目标检测(3)-SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
文章地址:https://arxiv.org/pdf/1406.4729.pdf
摘要
沿着上一篇RCNN的思路,我们继续探索目标检测的痛点,其中RCNN使用CNN作为特征提取器,首次使得目标检测跨入深度学习的阶段。但是RCNN对于每一个区域候选都需要首先将图片放缩到固定的尺寸(224*224),然后为每个区域候选提取CNN特征。容易看出这里面存在的一些性能瓶颈:
- 速度瓶颈:重复为每个region proposal提取特征是极其费时的,Selective Search对于每幅图片产生2K左右个region proposal,也就是意味着一幅图片需要经过2K次的完整的CNN计算得到最终的结果。
- 性能瓶颈:对于所有的region proposal防缩到固定的尺寸会导致我们不期望看到的几何形变,而且由于速度瓶颈的存在,不可能采用多尺度或者是大量的数据增强去训练模型。
但是为什么CNN需要固定的输入呢?CNN网络可以分解为卷积网络部分以及全连接网络部分。我们知道卷积网络的参数主要是卷积核,完全能够适用任意大小的输入,并且能够产生任意大小的输出。但是全连接层部分不同,全连接层部分的参数是神经元对于所有输入的连接权重,也就是说输入尺寸不固定的话,全连接层参数的个数都不能固定。
何凯明团队的SPPNet给出的解决方案是,既然只有全连接层需要固定的输入,那么我们在全连接层前加入一个网络层,让他对任意的输入产生固定的输出不就好了吗?一种常见的想法是对于最后一层卷积层的输出pooling一下,但是这个pooling窗口的尺寸及步伐设置为相对值,也就是输出尺寸的一个比例值,这样对于任意输入经过这层后都能得到一个固定的输出。SPPnet在这个想法上继续加入SPM的思路,SPM其实在传统的机器学习特征提取中很常用,主要思路就是对于一副图像分成若干尺度的一些块,比如一幅图像分成1份,4份,8份等。然后对于每一块提取特征然后融合在一起,这样就可以兼容多个尺度的特征啦。SPPNet首次将这种思想应用在CNN中,对于卷积层特征我们也先给他分成不同的尺寸,然后每个尺寸提取一个固定维度的特征,最后拼接这些特征不就是一个固定维度的输入了吗?
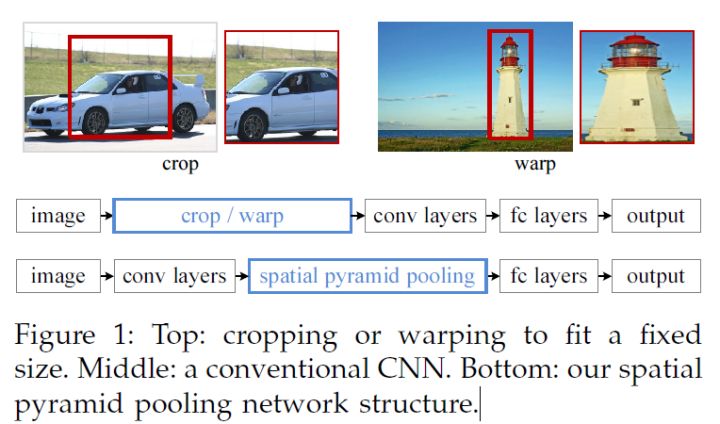
上面这个图可以看出SPPnet和RCNN的区别,首先是输入不需要放缩到指定大小。其次是增加了一个空间金字塔池化层,还有最重要的一点是每幅图片只需要提取一次特征。
通过上述方法虽然解决了CNN输入任意大小图片的问题,但是还是需要重复为每个region proposal提取特征啊,能不能我们直接根据region proposal定位到他在卷积层特征的位置,然后直接对于这部分特征处理呢?答案是肯定的,我们将在下一章节介绍。
网络细节
- 卷积层特征图

SPPNet通过可视化Conv5层特征,发现卷积特征其实保存了空间位置信息(数学推理中更容易发现这点),并且每一个卷积核负责提取不同的特征,比如C图175、55卷积核的特征,其中175负责提取窗口特征,55负责提取圆形的类似于车轮的特征。我们可以通过传统的方法聚集这些特征,例如词袋模型或是空间金字塔的方法。
- 空间金字塔池化层

上图的空间金字塔池化层是SPPNet的核心,其主要目的是对于任意尺寸的输入产生固定大小的输出。思路是对于任意大小的feature map首先分成16、4、1个块,然后在每个块上最大池化,池化后的特征拼接得到一个固定维度的输出。以满足全连接层的需要。不过因为不是针对于目标检测的,所以输入的图像为一整副图像。
- SPPNet应用于图像分类
