OLAP + MDX
基本概念
维度(Dimension):表示数据的属性,一个维度一般会有一个维表(也可能多个),事实表会有一个字段关联维表。
- 退化维度:有的维度可以没有维度表,因为这种维度比较简单,没有更多属性,没有必要加一个维度表。这种维度叫退化维度。比如事实表里有一个支付方式字段,只有已确定的有限几种取值,比如 cash(现金)、credit(信用卡)等。又比如事实表里已有了一个性别字段,那性别这个维度就不需要一个维表。
- 维度层次(Hierarchy):维度是可以有层次的,分层次的维度提供了更多的数据粒度选择。维度的层次包含多层/级,在维表中一般每层会有一个字段,事实表关联的是最低一级维度。比如 Time 维度,事实表关联的是维表的日期(yyyy-MM-dd)字段,而维表还有月、季度、年字段。有些事实表会增加月、季度、年(冗余)字段,为了在查询时减少关联维表。一个维度可以定义多套层次(Hierarchy)。比如时间维度,可同时按年、月、日和年、周、日各建立一套层次。在具体一次查询时,只能使用其中一套层次。
- 级别(Level):维度的层次可以包含多级(Level)。
- 成员(Member):维度的成员指的维表某个级别(Level)的一个取值。以时间维度为例,假设时间维度分为年份、季度、月份、日期这样的级别,时间跨度是 2003 年至 2005 年(假设每一天都要数据),那么日期这一级别(最低的级别)的成员(Members)是维度表所有的日期(2003-1-1,2003-1-2...2005-12-31)(1 千多个成员),月份这一级别的成员是 1-12(12个),季度的成员是 1-4(4 个),年份的成员是 2003-2005(3 个)。
聚集表(Aggregate Tables):在对事实表的查询分析中,很多时候都不会关注明细数据这一级别,而是更高的级别。比如事实表是保存到日期的,但查询分析大多时候都关注年、季度、月份级别。如果每次都从事实表查询的话,效率会比较低。最后是预先对事实表数据进行一些聚集,保存到一些表中,这些表叫聚集表。
- 如果数据库支持的话,聚集表也可使用物化视图。
- 如果数据存储是数据仓库,那么仓库建立完成后数据已包含各个层次的聚集数据了,不需要考虑这个问题。
- 按照不同的聚集维度、层次,这些聚集表会有很多。不一定所有可能的聚集表都有必要建立。查询频率很高、聚集后数据量减少很多的就有必要建立聚集表。
- 可以在系统运行一段时间后收集一些统计信息再分析哪些聚集表有必要建立。不一定每一个聚集表都需要从事实表聚集,从它更低的数据层次、粒度聚集就可以。
- 使用聚集表要考虑一致性问题,如果聚集的来源表数据更新了,那它应该重新生成。
SCHEMA:多维数据的事实表、维表、聚集表等存储于数据库中,属于物理模型;而Cube、维度、度量这些概念属于逻辑模型。多维分析引擎必须要理解逻辑模型,并能够映射到物理模型上。多维数据Schema就是用来描述这个逻辑模型以及到物理模型的映射的。
MDX基本概念
MDX(Multidimensional Expressions)是多维数据库(OLAP数据库)的查询语言,跟SQL是关系型数据库的查询语言类似。MDX早已成为事实标准。Mondrian 会解析 MDX,转换成SQL 来查询关系数据库(可能是多条查询)。
WITH
SET [~FILTER] AS
([日].[日].[] : [日].[日].[])
SET [~COLUMNS] AS
{[年月].[年月].[年月].Members}
SET [~ROWS_所属城市_所属城市] AS
{[所属城市].[所属城市].[所属城市].Members}
SET [~ROWS_运营类型大类_运营类型大类] AS
{[运营类型大类].[运营类型大类].[运营类型大类].Members}
SELECT
NON EMPTY CrossJoin([~COLUMNS], {[Measures].[总电量]) ON COLUMNS,
NON EMPTY Order(NonEmptyCrossJoin([~ROWS_所属城市_所属城市], [~ROWS_运营类型大类_运营类型大类]), [Measures].[总电量], DESC) ON ROWS
FROM [sqlserver_charge_cube2]
WHERE [~FILTER]
mdx 有类似 sql 的结构,同样有 select、from、where 这三部分。但也有很多不同。
- 1. Select 字句指定一个集合,把它放到某个轴上。
- 2. From 字句说明要从哪个cube来查询。
- 3. 方括号([])用于维度名、层次名、维度成员名,避免名字和函数混淆(函数名是不加方括号的),或者中间有空格或特殊符号。
- 4. Where 字句指定切片,即对不出现在轴上的维度的成员的限定。
- 5. Mdx 没有 group by 字句。其实分组是隐含的。
- 6. Mdx 没有 order by 字句。排序只会对某个轴进行,通过使用排序函数。
- 7. 和 sql 一样,mdx 也是不区分大小写的,并且可以随意分行。
- 8. Mdx 中也可以包含注释,除了支持 sql 的--注释外还支持//和/* ... */注释。
1、轴
- 用 on {axis} 语法来把维度分配到轴(Axis,复数 Axes)上,一个查询可以有多个轴。不同轴用逗号分隔,分配的顺序是没关系的。如 A on columns, B on rows 跟 B on rows, A on columns 是一样的。如果把轴调换(如 A on columns, B on rows 改成 A on rows, B on columns),结果的行和列也会转置过来。
- 轴用 axis(0),axis(1),axis(2)...表示,前五个轴可以使用别名 Columns,Rows,Pages,Chapters,Sections。因此 on Columns 等价于 on axis(0)。超过 5 个轴时只能用 axis(5),axis(6)...来表示(在大多查询中,轴一般是两个)。
- 很多实现(包括 Mondrian)支持仅用数字表示轴,因此 on Columns 可以写成 on 0。
- axis(0)和别名表示可以混用
- 轴必须从 0 开始,并且连续,不能跳过。
2、切片维度
- 切片(Slice)维度:就是出现在 MDX 语句 WHERE 子句中的维度,跟 SQL 一样,表示对数据集的限制。
- 切片维度不会出现在轴上。
- 一个维度不能同时出现在轴维度(SELECT 的维度)和切片维度上。
- 默认成员:如果一个维度既没有出现在轴维度上,也没有出现在切片维度上,就会用维度的(默认层次的)默认成员进行切片。一般维度的默认成员是“All xxx”,因此默认是对这个维度所有成员的数据进行聚集操作。
- 维度有一个函数 defaultMember 可以返回维度的默认成员
- 度量维度(为了一致可以把度量看成一个维度:Measures 维度)是没有”All xxx”成员的,它的默认成员可以明确设置,如果没设置,就是第一个度量。
- 一个维度的默认成员、是否有 All 成员(一般都应该有),是可以在 Schema 文件中设置的。如果没有明确设置默认成员,默认成员就是 All 成员,如果没有 All 成员,默认成员就是第一个成员。

