)上是有效的。特别是, 我们通过将我们的模块放在VOC2007 测试集中的现有的目标检测器结合实现了最先进的性能。
3 Convolutional Block Attention Module
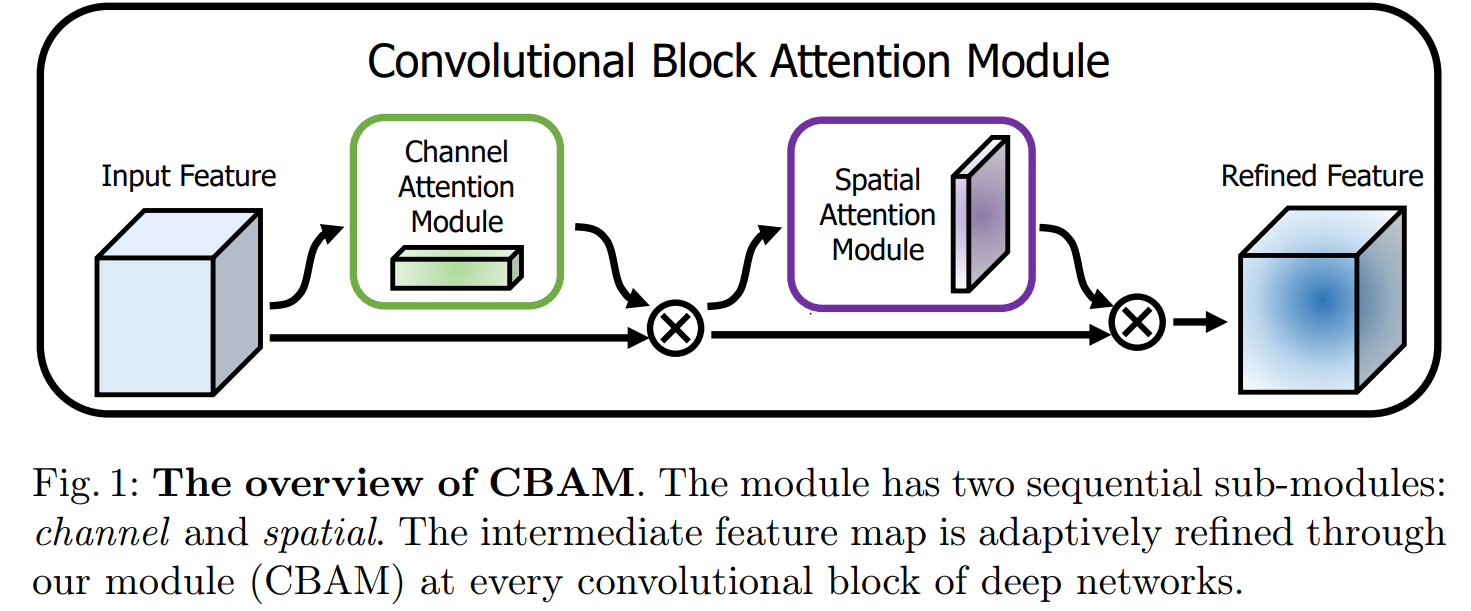
给定一个中间特征映射F∈RC xHxW作为输入, CBAM的1维通道注意图Mc ∈RC ×1×1 和2D 空间注意图Ms ∈R1×HxW 如图1所示。总的注意过程可以概括为:
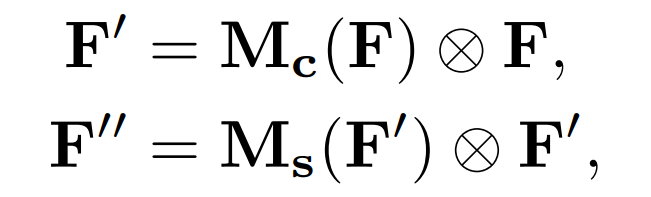
 表示逐元素相乘。在相乘过程中,注意值被广播。相应地,通道注意值被沿着空间维度广播,反之亦然。F’’是最终输出。
表示逐元素相乘。在相乘过程中,注意值被广播。相应地,通道注意值被沿着空间维度广播,反之亦然。F’’是最终输出。
3.1 Channel attention module
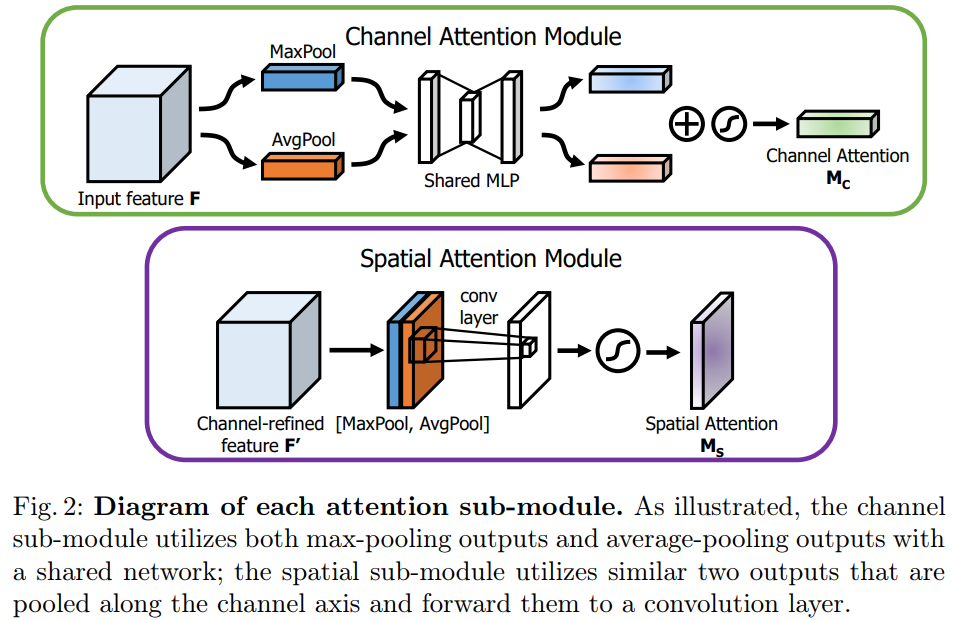
我们利用特征的通道间关系, 生成了通道注意图。当一个特征图的每个通道被考虑作为特征探测器, 通道注意聚焦于 ' what ' 是有意义的输入图像。为了有效地计算通道的注意力, 我们压缩了输入特征图的空间维数。为了聚焦空间信息,我们同时使用平均池化和最大池化。我们的实验证实, 同时使用这两种功能大大提高了网络的表示能力。下面将描述详细操作。
我们首先使用平均池化和最大池化操作来聚合特征映射的空间信息, 生成两个不同的空间上下文描述符:Fcavg 和Fcmax , 分别表示平均池化和最大池化。两个描述符然后送到一个共享网络, 以产生我们的通道注意力图 Mc ∈ Rc×1×1。共享网络由多层感知机(MLP) 和一个隐藏层组成。为了减少参数开销, 隐藏的激活大小被设置为 rc/c++×1×1, 其中 r 是压缩率。在将共享网络应用于每个描述符之后, 我们使用逐元素求和合并输出特征向量。简而言之, 频道的注意力被计算为:
Mc(f) = σ(MLP(AvgPool(f)) + MLP(MaxPool(f)))
= σ(W1(W0(Fcavg)) + W1(W0(Fcmax)))
σ是sigmoid function,W0 ∈ RC/r × C, W1 ∈ RC × C/r
W0 ,W1 是多层感知机的权重,共享输入和W0 的RELU激活函数。
3.2 Spatial attention module
我们利用特征间的空间关系, 生成空间注意图。与通道注意力不同的是, 空间注意力集中在 "where" 是一个信息的部分, 这是对通道注意力的补充。为了计算空间注意力, 我们首先在通道轴上应用平均池和最大池运算, 并将它们连接起来以生成一个有效的特征描述符。在串联特征描述符上, 我们应用7×7的卷积生成空间注意图的层Ms (F) ∈RH×W 。我们描述下面的详细操作.
