图->连通性->最小生成树(克鲁斯卡尔算法)
文字描述
上一篇博客介绍了最小生成树(普里姆算法),知道了普里姆算法求最小生成树的时间复杂度为n^2, 就是说复杂度与顶点数无关,而与弧的数量没有关系;
而用克鲁斯卡尔(Kruskal)算法求最小生成树则恰恰相反。它的时间复杂度为eloge (e为网中边的数目),因此它相对于普里姆算法而言,适合于求边稀疏的网的最小生成树。
克鲁斯卡尔算法求最小生成树的步骤为:假设连通网N={V,{E}}, 则令最小生成树的初始状态为只有n个顶点而无边的非连通图 T=(V, {}}, 图中每个顶点自成一个连通分量。在E中选择代价最小的边,若该边依附的顶点落在T中不同的连通分量中,则将此边加入到T中,否则舍去此边而选择下一条代价最小的边。依次类推,直至T中所有顶点都在同一连通分量上为止。
示意图:

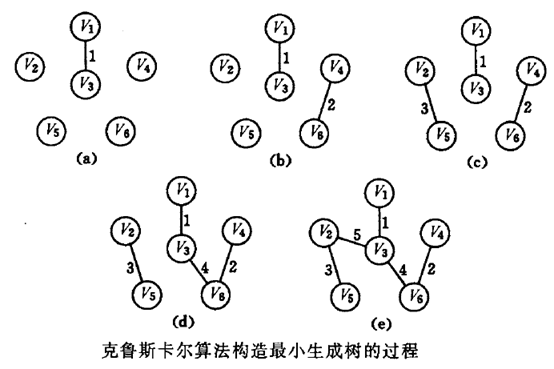
算法分析:
实现克鲁斯卡尔的话,可以借助于之前介绍的"堆"(堆排序)和树的等价划分的方法。用”堆”来存放网中的边,则每次选择最小代价的边仅需loge的时间(第一次需e)。又生成树T的每个连通分量可看成一个等价类,则构造T加入新的边的过程类似于求等价类的过程,由此可用MFSet类型来描述顶点,用堆Heap存放弧结点信息,使构造T的过程仅需eloge的时间,由此,克鲁斯
代码实现
//
// Created by lady on 18-12-15.
// #include <stdio.h>
#include <stdlib.h>
#include <string.h> #define MAX_NODE_NUM 20
#define MAX_ARCH_NUM 30 #define EQ(a, b) ((a)==(b))
#define LT(a, b) ((a) <(b))
#define LQ(a, b) ((a)<=(b)) typedef struct PTNode{
char data[];
int index;
int parent;
}PTNode; typedef struct{
PTNode node[MAX_NODE_NUM+];
int n;
}MFSet; typedef struct ArcBox{
int vex1, vex2;
int weight;
}ArcBox; typedef struct{
ArcBox r[MAX_ARCH_NUM+];
int len;
}HeapType; /* param1 S: S是已存在的集合
* param2 index: index是S中某个子集的成员的下标值
* result: 查找函数,确定S中位置为index所属子集Si,并返回其子集中的根结点的位置。
*/
static int findMFSet(MFSet *S, int index)
{
if(index < || index > S->n)
return -;
int j = ;
for(j=index; S->node[j].parent>; j=S->node[j].parent);
return j;
} /*
* 集合S中位置为index_i和index_j所在的子集互不相交。
* result: 将置为index_i和index_j所在的互不相交的子集合并为一个子集。
*/
static int mergeMFSet(MFSet *S, int index_i, int index_j)
{
int loc_i = -, loc_j = -;
if((loc_i=findMFSet(S, index_i)) < ){
return -;
}
if((loc_j=findMFSet(S, index_j)) < ){
return -;
}
if(loc_i == loc_j){
return -;
}
//结点数少的子集指向结点数大的子集
if(S->node[loc_i].parent > S->node[loc_j].parent){
S->node[loc_j].parent += S->node[loc_i].parent;
S->node[loc_i].parent = loc_j;
}else{
S->node[loc_i].parent += S->node[loc_j].parent;
S->node[loc_j].parent = loc_i;
}
return ;
} static int initialMFSet(MFSet *S, int n)
{
int i = ;
S->n = n;
for(i=; i<=S->n; i++)
{
printf("输入第%d个子集:", i);
scanf("%s", S->node[i].data);
S->node[i].parent = -;
S->node[i].index = i;
}
return ;
} /*
* 返回结点中数据等于data的下标值
*/
static int getLocaofVex(MFSet *S, char data[])
{
int i = ;
for(i=; i<=S->n; i++){