3、元组
- 元组(Tuple)就是一个或多个维度的成员的组合,单个成员是一个简单的元组。
- 有多个维度的元组,必须用括号括起来,如下图:

- 不能用元组来构造元组,即元组不能嵌套
- 一个元组可以代表cube的一个切片(slice),这个切片由这些维度的成员切分而成。
- where字句就是一个元组,用以指定一个数据切片。
4、集合
- 集合(Set)只是一个一批已排序的元组。一个集合可以有一个元组,多个元组,或者是空的。不像数学上的集合,MDX 集合一个元组可以出现多次,而且顺序是重要的。
- 通常的指定集合的方式是把一个元组列表用花括号括起来。如上图,集合里是年月维度的5个成员。
- 一个集合中的所有元组必须有同样的维度性质,即所表示的维度及其顺序。
5、维度成员
- 要把维度成员放在轴上,可以列举维度的成员,如第3小节的图,也可以通过范围语法或一个函数得到成员的集合
- 成员范围:冒号(:)语法可以表示成员范围。冒号前后是同一个层次的起点和终点两个成员,如下图:

- 全部成员:大多时候需要得到一个维度、层次、层的全部成员,这个时候可以使用.Members 操作(函数)。比如[Time].[Years].Members 可以得到所有年份,[Product].[Line].Members 可以得到所有产品线。如下图:

- .Members 前面是维度、层次、层的名字。有时候需要得到某个成员的下一层次的全部成员,这是需要用.Children 函数
6、集合操作:NON EMPTY
- 在多维空间,数据很多时候是稀疏的,如果按维度所有成员交叉得出报表,就会有很多空行、空列。要从查询结果去掉这些空行(空切片),可以使用non empty关键字
- non empty 可用于任务轴上。如下图:

7、集合操作:CROSS JOIN
- 很多时候,我们需要对两个不同的集合进行交叉,也就是要得到集合成员的所有组合。CrossJoin()函数就是用来得到组合的最直接方式。
- 它的语法是CrossJoin (set1, set2)
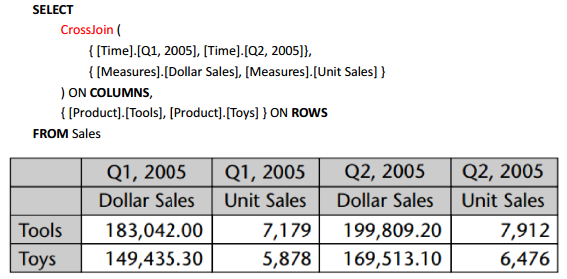
- CrossJoin 的结果是一个集合。因此如果有多个集合需要交叉,嵌套就可以了
8、集合操作:ORDER
- Order()函数用于对一个集合排序,语法是:Order (set1, expression[,ASC| DESC | BASC | BDESC])
- 最后排序标志默认是 ASC。ASC和 DESC 在保持层次的前提下排序,BASC 和BDESC 打破了层次(或者说忽略了层次)

schema结构
- Schema 文件主要结构如下:

- 示例如下:
<Schema>
<Cube name="Sales">
<Table name="sales_fact_1997"/>
<Dimension name="Gender" foreignKey="customer_id">
<Hierarchy hasAll="true" allMemberName="All Genders" primaryKey="customer_id">
<Table name="customer"/>
<Level name="Gender" column="gender" uniqueMembers="true"/>
</Hierarchy>
</Dimension>
<Dimension name="Time" foreignKey="time_id">
<Hierarchy hasAll="false" primaryKey="time_id">
<Table name="time_by_day"/>
<Level name="Year" column="the_year" type="Numeric" uniqueMembers="true"/>
<Level name="Quarter" column="quarter" uniqueMembers="false"/>
<Level name="Month" column="month_of_year" type="Numeric" uniqueMembers="false"/>
</Hierarchy>
</Dimension>
<Measure name="Unit Sales" column="unit_sales" aggregator="sum" formatString="#,###"/>
<Measure name="Store Sales" column="store_sales" aggregator="sum" formatString="#,###.##"/>
<Measure name="Store Cost" column="store_cost" aggregator="sum" formatString="#,###.00"/>
<CalculatedMember name="Profit" dimension="Measures" formula="[Measures].[Store Sales] - [Measures].[Store Cost]">
<CalculatedMemberProperty name="FORMAT_STRING" value="$#,##0.00"/>
</CalculatedMember>
</Cube>
</Schema>- 上面定义了一个 cube,名叫 Sales,包含两个维度:客户、时间,时间分为年、季、月三级;包含两个度量 Unit Sales 和 Store Cost,再加上一个派生(计算出来)的度量 Profit
1、Measure:
- Measure:必填属性:name,column(一个事实表的列),aggregator(一个聚集器)。
- aggregator: 通常为 sum,但 count,min,max,avg,distinct-count 都是可以的;distinct-count 会有一些限制如果立方体包含一个父子层次的话。
- datatype: 可选。指定 cell 数据值怎样在 mondrian 缓存中表示,以及怎样通过 XMLA 返回。datatype 属性可以是 String、Integer、Numeric、Boolean、Date、Time 以及 Timestamp,默认是 Numeric,除了是 count 或 distinct-count,这两个默认是 Integer。
- formatString:可选。指定显示样式,支持表达式。
- Measure 除了可以来自一个列,也可以使用一条 SQL 表达式来计算,如下:

- 为了一致,度量被视为一个特别的维度的成员,这个维度叫做 Measures。
2、Dimension/Hierarchy:
- Dimension:属性:name, foreignKey(事实表的列名)
- Hierarchy: primaryKey
- Level 的 column 定义了它的键,必须是这个层次所在表的列名。如果键是一个表达式,可以使用 KeyExpression 元素子元素
- Level、Measure 和 Property 的一些属性相应的嵌套元素:

- Level 元素的 uniqueMembers 属性用于优化 SQL 生成。如果知道一个层次列的取值在整个维表中即使跨越父层次的所有取值中都是唯一的,那就把 uniqueMembers 设为 true,否则设为 false。例如,时间维度分为年、月层次,在月层次上要把 uniqueMembers 设为 false,因为每年都有这些月。另一例子,如果有产品分类、产品层次,如果能够保证产品是唯一的(别的分类不会有同名产品,或者说,一个产品不会有多个分类),那么可以把uniqueMembers 设为 true。如果不确定,就设为 false。在顶层,uniqueMembers 总会是true,因为它没有父层次。
3、成员“ALL”
- 默认情况下,每套层次都包含一个顶级层次叫做“(All)”,它只包含单个叫“(All {层次名})”的成员。这个成员是这套层次中所有其他成员的父成员,因此表示一个累计值。它也是这套层次的缺省成员,意思是,如果这套层次没有出现在轴上或分片上,那就采用它来进行计算。
- 如果 Hierarchy 元素有 hasAll=”false”,“All”层次会被禁止。现在这一维度的缺省成员会变成第一个级别的第一个成员。例如,在时间维度层次,会变成第一个年份。修改缺省成员会带来混淆,因此一般都应该使用 hasAll=”true”。
- Hierarchy 元素同样有一个 defaultMember 属性,用以覆盖层次的缺省成员。以下把时间维度的缺省成员设为 1997 年的第一个季度:

4、多层次体系
- 一个维度可以由多个层次组成,如下:

- 注意第一个层次没有名字。默认第一个层次的名字跟维度的一样,因此第一个层次就叫”Time”。
5、退化维度
- 退化维度是指列的值过于简单而不值得为它创建一个维表。如下事实表中支付方式:
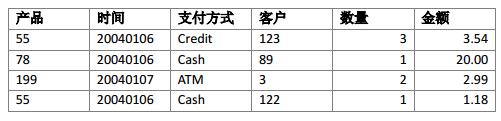
- 假设我们为支付方式列的值创建一个维表,这个维表没什么意义,它只有三个取值,没有额外的信息,并产生了额外的连接开销。这种情况可以创建一个退化维度,只要声明一个维度却不指定表,Mondrian 会认为这些列是来自事实表。

- 注意由于没有连接,Dimension 的 foreignKey 属性是不必要的,并且 Hierarchy 元素没有 Table 子元素或 primaryKey 属性。
6、样式
- 通过成员的 format_string 属性,可以设置单元格的样式,例如示意箭头或背景颜色。
- 箭头示例: |#.00%|arrow='down' / |#.00%|arrow='up' / |#.00%|arrow='none'

- 背景色示例 : |#.00%|style='green' / |#.00%|style='red'