我们使用两个池化操作来聚合功能映射的通道信息, 生成两个2维映射:Fsavg∈R1×HxW 和Fsmax∈R1×HxW 每个通道都表示平均池化和最大池化。然后通过一个标准的卷积层连接和卷积混合, 产生我们的2D 空间注意图。简而言之, 空间注意力被计算为:
Ms (f) = σ( f7×7( AvgPool(f) ; MaxPool(F)] )))
= σ(f7×7 (Fsavg; Fsmax])),
σ是sigmoid function, f7×7 是7×7的卷积。
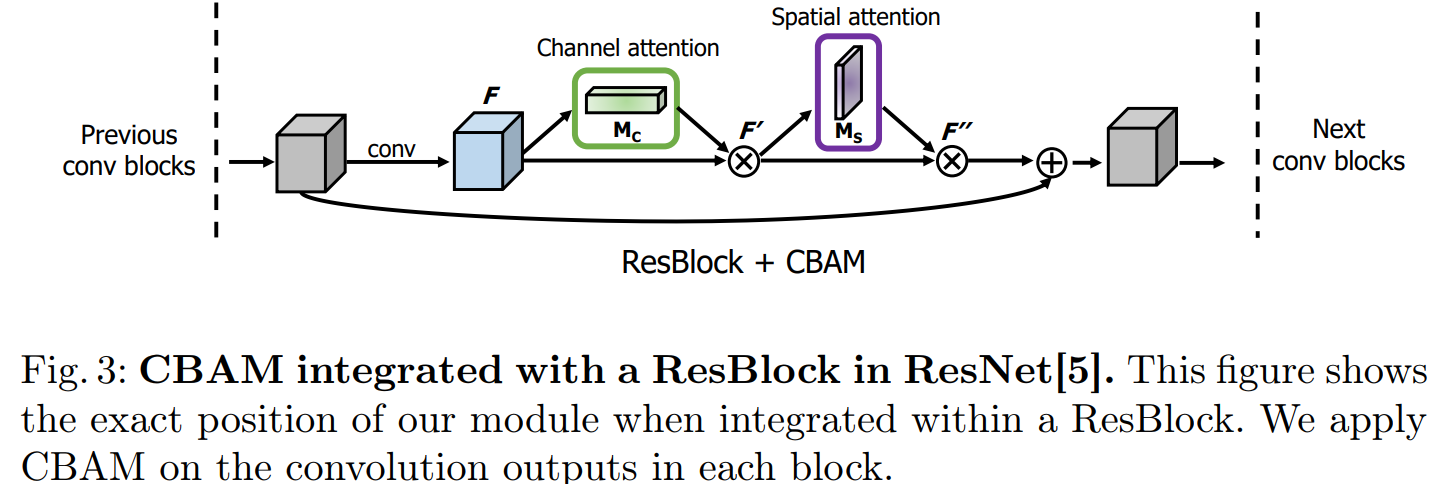
通过实验我们发现串联两个注意力模块的效果要优于并联。通道注意力放在前面要优于空间注意力模块放在前面。
4实验
在本小节中,我们凭实验证明了我们的设计选择的有效性。 在这次实验中,我们使用ImageNet-1K数据集并采用ResNet-50作为基础架构。 ImageNet-1K分类数据集[1]由1.2组成用于训练的百万个图像和用于1,000个对象类的验证的50,000个图像
我们采用相同的数据增强方案进行训练和测试时间进行单一作物评估,大小为224×224。 学习率从0.1开始,每30个时期下降一次。 我们训练网络90迭代。
4.1 通道注意力和空间注意力机制实验
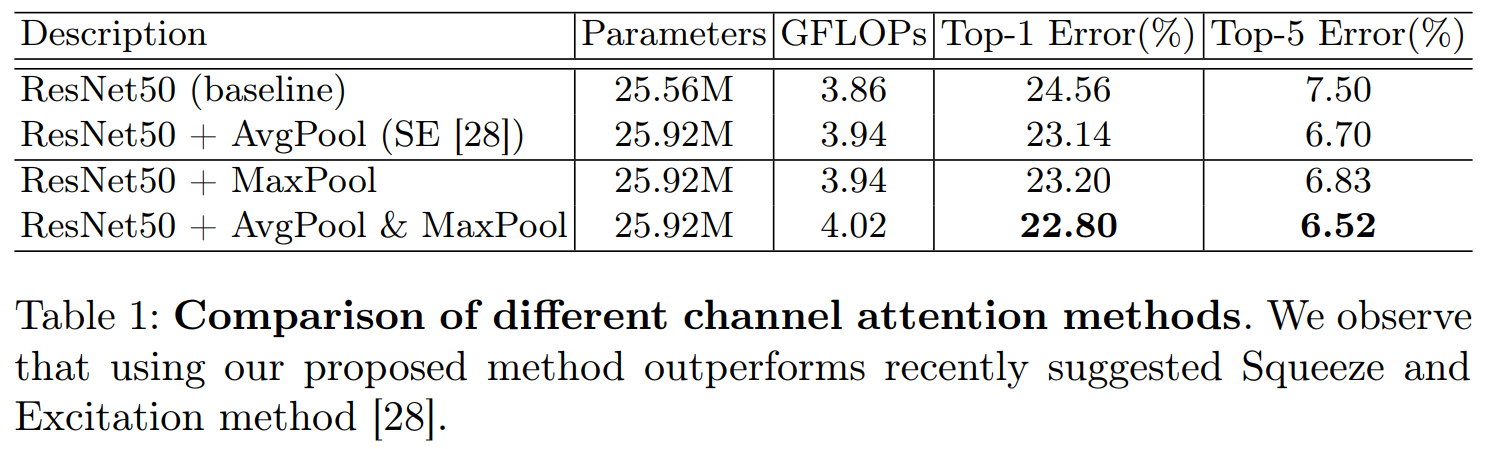
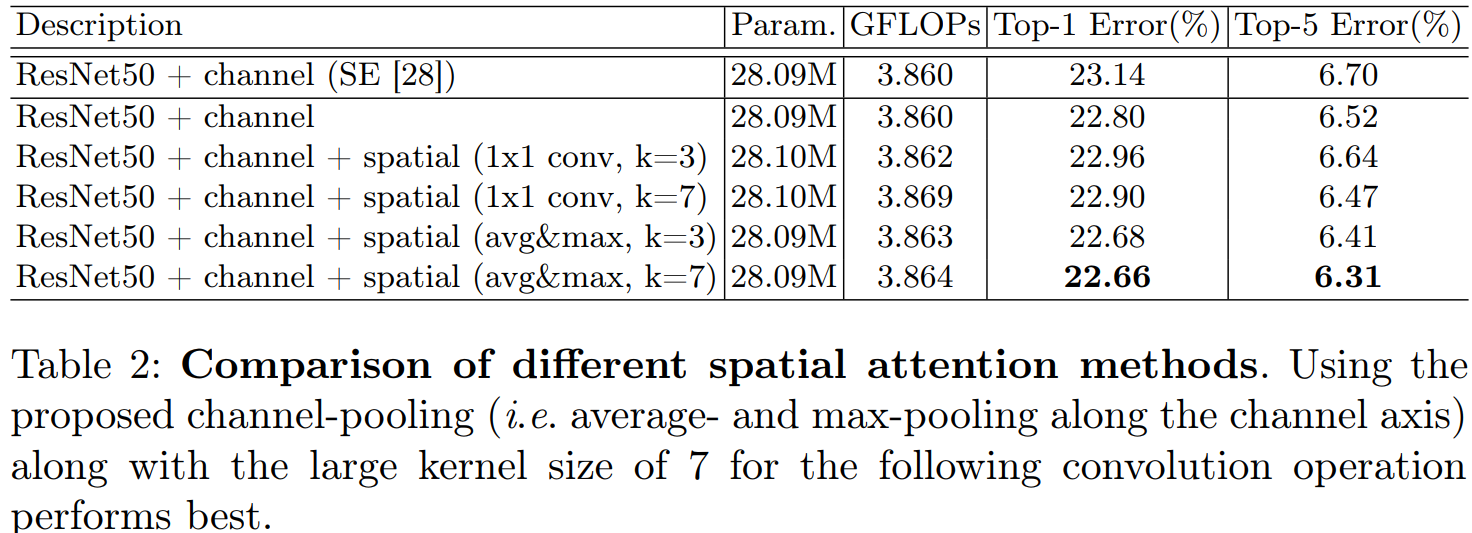
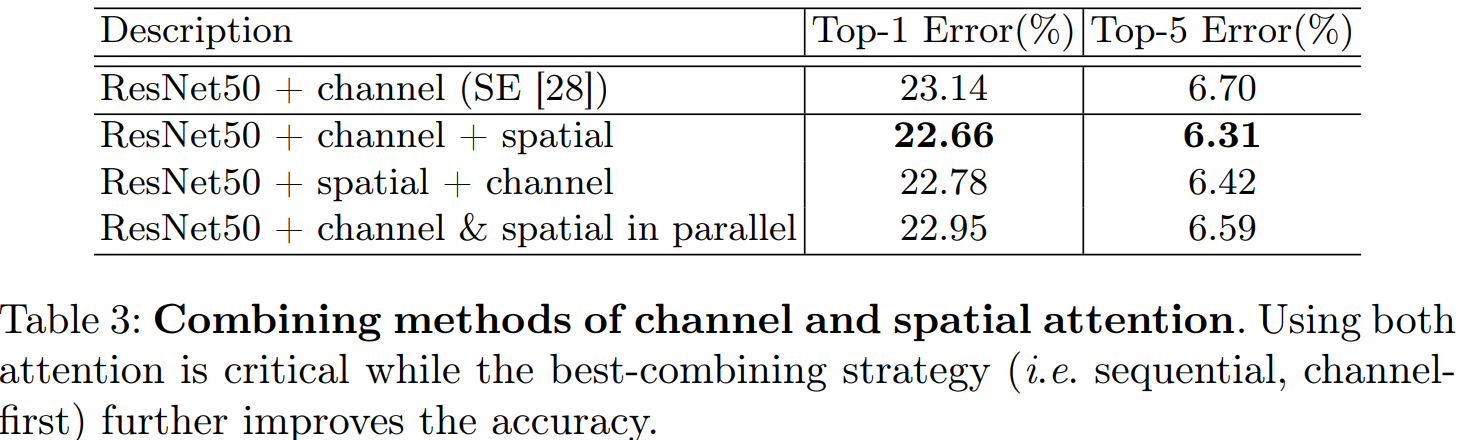
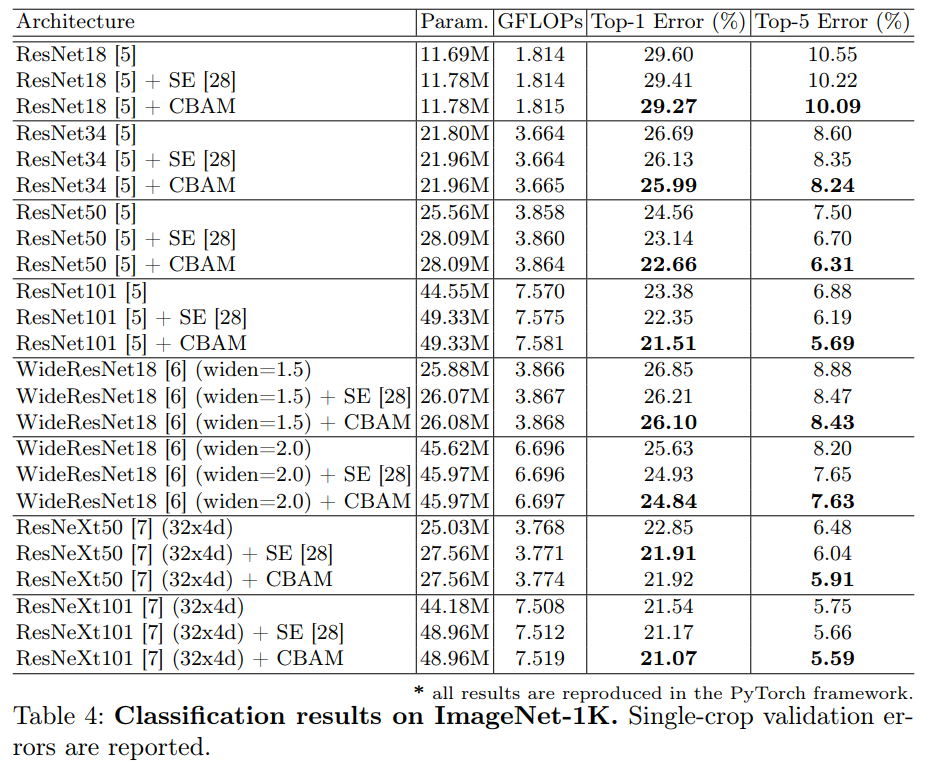
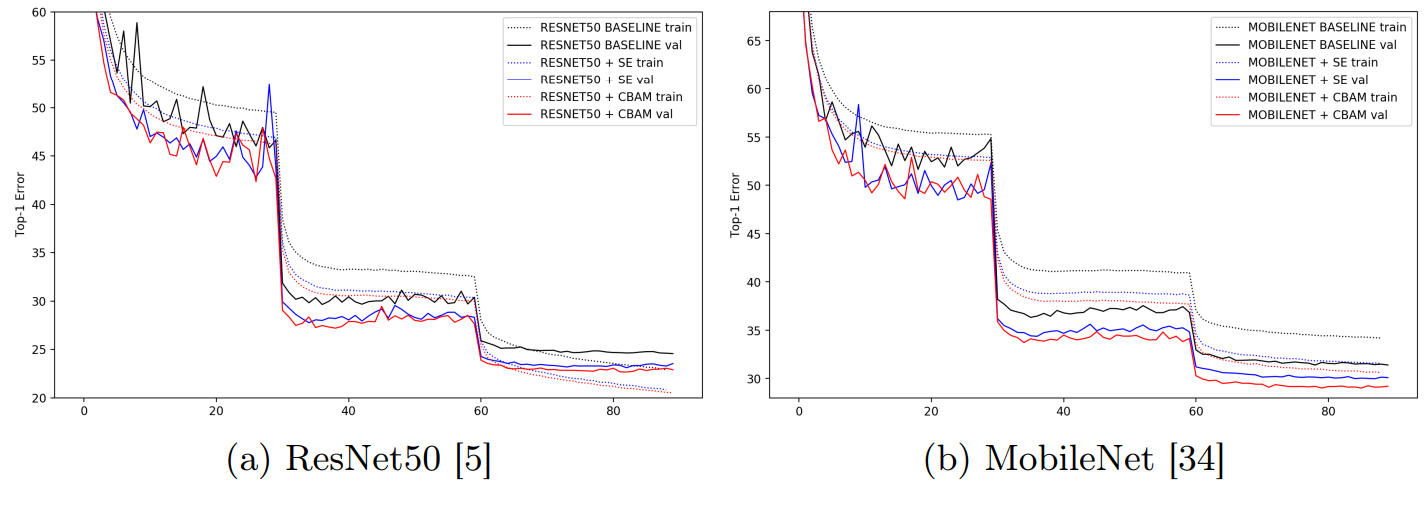
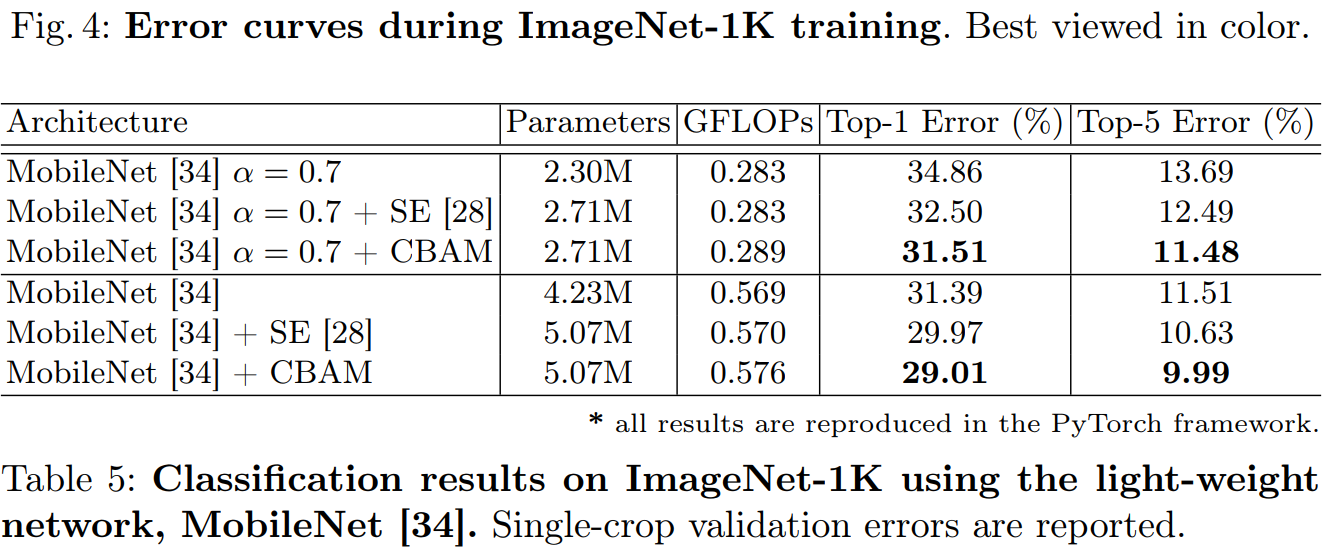
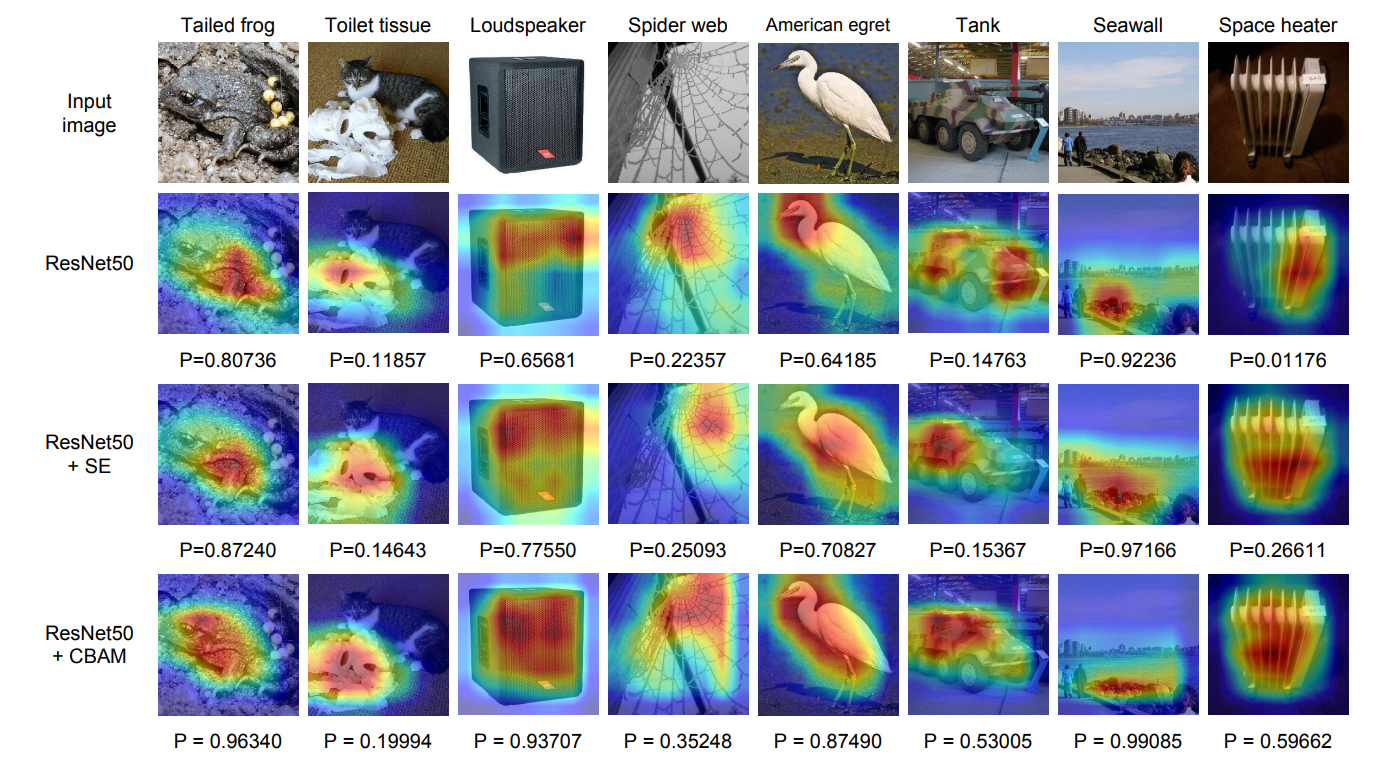
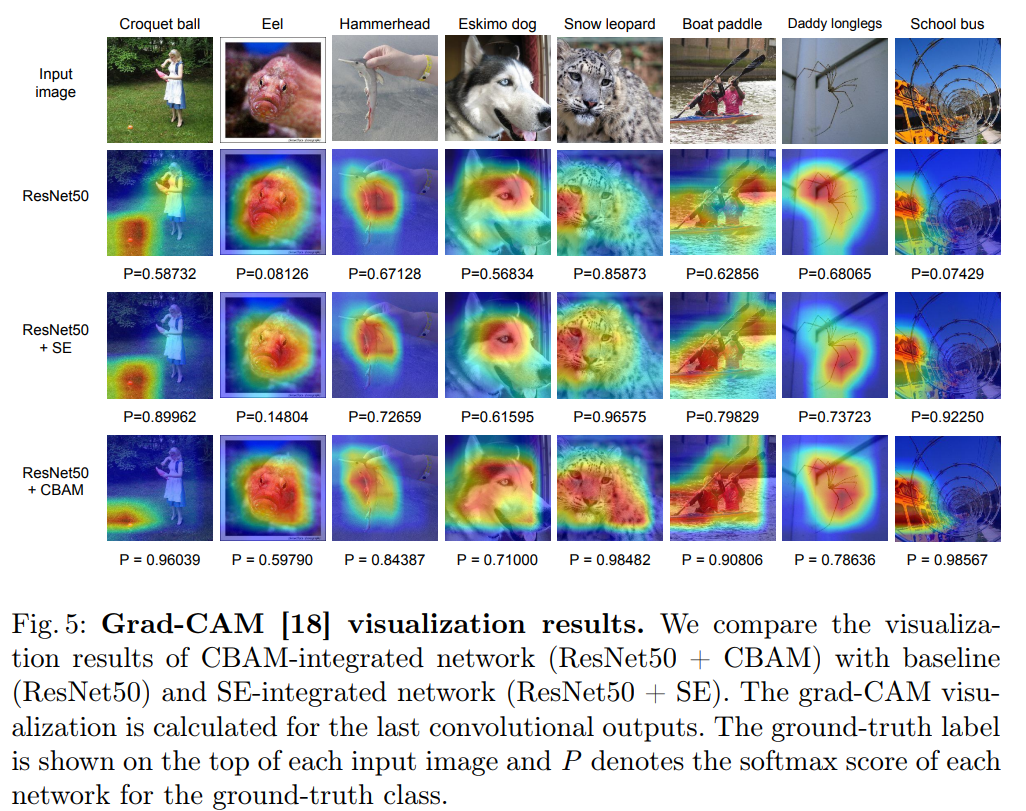
4.2我们使用Grad-CAM进行网络可视化
4.3 CBAM在目标检测的结果

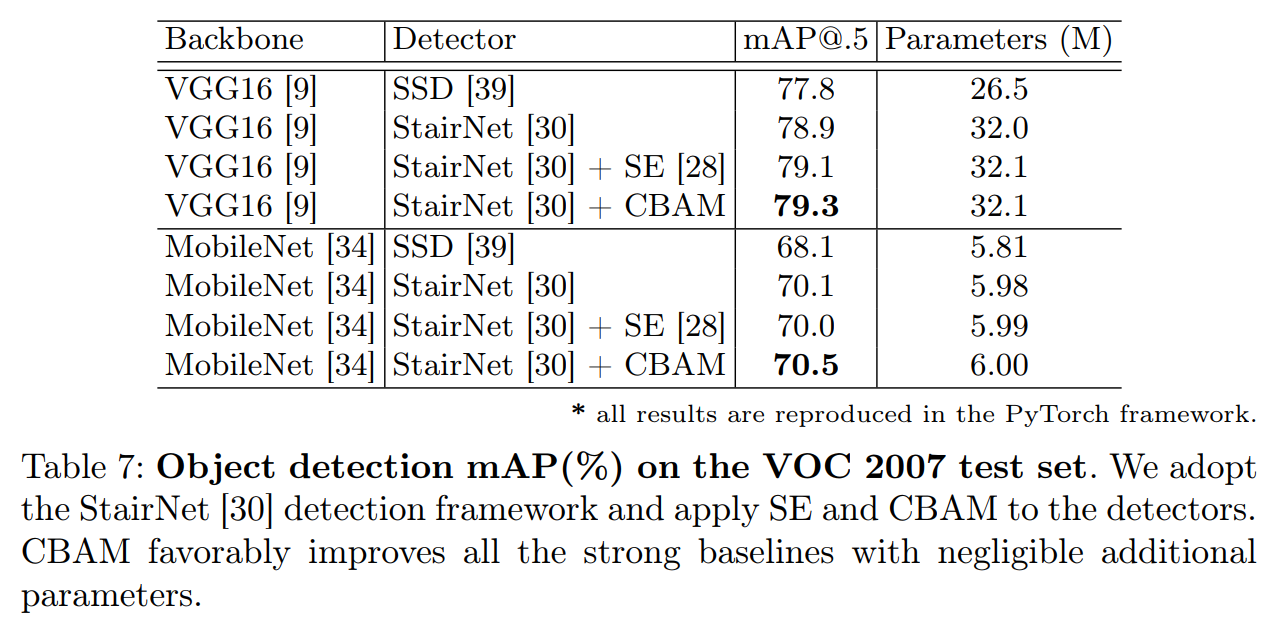
5总结
作者提出了一种提高 CNN 网络表示的新方法--卷积瓶颈注意模块 (CBAM)。作者将基于注意力的特征细化成两个不同的模块、通道和空间结合起来, 实现了显著的性能改进, 同时保持了小的开销。对于通道的关注,使用最大池化和平均池化,最终模块 (CBAM) 学习了如何有效地强调或压缩提取中间特征。为了验证它的有效性, 我们进行了广泛的实验与并证实, CBAM 优于所有基线上的三不同的基准数据集: ImageNet-1K, COCO, 和 VOC 2007。此外, 我们可视化模块如何准确推断给定的输入图像。CBAM 或许会成为各种网络体系结构的重要组成部分。