if(!strncasecmp(S->node[i].data, data, sizeof(S->node[].data))){
return S->node[i].index;
}
}
return -;
} static void printMFSet(MFSet *S)
{
printf("打印MFSet结构中的数据:\n");
int i = ;
for(i=; i<=S->n; i++){
printf("index %d:(data %s, parent %d)\n", S->node[i].index, S->node[i].data, S->node[i].parent);
}
printf("\n");
} ////////////////////////////////////////////// static int printHeap(HeapType *H)
{
printf("打印堆结构中的数据:\n");
int i = ;
for(i=; i<=H->len; i++){
printf("index %d: arch:(%d,%d),weight %d)\n", i, H->r[i].vex1, H->r[i].vex2, H->r[i].weight);
}
return ;
} static int initialHeap(HeapType *H, MFSet *S, int n)
{
H->len = n;
int i = ;
char s1[] = {};
char s2[] = {};
char s3[] = {};
int weight = ; char tmp[] = {};
for(i=; i<=H->len; i++)
{
printf("输入第%d条弧信息(顶点1 顶点2 权值):", i);
memset(tmp, , sizeof(tmp));
scanf("%s", tmp);
sscanf(tmp, "%[^','],%[^','],%s[^\\n]", s1, s2, s3);
H->r[i].vex1 = getLocaofVex(S, s1);
H->r[i].vex2 = getLocaofVex(S, s2);
H->r[i].weight = atoi(s3);
}
return ;
} /*
*已知H->r[s,...,m]中记录的关键字除H->r[s].key之外均满足的定义
*本函数调整H-r[s]的关键字,使H->r[s,...,m]成为一个小顶堆(对其中
*记录的弧的权值而言)
*/
void HeapAdjust(HeapType *H, int s, int m)
{
ArcBox rc = H->r[s];
int j = ;
//沿weight较小的孩子结点向下筛选
for(j=*s; j<=m; j*=){
//j为weight较小的孩子结点下标
if(j<m && (!LQ(H->r[j].weight, H->r[j+].weight)))
j+=;
if(LQ(rc.weight, H->r[j].weight))
break;
H->r[s] = H->r[j];
s=j;
}
H->r[s] = rc;
} void HeapSort(HeapType *H, MFSet *S)
{
int i = ;
printf("1)建立一个小顶堆!\n");
//把H->r[1,...,H->length]建成小顶堆
for(i=H->len/; i>=; i--){
HeapAdjust(H, i, H->len);
}
printHeap(H);
printf("2)依次输出堆顶元素并重新调整成小顶堆!\n");
ArcBox tmp;
for(i=H->len; i>; i--){
tmp = H->r[];
H->r[] = H->r[i];
H->r[i] = tmp;
HeapAdjust(H, , i-);
printf("新堆顶的弧信息: (%d,%d) %d", tmp.vex1, tmp.vex2, tmp.weight);
if(mergeMFSet(S, tmp.vex1, tmp.vex2) > -){
printf("\t是最小生成树的弧!\n");
}else{
printf("\n");
}
}
} int main(int argc, char *argv[])
{
int nodes=;
int archs=;
printf("输入顶点数和弧数:");
scanf("%d,%d", &nodes, &archs); printf("\n以MFSet结构存放顶点信息:\n");
MFSet S;
initialMFSet(&S, nodes);
printMFSet(&S); printf("以堆结构存放弧信息:\n");
HeapType H;
initialHeap(&H, &S, archs);
printHeap(&H); printf("对存放了弧信息的堆进行排序,在排序过程中输入最小生成树的边\n");
HeapSort(&H, &S);
return ;
}
最小生成树(克鲁斯卡尔算法)
代码运行
