proc-virtual-file-system
- 内核代码中分别找出一处 proc 和 seq_file 的完整使用过程,记录下来
- 在用户空间进行相应“读”、“写”
介绍
Proc 虚拟文件系统
操作 proc 文件:
- /proc 文件系统是一个虚拟文件系统(没有任何一部分与磁盘相关,只存在内存中,不占用外存空间),包含了一些目录和虚拟文件
- 通过它可以在 Linux 内核空间和用户空间之间进行通信:可以向用户呈现内核中的一些信息(用 cat、more 等命令查看 /proc 文件中的信息),也可以用作一种从用户空间向内核发送信息的手段
- LKM(Linux kernel module) 是用来展示 /proc 文件系统的一种简单方法,因为它可以动态地向 Linux 内核添加或删除代码
$ cd /proc
$ ls
蓝色部分是目录,其它是文件。
注:
/proc 文件系统可以用于获取运行中的进程的信息。在 /proc 中有一些编号的子目录。每一个编号的目录对应一个进程 id(PID)。这样,每个运行中的进程 /proc 中都有一个用它的 PID 命名的目录。这些子目录中包含可以提供有关进程的状态和环境的重要细节信息的文件,它们是读取进程信息的接口。
还有一些文件的含义,如:
apm # 高级电源管理信息 bus # 总线配置信息(USB的配置也记录在此) cmdline # 内核命令行 Cpuinfo # 关于Cpu信息 Devices # 可以用到的设备(块设备/字符设备) Dma # 使用的DMA通道 Filesystems # 支持的文件系统 Interrupts # 中断的使用 Ioports # I/O端口的使用 Kcore # 内核核心印象 Kmsg # 内核消息 Ksyms # 内核符号表 Loadavg # 负载均衡 Locks # 内核锁 Meminfo # 内存信息 Misc # 杂项 Modules # 加载模块列表(可以想成是驱动程序) Mounts # 加载的文件系统 Partitions # 系统识别的分区表 PCI # 在PCI总线上,每台设备的详细情况(可以使用lspci来查看) Rtc # 实时时钟 Slabinfo Slab # 池信息 stat # 全面统计状态表 Swaps # 对换空间的利用情况 Version # 内核版本 Uptime # 系统正常运行时间在 /proc 下还有三个很重要的目录:
net、scsi和sys。sys 目录是可写的,通过它可访问和修改内核参数,而 net 和 scsi 则依赖于内核配置。例如,如果系统不支持 scsi,则 scsi 目录不存在。