附上cbam的代码:
pytorch_resnet50
from collections import OrderedDict
import math
import torch
import torch.nn as nn
# import torchvision.models.resnet
class CBAM_Module(nn.Module): def __init__(self, channels, reduction):
super(CBAM_Module, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(channels, channels // reduction, kernel_size=1,
padding=0)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(channels // reduction, channels, kernel_size=1,
padding=0)
self.sigmoid_channel = nn.Sigmoid()
self.conv_after_concat = nn.Conv2d(2, 1, kernel_size = 3, stride=1, padding = 1)
self.sigmoid_spatial = nn.Sigmoid() def forward(self, x):
# Channel attention module:(Mc(f) = σ(MLP(AvgPool(f)) + MLP(MaxPool(f))))
module_input = x
avg = self.avg_pool(x)
mx = self.max_pool(x)
avg = self.fc1(avg)
mx = self.fc1(mx)
avg = self.relu(avg)
mx = self.relu(mx)
avg = self.fc2(avg)
mx = self.fc2(mx)
x = avg + mx
x = self.sigmoid_channel(x)
# Spatial attention module:Ms (f) = σ( f7×7( AvgPool(f) ; MaxPool(F)] )))
x = module_input * x
module_input = x
avg = torch.mean(x, 1, keepdim=True)
mx, _ = torch.max(x, 1, keepdim=True)