SPPNet的能够接受任意尺寸图片的输入,但是训练难点在于所有的深度学习框架都需要固定大小的输入,因此SPPNet做出了多阶段多尺寸训练方法。在每一个epoch的时候,我们先将图像放缩到一个size,然后训练网络。训练完整后保存网络的参数,然后resize 到另外一个尺寸,并在之前权值的基础上再次训练模型。相比于其他的CNN网络,SPPNet的优点是可以方便地进行多尺寸训练,而且对于同一个尺度,其特征也是个空间金字塔的特征,综合了多个特征的空间多尺度信息。
- SPPNet应用于目标检测

SPPNet理论上可以改进任何CNN网络,通过空间金字塔池化,使得CNN的特征不再是单一尺度的。但是SPPNet更适用于处理目标检测问题,首先是网络可以介绍任意大小的输入,也就是说能够很方便地多尺寸训练。其次是空间金字塔池化能够对于任意大小的输入产生固定的输出,这样使得一幅图片的多个region proposal提取一次特征成为可能。SPPNet的做法是:
- 首先通过selective search产生一系列的region proposal,参见:目标检测(1)-Selective Search - 知乎专栏
- 然后训练多尺寸识别网络用以提取区域特征,其中处理方法是每个尺寸的最短边大小在尺寸集合中:
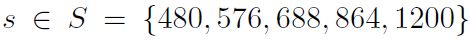
训练的时候通过上面提到的多尺寸训练方法,也就是在每个epoch中首先训练一个尺寸产生一个model,然后加载这个model并训练第二个尺寸,直到训练完所有的尺寸。空间金字塔池化使用的尺度为:1*1,2*2,3*3,6*6,一共是50个bins。
3.在测试时,每个region proposal选择能使其包含的像素个数最接近224*224的尺寸,提取相 应特征。
由于我们的空间金字塔池化可以接受任意大小的输入,因此对于每个region proposal将其映射到feature map上,然后仅对这一块feature map进行空间金字塔池化就可以得到固定维度的特征用以训练CNN了。关于从region proposal映射到feature map的细节我们待会儿去说。
4.训练SVM,BoundingBox回归
这部分和RCNN完全一致,参见:目标检测(2)-RCNN - 知乎专栏
- 实验结果
其中单一尺寸训练结果低于RCNN1.2%,但是速度是其102倍,5个尺寸的训练结果与RCNN相当,其速度为RCNN的38倍。
- 如何从一个region proposal 映射到feature map的位置?
SPPNet通过角点尽量将图像像素映射到feature map感受野的中央,假设每一层的padding都是p/2,p为卷积核大小。对于feature map的一个像素(x',y'),其实际感受野为:(Sx‘,Sy’),其中S为之前所有层步伐的乘积。然后对于region proposal的位置,我们获取左上右下两个点对应的feature map的位置,然后取特征就好了。左上角映射为:
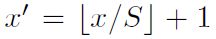
右下角映射为:

当然,如果padding大小不一致,那么就需要计算相应的偏移值啦。
- 存在的不足
和RCNN一样,SPP也需要训练CNN提取特征,然后训练SVM分类这些特征。需要巨大的存储空间,并且分开训练也很复杂。而且selective search的方法提取特征是在CPU上进行的,相对于GPU来说还是比较慢的。针对这些问题的改进,我们将在Fast RCNN以及Faster RCNN中介绍,敬请期待。
目标检测(3)-SPPNet的更多相关文章
- 目标检测(二) SPPNet
引言 先简单回顾一下R-CNN的问题,每张图片,通过 Selective Search 选择2000个建议框,通过变形,利用CNN提取特征,这是非常耗时的,而且,形变必然导致信息失真,最终影响模型的性 ...