练习
- 内核代码中分别找出一处 proc 和 seq_file 的完整使用过程,记录下来
proc
从 proc_create 函数开始,剖析其中的实现
static inline struct proc_dir_entry *proc_create(const char *name, umode_t mode, struct proc_dir_entry *parent, const struct file_operations *proc_fops)
{
return proc_create_data(name, mode, parent, proc_fops, NULL);
}函数返回一个 proc_dir_entry 。可以看到 proc_create 中直接调用了 proc_create_data,而该函数主要完成 2 个功能:
- 调用 __proc_create 完成具体 proc_dir_entry 的创建。
- 调用 proc_redister 把 entry 注册进系统。
struct proc_dir_entry *proc_create_data(const char *name, umode_t mode, struct proc_dir_entry *parent, const struct file_operations *proc_fops, void *data)
{
struct proc_dir_entry *pde;
if ((mode & S_IFMT) == 0)
mode |= S_IFREG;
if (!S_ISEG(mode))
{
WARN_ON(1); // use proc_mkdir()
return NULL;
}
if ((mode & S_IALLUGO) == 0)
mode |= S_IRUGO;
pde = __proc_create(&parent, name, mode, 1);
if (!pde)
goto out;
pde->proc_fops = proc_fops;
pde->data = data;
if (proc_register(parent, pde) < 0)
goto out_free;
return pde;
out_free:
kfree(pde);
out:
return NULL;
}先看 proc_dir_entry 的创建,这里通过 __proc_create 函数,其实该函数内部很简单,就是为 entry 分配了空间,并对相关字段进行设置,主要包括 name、namelen、mod 和 nlink 等。创建好后,就设置操作函数 proc_fops 和 data 。然后就调用 proc_register 进行注册