x = torch.cat((avg, mx), 1)
x = self.conv_after_concat(x)
x = self.sigmoid_spatial(x)
x = module_input * x
return x class Bottleneck(nn.Module):
"""
Base class for bottlenecks that implements `forward()` method.
"""
def forward(self, x):
residual = x out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out) out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out) out = self.conv3(out)
out = self.bn3(out) if self.downsample is not None:
residual = self.downsample(x) out = self.se_module(out) + residual
out = self.relu(out) return out class CBAMResNetBottleneck(Bottleneck):
"""
ResNet bottleneck with a CBAM_Module. It follows Caffe
implementation and uses `stride=stride` in `conv1` and not in `conv2`
(the latter is used in the torchvision implementation of ResNet).
"""
expansion = 4 def __init__(self, inplanes, planes, groups, reduction, stride=1,
downsample=None):
super(CBAMResNetBottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False,
stride=stride)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, padding=1,
groups=groups, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.se_module = CBAM_Module(planes * 4, reduction=reduction)
self.downsample = downsample
self.stride = stride class CABMNet(nn.Module): def __init__(self, block, layers, groups, reduction, dropout_p=0.2,
inplanes=128, input_3x3=True, downsample_kernel_size=3,
downsample_padding=1, num_classes=1000):
super(CABMNet, self).__init__()
self.inplanes = inplanes
if input_3x3:
layer0_modules = [
('conv1', nn.Conv2d(3, 64, 3, stride=2, padding=1,
bias=False)),
('bn1', nn.BatchNorm2d(64)),
('relu1', nn.ReLU(inplace=True)),
('conv2', nn.Conv2d(64, 64, 3, stride=1, padding=1,
bias=False)),
('bn2', nn.BatchNorm2d(64)),
('relu2', nn.ReLU(inplace=True)),
('conv3', nn.Conv2d(64, inplanes, 3, stride=1, padding=1,
bias=False)),
('bn3', nn.BatchNorm2d(inplanes)),
('relu3', nn.ReLU(inplace=True)),
]
else:
layer0_modules = [
('conv1', nn.Conv2d(3, inplanes, kernel_size=7, stride=2,
padding=3, bias=False)),
('bn1', nn.BatchNorm2d(inplanes)),
('relu1', nn.ReLU(inplace=True)),
]
# To preserve compatibility with Caffe weights `ceil_mode=True`
# is used instead of `padding=1`.
layer0_modules.append(('pool', nn.MaxPool2d(3, stride=2,
ceil_mode=True)))
self.layer0 = nn.Sequential(OrderedDict(layer0_modules))
self.layer1 = self._make_layer(
block,
planes=64,
blocks=layers[0],
groups=groups,