- 第三十节,目标检测算法之Fast R-CNN算法详解
Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2 ...
- 目标检测算法(2)SPP-net
本文是使用深度学习进行目标检测系列的第二篇,主要介绍SPP-net:Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual R ...
- 【目标检测】R-CNN系列与SPP-Net总结
目录 1. 前言 2. R-CNN 2.0 论文链接 2.1 概述 2.2 pre-training 2.3 不同阶段正负样本的IOU阈值 2.4 关于fine-tuning 2.5 对文章的一些思考 ...
- 目标检测算法之R-CNN和SPPNet原理
一.R-CNN的原理 R-CNN的全称是Region-CNN,它可以说是第一个将深度学习应用到目标检测上的算法.后面将要学习的Fast R-CNN.Faster R-CNN全部都是建立在R-CNN基础 ...
- 论文翻译—SPP-Net(目标检测)
SPPNet论文翻译 <Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition> Kai ...
- 目标检测从入门到精通—SPP-Net详细解析(三)
SPP-Net网络结构分析 Author:Mr. Sun Date:2019.03.18 Loacation: DaLian university of technology 论文名称:<Spa ...
- 【目标检测】:SPP-Net深入理解(从R-CNN到SPP-Net)
一. 导论 SPP-Net是何凯明在基于R-CNN的基础上提出来的目标检测模型,使用SPP-Net可以大幅度提升目标检测的速度,检测同样一张图片当中的所有目标,SPP-Net所花费的时间仅仅是RCNN ...
- (三)目标检测算法之SPPNet
今天准备再更新一篇博客,加油呀~~~ 系列博客链接: (一)目标检测概述 https://www.cnblogs.com/kongweisi/p/10894415.html (二)目标检测算法之R-C ...
随机推荐
- 嵌入式开发之精确延时---多线程延时阻塞精度asm("nop") nanosleep usleep sleep select
http://blog.csdn.net/lile777/article/details/45503087
- winform利用ImageList控件和ListView控件组合制作图片文件浏览器
winform利用ImageList控件和ListView控件组合制作图片文件浏览器,见图,比较简单,实现LISTVIEW显示文件夹图片功能. 1.选择文件夹功能代码: folderBrowserDi ...
- 使用 GCD 实现倒计时效果
效果如下: ViewController.h #import <UIKit/UIKit.h> @interface ViewController : UIViewController @p ...
- 和我一起学Effective Java之类和接口
类和接口 使类和成员的可访问性最小 信息隐藏(information hiding)/封装(encapsulation):隐藏模块内部数据和其他实现细节,通过API和其他模块通信,不知道其他模块的内部 ...
- JSON 转JAVA代码
http://jsongen.byingtondesign.com/ http://pojo.sodhanalibrary.com/ http://www.jsonschema2pojo.org/
- [PGM] Temporal Models
这里的一些东西只是将过去已有的东西用PGM解释了一遍,但优势还是明显的,对整体认识有帮助. Video: https://www.youtube.com/watch?v=ogs4Oj8KahQ& ...
- c# 二十四小时制
是显示数据时时间格式化12小时制的问题 HH为24小时制 DataFormatString="{0:yyyy-MM-dd HH:mm:ss}" hh为12小时制 DataForma ...
- Linux里的2>&1究竟是什么
我们在Linux下经常会碰到nohup command>/dev/null 2>&1 &这样形式的命令.首先我们把这条命令大概分解下首先就是一个nohup表示当前用户和系统 ...
- 8 -- 深入使用Spring -- 5...3 使用@CacheEvict清除缓存
8.5.3 使用@CacheEvict清除缓存 被@CacheEvict注解修饰的方法可用于清除缓存,使用@CacheEvict注解时可指定如下属性: ⊙ value : 必须属性.用于指定该方法用于 ...
- 十一、K3 WISE 开发插件《VB插件开发如何代码调试 - 步骤讲解》
=================================== 目录: 1.配置代码调试启动程序kdmain.exe 2.设置断点 3.触发调试 4.变量跟踪 ================ ...