static int proc_register(struct proc_dir_entry * dir, struct proc_dir_entry * dp)
{
struct proc_dir_entry *tmp;
int ret;
ret = proc_alloc_inum(&dp->low_ino);
if (ret)
return ret; // 如果是目录
if (S_ISDIR(dp->mode))
{ // 如果是链接
dp->proc_fops = &proc_dir_operations;
dp->proc_iops = &proc_dir_inode_operations;
dir->nlink++;
}
else if (S_ISLNK(dp->mode))
{
// 若是文件
dp->proc_iops = &proc_link_inode_operations;
}
else if (S_ISREG(dp->mode))
{
BUG_ON(dp->proc_fops == NULL);
dp->proc_iops = &proc_file_inode_operations;
}
else
{
WARN_ON(1);
return -EINVAL;
}
spin_lock(&proc_subdir_lock);
for (tmp = dir->subdir; tmp; tmp = -> next)
if (strcmp(tmp->name, dp->name) == 0)
{
WARN(1, "proc_dir_entry '%s/%s' already registered\n", dir->name, dp->name);
break;
}
// 子 dir 链接成链表,且子 dir 中含有父 dir 的指针
dp->next = dir->subdir;
dp->parent = dir;
dir->subdir = dp;
spin_unlock(&proc_subdir_lock);
return 0;
}函数首先分配一个inode number,然后根据entry的类型对其进行操作函数赋值,主要分为目录、链接、文件。这里我们只关注文件,文件的操作函数一般由用户自己定义,即上面我们设置的ops,这里仅仅是设置inode操作函数表,设置成了全局的proc_file_inode_operations,然后插入到父目录的子文件链表中,注意是头插法。基本结构如下,其中每个子节点都有指向父节点的指针。