reduction=reduction,
downsample_kernel_size=1,
downsample_padding=0
)
self.layer2 = self._make_layer(
block,
planes=128,
blocks=layers[1],
stride=2,
groups=groups,
reduction=reduction,
downsample_kernel_size=downsample_kernel_size,
downsample_padding=downsample_padding
)
self.layer3 = self._make_layer(
block,
planes=256,
blocks=layers[2],
stride=2,
groups=groups,
reduction=reduction,
downsample_kernel_size=downsample_kernel_size,
downsample_padding=downsample_padding
)
self.layer4 = self._make_layer(
block,
planes=512,
blocks=layers[3],
stride=2,
groups=groups,
reduction=reduction,
downsample_kernel_size=downsample_kernel_size,
downsample_padding=downsample_padding
)
self.avg_pool = nn.AvgPool2d(7, stride=1)
self.dropout = nn.Dropout(dropout_p) if dropout_p is not None else None
self.last_linear = nn.Linear(512 * block.expansion, num_classes) for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_() # for m in self.modules():
# if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal(m.weight.data)
# elif isinstance(m, nn.BatchNorm2d):
# m.weight.data.fill_(1)
# m.bias.data.zero_() def _make_layer(self, block, planes, blocks, groups, reduction, stride=1,
downsample_kernel_size=1, downsample_padding=0):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=downsample_kernel_size, stride=stride,
padding=downsample_padding, bias=False),
nn.BatchNorm2d(planes * block.expansion),
) layers = []
layers.append(block(self.inplanes, planes, groups, reduction, stride,
downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, groups, reduction)) return nn.Sequential(*layers) def features(self, x):
x = self.layer0(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x def logits(self, x):
x = self.avg_pool(x)
if self.dropout is not None:
x = self.dropout(x)
x = x.view(x.size(0), -1)
x = self.last_linear(x)
return x def forward(self, x):
x = self.features(x)
x = self.logits(x)
return x def cbam_resnet50(num_classes=1000):
model = CABMNet(CBAMResNetBottleneck, [3, 4, 6, 3], groups=1, reduction=16,
dropout_p=None, inplanes=64, input_3x3=False,
downsample_kernel_size=1, downsample_padding=0,
num_classes=num_classes)
print(model)
return model
cbam_resnet50()
制作的PPT方便大家理解

CBAM: 卷积块注意模块的更多相关文章
- 论文翻译:2022_PACDNN: A phase-aware composite deep neural network for speech enhancement
论文地址:PACDNN:一种用于语音增强的相位感知复合深度神经网络 引用格式:Hasannezhad M,Yu H,Zhu W P,et al. PACDNN: A phase-aware compo ...