/home/lady/CLionProjects/untitled/cmake-build-debug/untitled
输入顶点数和弧数:6,10 以MFSet结构存放顶点信息:
输入第1个子集:V1
输入第2个子集:V2
输入第3个子集:V3
输入第4个子集:V4
输入第5个子集:V5
输入第6个子集:V6
打印MFSet结构中的数据:
index 1:(data V1, parent -1)
index 2:(data V2, parent -1)
index 3:(data V3, parent -1)
index 4:(data V4, parent -1)
index 5:(data V5, parent -1)
index 6:(data V6, parent -1) 以堆结构存放弧信息:
输入第1条弧信息(顶点1 顶点2 权值):V3,V1,1
输入第2条弧信息(顶点1 顶点2 权值):V3,V2,5
输入第3条弧信息(顶点1 顶点2 权值):V3,V5,6
输入第4条弧信息(顶点1 顶点2 权值):V3,V6,4
输入第5条弧信息(顶点1 顶点2 权值):V3,V4,5
输入第6条弧信息(顶点1 顶点2 权值):V1,V2,6
输入第7条弧信息(顶点1 顶点2 权值):V2,V5,3
输入第8条弧信息(顶点1 顶点2 权值):V5,V6,6
输入第9条弧信息(顶点1 顶点2 权值):V6,V4,2
输入第10条弧信息(顶点1 顶点2 权值):V4,V1,5
打印堆结构中的数据:
index 1: arch:(3,1),weight 1)
index 2: arch:(3,2),weight 5)
index 3: arch:(3,5),weight 6)
index 4: arch:(3,6),weight 4)
index 5: arch:(3,4),weight 5)
index 6: arch:(1,2),weight 6)
index 7: arch:(2,5),weight 3)
index 8: arch:(5,6),weight 6)
index 9: arch:(6,4),weight 2)
index 10: arch:(4,1),weight 5)
对存放了弧信息的堆进行排序,在排序过程中输入最小生成树的边
1)建立一个小顶堆!
打印堆结构中的数据:
index 1: arch:(3,1),weight 1)
index 2: arch:(6,4),weight 2)
index 3: arch:(2,5),weight 3)
index 4: arch:(3,6),weight 4)
index 5: arch:(3,4),weight 5)
index 6: arch:(1,2),weight 6)
index 7: arch:(3,5),weight 6)
index 8: arch:(5,6),weight 6)
index 9: arch:(3,2),weight 5)
index 10: arch:(4,1),weight 5)
2)依次输出堆顶元素并重新调整成小顶堆!
新堆顶的弧信息: (3,1) 1 是最小生成树的弧!
新堆顶的弧信息: (6,4) 2 是最小生成树的弧!
新堆顶的弧信息: (2,5) 3 是最小生成树的弧!
新堆顶的弧信息: (3,6) 4 是最小生成树的弧!
新堆顶的弧信息: (4,1) 5
新堆顶的弧信息: (3,4) 5
新堆顶的弧信息: (3,2) 5 是最小生成树的弧!
新堆顶的弧信息: (5,6) 6
新堆顶的弧信息: (3,5) 6 Process finished with exit code 0
图->连通性->最小生成树(克鲁斯卡尔算法)的更多相关文章
- 贪心算法(Greedy Algorithm)之最小生成树 克鲁斯卡尔算法(Kruskal's algorithm)
克鲁斯卡尔算法(Kruskal's algorithm)是两个经典的最小生成树算法的较为简单理解的一个.这里面充分体现了贪心算法的精髓.大致的流程能够用一个图来表示.这里的图的选择借用了Wikiped ...
- 贪心算法(Greedy Algorithm)最小生成树 克鲁斯卡尔算法(Kruskal's algorithm)
克鲁斯卡尔算法(Kruskal's algorithm)它既是古典最低的一个简单的了解生成树算法. 这充分反映了这一点贪心算法的精髓.该方法可以通常的图被表示.图选择这里借用Wikipedia在.非常 ...
- 最小生成树--克鲁斯卡尔算法(Kruskal)
按照惯例,接下来是本篇目录: $1 什么是最小生成树? $2 什么是克鲁斯卡尔算法? $3 克鲁斯卡尔算法的例题 摘要:本片讲的是最小生成树中的玄学算法--克鲁斯卡尔算法,然后就没有然后了. $1 什 ...
- 最小生成树-克鲁斯卡尔算法(kruskal's algorithm)实现
算法描述 克鲁斯卡尔算法是一种贪心算法,因为它每一步都挑选当前最轻的边而并不知道全局路径的情况. 算法最关键的一个步骤是要判断要加入mst的顶点是否会形成回路,我们可以利用并查集的技术来做. 并查集的 ...