seq_file
UNIX的世界里,文件是最普通的概念,所以用文件来作为内核和用户空间传递数据的接口也是再普通不过的事情,并且这样的接口对于shell也是相当友好的,方便管理员通过shell直接管理系统。由于伪文件系统proc文件系统在处理大数据结构(大于一页的数据)方面有比较大的局限性,使得在那种情况下进行编程特别别扭,很容易导致bug,所以序列文件接口被发明出来,它提供了更加友好的接口,以方便程序员。
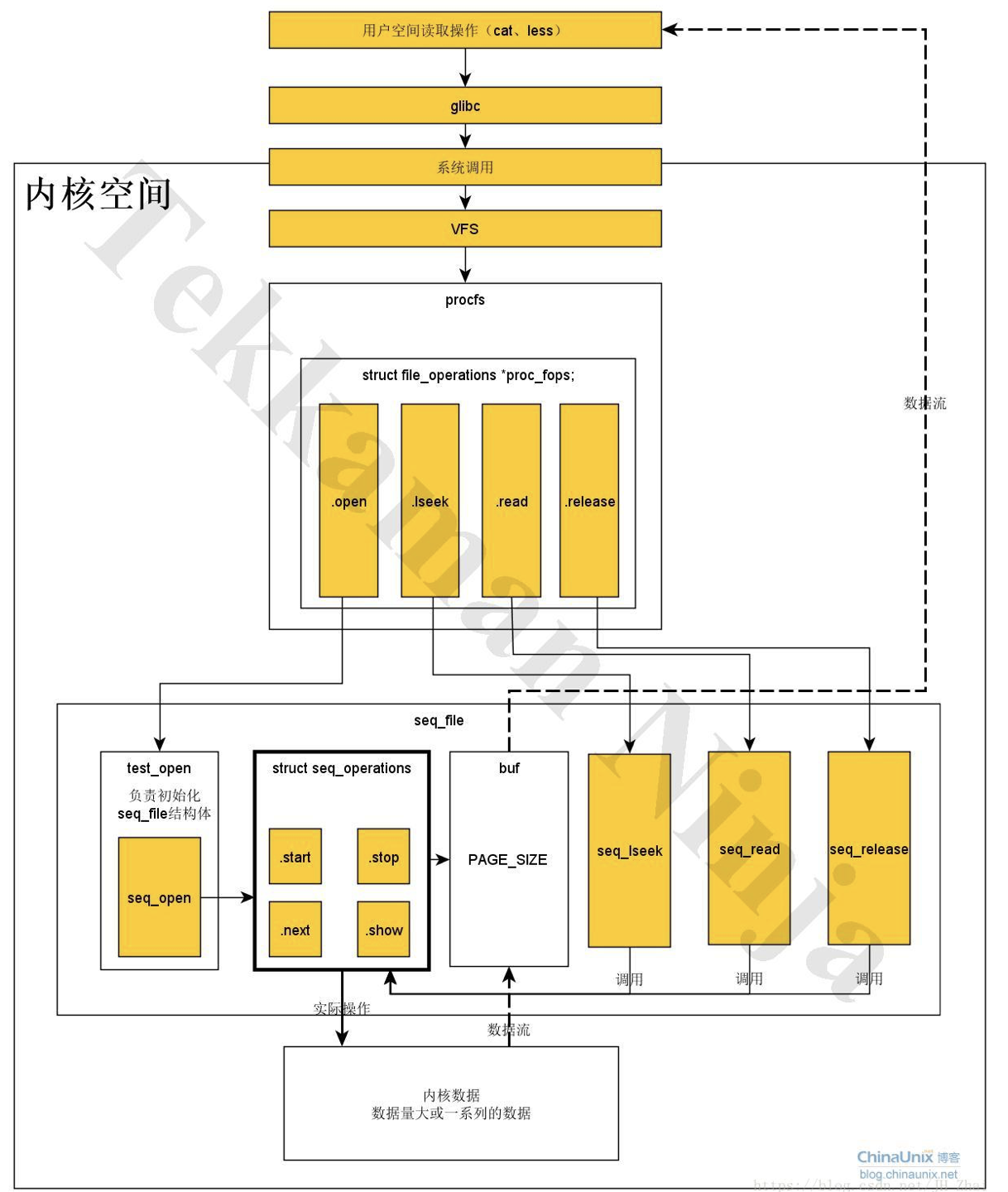
struct seq_file
{
char *buf; // seq_file 接口使用的缓存页指针
size_t size; // seq_file 接口使用的缓存页大小
size_t from; /* 从 seq_file 中向用户态缓冲区拷贝时相对于 buf 的偏移地址 */
size_t count; // buf 中可以拷贝到用户态的字符数目
loff_t index; // start、next 的处理的下标 pos 数值
loff_t read_pos; // 当前已拷贝到用户态的数据量大小
u64 version;
struct mutex lock; // 针对此 seq_file 操作的互斥锁,所有 seq_* 的访问都会上锁
const struct seq_operations *op; // 操作实际底层数据的函数
void *private;
};在这个结构体中,几乎所有的成员都是由seq_file内部实现来处理的,程序员不用去关心,除非你要去研究seq_file的内部原理。对于这个结构体,程序员唯一要做的就是实现其中的const struct seq_operations *op。为使用 seq_file接口对于不同数据结构体进行访问,你必须创建一组简单的对象迭代操作函数。
seq_file内部机制使用这些接口函数访问底层的实际数据结构体,并不断沿数据序列向前,同时逐个输出序列里的数据到seq_file自建的缓存(大小为一页)中。也就是说seq_file内部机制帮你实现了对序列数据的读取和放入缓存的机制,你只需要实现底层的迭代函数接口就好了,因为这些是和你要访问的底层数据相关的,而seq_file属于上层抽象。这可能看起来有点复杂,大家看了上面的图就好理解了:
struct seq_operations
{
void * (*start) (struct seq_file *m, loff_t *pos);