OLAP + MDX的更多相关文章
- AMO olap Test C# generate tsql and mdx
通过AMO访问online的cube,生成等值的TSql和mdx 自动生成等值的TSQL和MDX进行Cube测试.其中难度比较大的部分是拼接TSQL. 暂时不处理calculations,只除理met ...
- XMLA ODBO 以及OLAP服务提供者自定义的协议,我们如何选择
参考 SAP给他的客户的帮助<ODBO, BAPI and XMLA - Sap> SAP BW 提供的查询接口: 接口 查询语言 调用接口 OS平台 客户端开发 ODBO MDX C ...
- SQL Analysis Services MDX 查询超时 解决办法
当页面有很多MDX语句查询的时候,会发生超时的情况. 解决办法: SQL Analysis Services所在的服务器(OLAP的文件夹下) 找到: msmdpump.ini 将: <Conf ...
- [saiku] olap数据源管理
一.应用场景 系统初始化的时候 如果没有创建olap数据源需要先创建olap数据源 否则直接获取所有的数据源存放在全局变量datasources里面以便于后续步骤中获取plap-connections ...
- Saiku OLAP
简介 Saiku成立于2008年,由Tom Barber和Paul Stoellberger研发.最初叫做Pentaho分析工具,起初是基于OLAP4J库用GWT包装的一个前端分析工具.经过多年的演化 ...
- MDX示例:求解中位数、四分位数(median、quartile)
一个人力资源咨询集团通过网络爬虫采集手段将多个知名招聘网站上发布的求职和招聘等信息准实时采集到自己的库里,形成一个数据量浩大的招聘信息库,跟踪全国招聘和求职的行业.工种.职位.待遇等信息,并通过商业智 ...
- 四大OLAP工具选型浅析
OLAP(在线分析处理)这个名词是在1993年由E.F.Codd提出来的,只是,眼下市场上的主流产品差点儿都是在1993年之前就已出来,有的甚至已有三十多年的历史了.OLAP产品不少,本文将主要涉及C ...
- Saiku关于MDX过滤的使用(九)
Saiku查询设定:Saiku查询数据时,每次都是全量查询的,我们现在需要默认展示近一周的数据. 通过编写使用MDX表达式进行过滤 通过编写MDX表达式,添加新的指标信息对一周以内的数据进行标识 (其 ...
- OLAP了解与OLAP引擎——Mondrian入门
一. OLAP的基本概念 OLAP(On-Line Analysis Processing)在线分析处理是一种共享多维信息的快速分析技术:OLAP利用多维数据库技术使用户从不同角度观察数据:OLAP ...
随机推荐
- LeetCode--016--最接近的三数之和(java)
给定一个包括 n 个整数的数组 nums 和 一个目标值 target.找出 nums 中的三个整数,使得它们的和与 target 最接近.返回这三个数的和.假定每组输入只存在唯一答案. 例如,给定数 ...
- SWUST OJ(963)
小偷的背包 #include<stdio.h> #include<stdlib.h> int s, flag, n, *a; //主函数之外定义的变量为全局变量 void df ...
- Lua 语言基本语法
第一个 Lua 程序 .交互式编程 Lua 提供了交互式编程模式.我们可以在命令行中输入程序并立即查看效果. Lua 交互式编程模式可以通过命令 lua -i 或 lua 来启用 .脚本式编程 我们可 ...
- 佛祖保佑永无BUG代码注释
// // _oo0oo_ // o8888888o // 88" . "88 // (| -_- |) // 0\ = /0 // ___/`---'\___ // .' \\| ...
- 单点登录系统实现基于SpringBoot
今天的干货有点湿,里面夹杂着我的泪水.可能也只有代码才能让我暂时的平静.通过本章内容你将学到单点登录系统和传统登录系统的区别,单点登录系统设计思路,Spring4 Java配置方式整合HttpClie ...
- Hive入门学习
Hive学习之路 (一)Hive初识 目录 Hive 简介 什么是Hive 为什么使用 Hive Hive 特点 Hive 和 RDBMS 的对比 Hive的架构 1.用户接口: shell/CLI, ...
- 使用ssm(spring+springMVC+mybatis)创建一个简单的查询实例(一)
梳理下使用spring+springMVC+mybatis 整合后的一个简单实例:输入用户的 ID,之后显示用户的信息(此次由于篇幅问题,会分几次进行说明,此次是工程的创建,逆向生成文件以及这个简单查 ...
- eclipse导入git项目出现There are no resources that can be added or removed from the server错误
上传到git上的项目因为配置了过滤文件,将.settings文件和.project文件都过滤掉了,settings文件中主要存放的是各种插件配置,约束你可以更好的利用IDE进行编码 因为将这两个文件过 ...
- Android开发 ---基本UI组件6 :只定义一个listView组件,然后通过BaseAdapter适配器根据数据的多少自行添加多个ListView显示数据
效果图: 1.activity_main.xml 描述: 定义了一个按钮 <?xml version="1.0" encoding="utf-8"?> ...
- html实现滚动播报(原生JS实现)
html实现滚动播报(原生JS实现) 废话不多说,先看一个简单的滚动效果(鼠标放上去的时候可以暂停滚动,谷歌版本 66.0.3359.139(正式版本)查看时会出现滚动混乱.单独提出来的时候不会,应该 ...