- 图像处理:卷积模块FPGA 硬件加速
本文记录了利用FPGA加速图像处理中的卷积计算的设计与实现.实现环境为Altera公司的Cyclone IV型芯片,NIOS II软核+FPGA架构. 由于这是第一次设计硬件加速模块,设计中的瑕疵以及 ...
- MXNET:卷积神经网络
介绍过去几年中数个在 ImageNet 竞赛(一个著名的计算机视觉竞赛)取得优异成绩的深度卷积神经网络. LeNet LeNet 证明了通过梯度下降训练卷积神经网络可以达到手写数字识别的最先进的结果. ...
- 深入学习卷积神经网络(CNN)的原理知识
网上关于卷积神经网络的相关知识以及数不胜数,所以本文在学习了前人的博客和知乎,在别人博客的基础上整理的知识点,便于自己理解,以后复习也可以常看看,但是如果侵犯到哪位大神的权利,请联系小编,谢谢.好了下 ...
- CNN中各类卷积总结:残差、shuffle、空洞卷积、变形卷积核、可分离卷积等
CNN从2012年的AlexNet发展至今,科学家们发明出各种各样的CNN模型,一个比一个深,一个比一个准确,一个比一个轻量.我下面会对近几年一些具有变革性的工作进行简单盘点,从这些充满革新性的工作中 ...
- CVPR2021|一个高效的金字塔切分注意力模块PSA
前言: 前面分享了一篇<继SE,CBAM后的一种新的注意力机制Coordinate Attention>,其出发点在于SE只引入了通道注意力,CBAM的空间注意力只考虑了局部区域的信息 ...
- CNN卷积神经网络详解
前言 在学计算机视觉的这段时间里整理了不少的笔记,想着就把这些笔记再重新整理出来,然后写成Blog和大家一起分享.目前的计划如下(以下网络全部使用Pytorch搭建): 专题一:计算机视觉基础 介 ...
- EdgeFormer: 向视觉 Transformer 学习,构建一个比 MobileViT 更好更快的卷积网络
前言 本文主要探究了轻量模型的设计.通过使用 Vision Transformer 的优势来改进卷积网络,从而获得更好的性能. 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结.最新技术跟 ...
- 斯坦福NLP课程 | 第11讲 - NLP中的卷积神经网络
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
随机推荐
- You are using safe update mode and you tried to update a table--mysql
SET SQL_SAFE_UPDATES = 0;delete from cms_article_data where id in(SELECT id FROM jeesite.cms_article ...
- JAVA实现SFTP实例
最近写的一个JAVA实现SFTP的实例: /* * Created on 2009-9-14 * Copyright 2009 by www.xfok.net. All Rights Reserved ...
- maven中修改可用的版本
一般情况下,我们都是建项目,写代码,然后再部署运行的.到最后因为版本问题无法部署的情况下怎么办?重新建项目,然后导代码,这太麻烦了. 一般的处理情况:在项目的硬盘目录中,找到.setting文件夹下的 ...
- python自动化运维之路~DAY7
python自动化运维之路~DAY7 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.客户端/服务器架构 C/S 架构是一种典型的两层架构,其全称是Client/Server,即 ...
- H5利用canvas实现海报功能
最近接到一个需求,微信中用户上传图片生成海报.这个需求比较常规,实现思路也比较简单,通过利用用户的input输入,对所上传的图片进行处理,最后通过第三方库html2canvas合成对应的图片即可.思路 ...
- CentOS6.x下源码安装MySQL5.5
1. 更新yum源:http://www.cnblogs.com/vurtne-lu/p/7405931.html 2. 卸载原有的mysql数据库 [root@zabbix ~]# yum -y r ...
- python学习笔记8-邮件模块
我们在开发程序的时候,有时候需要开发一些自动化的任务,执行完之后,将结果自动的发送一份邮件,python发送邮件使用smtplib模块,是一个标准包,直接import导入使用即可,代码如下: impo ...
- C# Winform继承窗体打开设计器白屏的一例解决方法
环境VS2017 15.5.4,Win10开发过程中,发现一些窗体打开设计器会卡死白屏,另外有一些不会,(两者运行时正常),最小化vs后甚至能把工具箱连带搞黑,严重影响开发效率,经过一天多的对比研究, ...
- EasyUI动态修改easyui-textbox验证信息
<tr> <td>编码:</td> <td><input type="text" id="code" na ...
- 第14月第23天 uitextfield文字下移
1. http://www.jianshu.com/p/641a0cbcabb0