void (*stop) (struct seq_file *m, void *v);
void * (*next) (struct seq_file *m, void *v, loff_t *pos);
int (*show) (struct seq_file *m, void *v);
};void * (*start) (struct seq_file *m, loff_t *pos);start 方法会首先被调用,它的作用是在设置访问的起始点。
m:指向的是本seq_file的结构体,在正常情况下无需处理。
pos:是一个整型位置值,指示开始读取的位置。对于这个位置的意义完全取决于底层实现,不一定是字节为单位的位置,可能是一个元素的序列号。
返回值如果非NULL,则是一个指向迭代器实现的私有数据结构体指针。如果访问出错则返回NULL。
设置好了访问起始点,seq_file内部机制可能会使用show方法获取start返回值指向的结构体中的数据到内部缓存,并适时送往用户空间。
int (*show) (struct seq_file *m, void *v);所以show方法就是负责将v指向元素中的数据输出到seq_file的内部缓存,但是其中必须借助seq_file提供的一些类似printf的接口函数:
int seq_printf(struct seq_file *sfile, const char *fmt, ...);
//专为 seq_file 实现的类似 printf 的函数;用于将数据常用的格式串和附加值参数.
/*你必须将给 show 函数的 set_file 结构指针传递给它。如果seq_printf 返回-1,意味着缓存区已满,部分输出被丢弃。但是大部分时候都忽略了其返回值。*/
int seq_putc(struct seq_file *sfile, char c);
int seq_puts(struct seq_file *sfile, const char *s);
//类似 putc 和 puts 函数的功能,sfile参数和返回值与 seq_printf相同。
int seq_escape(struct seq_file *m, const char *s, const char *esc);
//这个函数类似 seq_puts ,但是它会将 s 中所有在 esc 中出现的字符以八进制格式输出到缓存。
//esc 的常用值是"\t\n\\", 它使内嵌的空格不会搞乱输出或迷惑 shell 脚本.
int seq_write(struct seq_file *seq, const void *data, size_t len)