- 最小生成树之Kruskal(克鲁斯卡尔)算法
学习最小生成树算法之前我们先来了解下下面这些概念: 树(Tree):如果一个无向连通图中不存在回路,则这种图称为树. 生成树 (Spanning Tree):无向连通图G的一个子图如果是一颗包含G的所 ...
- prim算法,克鲁斯卡尔算法---最小生成树
最小生成树的一个作用,就是求最小花费.要在n个城市之间铺设光缆,主要目标是要使这 n 个城市的任意两个之间都可以通信,但铺设光缆的费用很高,且各个城市之间铺设光缆的费用不同,因此另一个目标是要使铺设光 ...
- 图解最小生成树 - 克鲁斯卡尔(Kruskal)算法
我们在前面讲过的<克里姆算法>是以某个顶点为起点,逐步找各顶点上最小权值的边来构建最小生成树的.同样的思路,我们也可以直接就以边为目标去构建,因为权值为边上,直接找最小权值的边来构建生成树 ...
- 最小生成树——Kruscal(克鲁斯卡尔算法)
一.核心思想 将输入的数据由小到大进行排序,再使用并查集算法(传送门)将每个点连接起来,同时求和. 个人认为这个算法比较偏向暴力,有些题可能会超时. 二.例题 洛谷-P3366 题目地址:ht ...
- 洛谷P3366【模板】最小生成树-克鲁斯卡尔Kruskal算法详解附赠习题
链接 题目描述 如题,给出一个无向图,求出最小生成树,如果该图不连通,则输出orz 输入输出格式 输入格式: 第一行包含两个整数N.M,表示该图共有N个结点和M条无向边.(N<=5000,M&l ...
随机推荐
- 树莓派2上手 —— Raspbian的一些基本配置问题
先说点废话: 原来的笔记本因为上次被儿子拿着充电器玩的时候漏电烧了主板,修了之后还是时不时就突然宕机,Windows也完全起不来.后面这个问题倒是不大,真要用Windows的时候拿老婆的用一下就是了, ...
- Java多线程系列——线程池原理之 ThreadPoolExecutor
ThreadPoolExecutor 简介 ThreadPoolExecutor 是线程池类. 通俗的讲,它是一个存放一定数量线程的线程集合.线程池允许多个线程同时运行,同时运行的线程数量就是这个线程 ...
- BigDecimal提供了8种舍入方式
BigDecimal提供了8种舍入方式 1.ROUND_UP:舍入远离零的舍入模式.在丢弃非零部分之前始终增加数字(始终对非零舍弃部分前面的数字加1).注意,此舍入模式始终不会减少计算值的大小. 2. ...
- 【hive】 hive 加载数据
1. insert 插入数据 要保证启动了jobhistory 否则会抛出异常 hdfs中查看内容 2. create table 表名字 select 字段... from 表名 hdfs查看数据 ...
- io流和序列化
1.使用File操作文件 public class IoTest { public static void main(String[] args) throws IOException { /* 01 ...
- Linux 磁盘管理命令
df NO1. 显示所有存储系统空间使用情况,同时显示存储系统的文件系统类型s[root@rehat root]# df -aT NO2. 显示指定文件系统的空间使用情况[root@rehat roo ...
- PHP计算两个经纬度地点之间的距离
/** * 求两个已知经纬度之间的距离,单位为米 * * @param lng1 $ ,lng2 经度 * @param lat1 $ ,lat2 纬度 * @return float 距 ...
- go 的 mysql 的简单操作
关于 sql:https://studygolang.com/articles/3022 异常处理: http://www.jianshu.com/p/f30da01eea97 一.数据库的连接及初始 ...
- 关于SMI、MSI、SCI、INTx各种中断小结【转】
转载自http://blog.csdn.net/huangkangying/article/details/11178425 目录(?)[-] MSI VS INTxPin-based interru ...
- [Asp.net]缓存简介
写在前面 针对一些经常访问而很少改变的数据,使用缓存,可以提高性能.缓存是一种用空间换取时间的技术,说的直白点就是,第一次访问从数据库中读取数据,然后将这些数据存在一个地方,比如内存,硬盘中,再次访问 ...