//直接将data指向的数据写入seq_file缓存,数据长度为len。用于非字符串数据。
int seq_path(struct seq_file *sfile, struct vfsmount *m, struct dentry *dentry, char *esc);
//这个函数能够用来输出给定目录项关联的文件名,驱动极少使用。在show函数返回之后,seq_file机制可能需要移动到下一个数据元素,那就必须使用next方法
void * (*next) (struct seq_file *m, void *v, loff_t *pos);在next实现中应当递增pos指向的值,但是具体递增的数量和迭代器的实现有关,不一定是1。而next的返回值如果非NULL,则是下一个需要输出到缓存的元素指针,否则表明已经输出结束,将会调用stop方法做清理。
void (*stop) (struct seqa_file *m, void *v);在stop实现中,参数m指向本seq_file的结构体,在正常情况下无需处理。而v是指向上一个next或start返回的元素指针。在需要做退出处理的时候才需要实现具体的功能。但是许多情况下可以直接返回。
在next和start的实现中可能需要对一个序列的函数进行遍历,而在内核中,对于一个序列数据结构体的实现一般是使用双向链表或者哈希链表,所有seq_file同时提供了一些对于内核双向链表和哈希链表的封装接口函数,方便程序员实现对于通过链表链接的结构体序列的操作。这些函数名一般是seq_list_或者seq_hlist_,这些函数的实现都在fs/seq_file.c中,有兴趣的朋友可以看看。我在后面的实验中依然使用内核通用的双向链表API。
在用户空间进行“读”、“写”
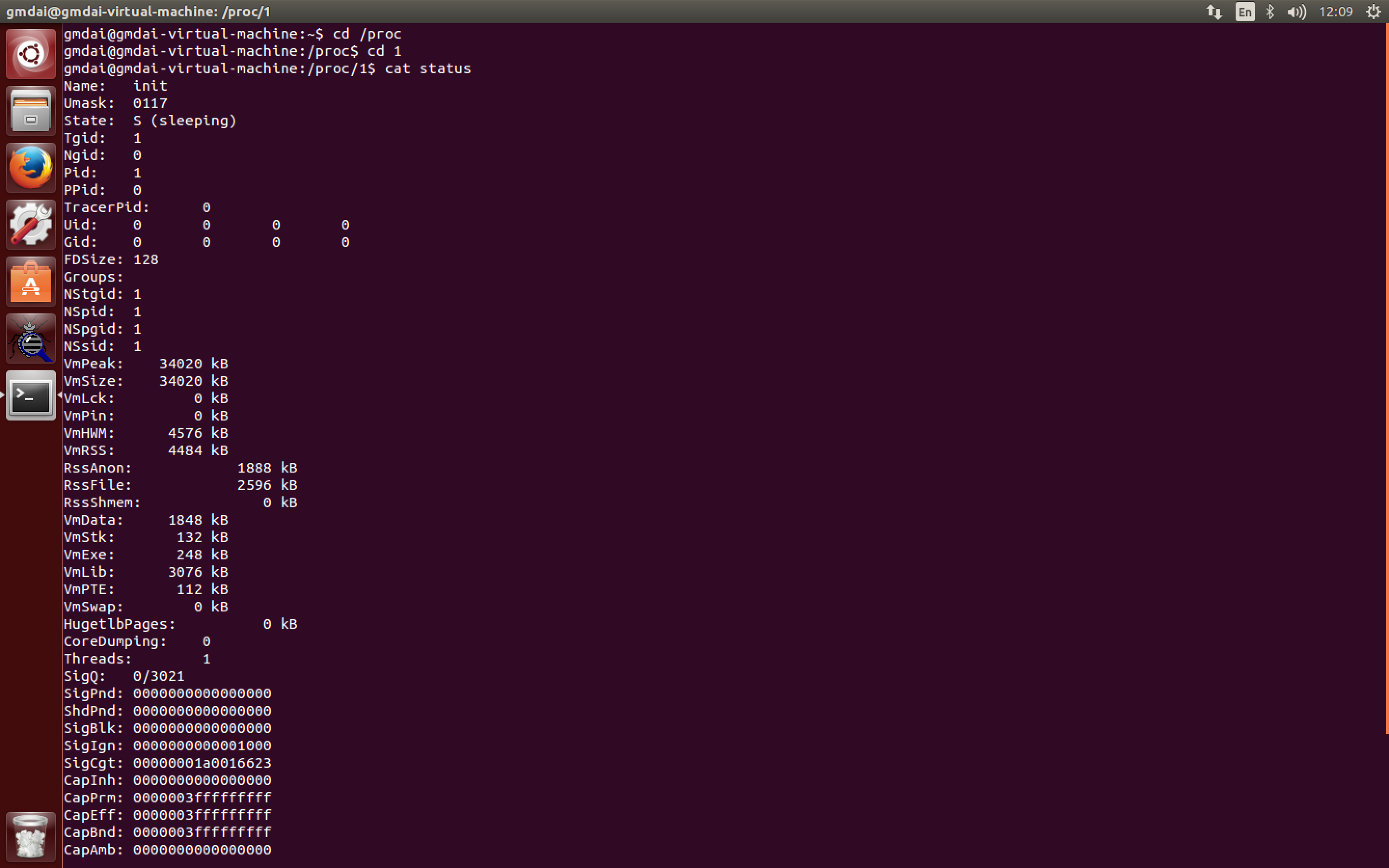
读
使用 cat 命令,读进程 1 的状态信息,比如 PID、PPID 和 status 等。
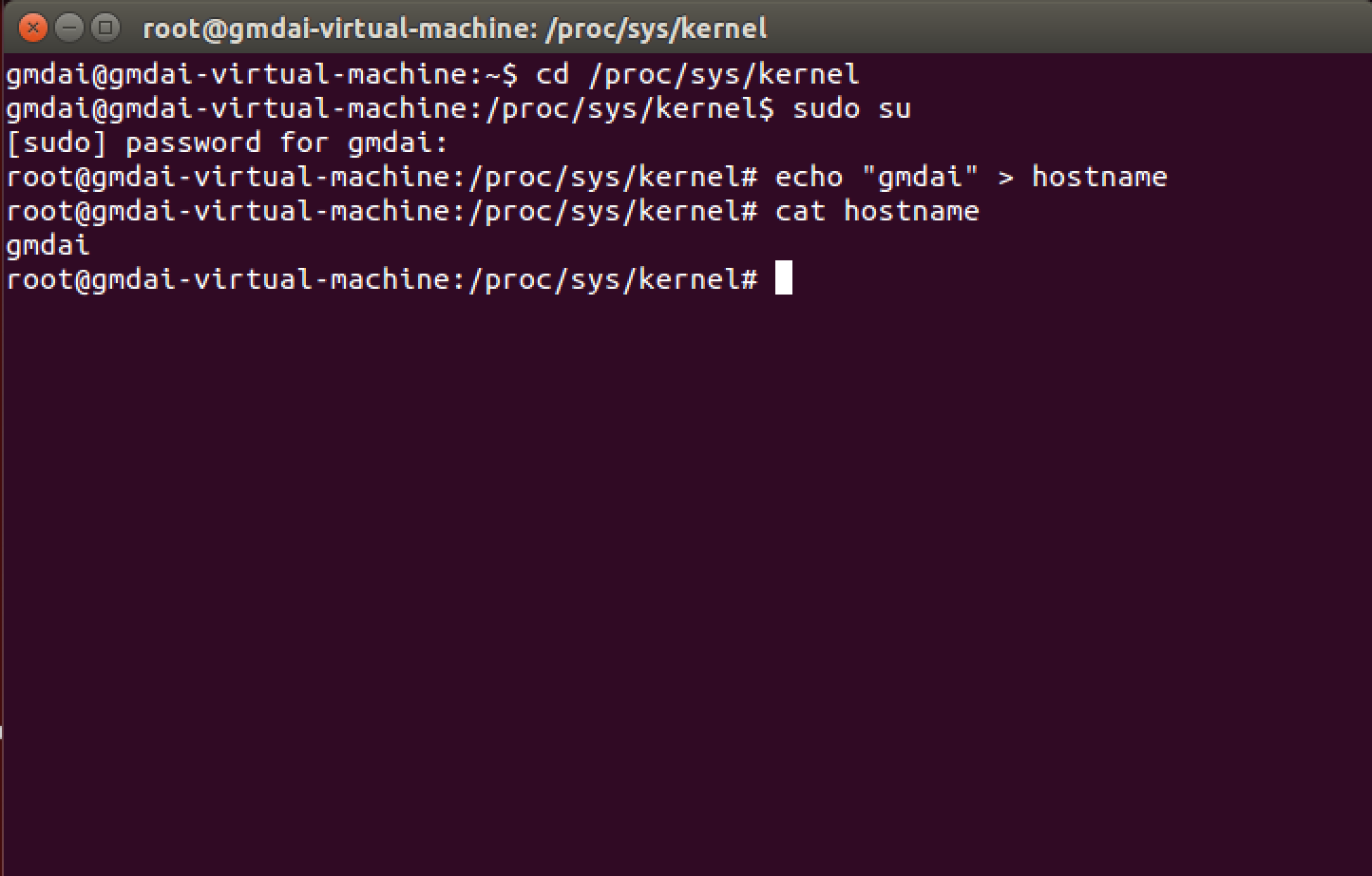
写
使用 echo ,修改 hostname。
参考帖子
proc-virtual-file-system的更多相关文章
- PatentTips – EMC Virtual File System
BACKGROUND OF THE INVENTION 1. Field of the Invention The present invention generally relates to net ...
- linux 虚拟文件系统----------Virtual File System VFSkky
在了解虚拟文件系统之前,必须先知道什么是 Kernal Space 与 User Space. Kernal Space 与User Space 的差别,在于内存使用上安全机制的差异. kerna ...
- VFS(Virtual File System)
一.VFS作为内核子系统,为用户空间程序提供了文件系统相关的接口.所有实际文件系统依赖VFS共存,依靠VFS系统工作. 1.VFS提供通用文件系统接口:用户空间程序可以利用标准的UNIX文件系统调用, ...
- virtual file system (VFS)
http://www.ibm.com/developerworks/library/l-virtual-filesystem-switch/ http://www.ibm.com/developerw ...
- Design and Implementation of the Sun Network File System
Introduction The network file system(NFS) is a client/service application that provides shared file ...
- File System Design Case Studies
SRC=http://www.cs.rutgers.edu/~pxk/416/notes/13-fs-studies.html Paul Krzyzanowski April 24, 2014 Int ...
- Samsung_tiny4412(驱动笔记06)----list_head,proc file system,GPIO,ioremap
/**************************************************************************** * * list_head,proc fil ...
- Linux File System
目录 . Linux文件系统简介 . 通用文件模型 . VFS相关数据结构 . 处理VFS对象 . 标准函数 1. Linux文件系统简介 Linux系统由数以万计的文件组成,其数据存储在硬盘或者其他 ...
- A MacFUSE-Based Process File System for Mac OS X
referer: http://osxbook.com/book/bonus/chapter11/procfs/ Processes as Files The process file system ...
- NFS(Network File System)服务配置和使用
Sun公司开发NFS (Network File System)之初就是为了在不同linux/Unix系统之间共享文件或者文件夹.可以在本地通过网络挂载远程主机的共享文件,和远程主机交互.NFS共享存 ...
随机推荐
- resure挽救笔记本系统和一些相关的操作记录
使用fedora23很久了, 但是感觉不是很流畅, 出现了一些不太稳定的体验, 所以想改到centos7. 因为centos7的很多东西 跟 fedora23 很相近了. 所以应该是无缝过渡 是选择3 ...
- SpringBoot 全局统一记录日志
1.记录日志 使用aop来记录controller中的请求返回日志 pom.xml引入: <dependency> <groupId>org.springframework.b ...
- A^B mod C (快速幂+快速乘+取模)题解
A^B mod C Given A,B,C, You should quickly calculate the result of A^B mod C. (1<=A,B,C<2^63). ...
- SpringBatch是什么?
https://segmentfault.com/a/1190000016278038 <dependency> <groupId>org.springframework.bo ...
- (转载)WinformGDI+入门级实例——扫雷游戏(附源码)
本文将作为一个入门级的.结合源码的文章,旨在为刚刚接触GDI+编程或对相关知识感兴趣的读者做一个入门讲解.游戏尚且未完善,但基本功能都有,完整源码在文章结尾的附件中. 整体思路: 扫雷的游戏界面让我从 ...
- A successful Git branching model——经典篇
A successful Git branching model In this post I present the development model that I’ve introduced f ...
- --HTML标签2
表单元素: <input>标签 搜集用户信息 属性:type=" " text 默认值 size 长度 value 规定值 readonly 规定值 placehold ...
- cmd中utf-8编码的问题
有时候我们需要使用cmd显示某个utf-8编码的文本,这时候就需要设置cmd的代码页为65100. 也就是 chcp 65001 这条命令.这样设置可以临时生效. 如何要永久生效,需要在注册表中修改. ...
- 基因组与Python --PyVCF 好用的vcf文件处理器
vcf文件的全称是variant call file,即突变识别文件,它是基因组工作流程中产生的一种文件,保存的是基因组上的突变信息.通过对vcf文件进行分析,可以得到个体的变异信息.嗯,总之,这是很 ...
- linux 校准时间方法
Debian.Ubuntu 系统安装NTP校时包: apt-get install ntpdate CentOS系统安装NTP校时包: yum install ntp 校时 ...