java基础 (三)之ConcurrentHashMap(转)
一、背景:
线程不安全的HashMap
效率低下的HashTable容器
//整个方法 加同步锁
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
} // Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
} addEntry(hash, key, value, index);
return null;
}
jdk10分割线
如果线程1在resize(),线程2要put 线程3要put 怎么办?
线程2 ,线程先帮助线程1扩容,从尾部开始每次执行16~32,如果线程2扩容完, 还有没扩容的在继续扩容1-16
在末尾添加元素 jdk1.7之前在头添加元素
初始化线程安全?
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//计算hash
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
//初始化
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
//数组初始化现在安全 并不是通过Synchronized而是通过CAS
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
//数组初始化 线程T1 进来 为0,T2线程在进来 是-1 然后执行yield()让步,让出cpu资源,让其他线程执行
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
//T1 执行else 代码 通过CAS 将 size 设置为-1
else if (U.compareAndSetInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
put:
判断table[i]是否有元素,
无,则table[i]=new node()
有 判断key是否相等相等用新值,替换旧值
判断是 treeNode 还是node
for (Node<K,V> e = f;; ++binCount) {
K ek;
//key 存在 ,新值替换原值
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//for 循环找到下个节点 存放
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
Synchronized 针对某个数组下标位置进行存放元素
锁,对象f table[i] 只会锁当前数组下标所在的元素
synchronized (f) { }
线程T1在扩容,线程T2,T3在put?线程T2,T3挂起,等T1执行完?耗时,等不起!,等不起就帮T1干活。每个线程领取一段,从后面往前推 T3领取16-32 ,T2领取1-16
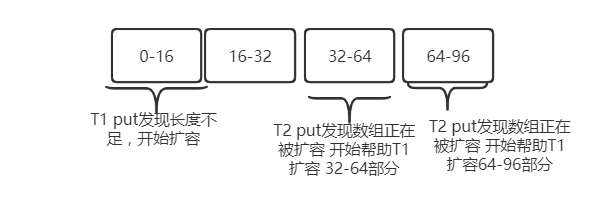
putVal 方法:
//其他线程正在扩容 设置当前节点内容为 hash为-1
static final int MOVED = -1; // hash for forwarding nodes
其他线程每次领取扩容长度 :
private static final int MIN_TRANSFER_STRIDE = 16;
tab = helpTransfer(tab, f);
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
if (U.compareAndSetInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
怎么进行扩容?
{
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
//元素存在
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//key不存在 ,链表方式存储 下一个节点为null 存放到下个节点的位置
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
jdk1.7分割线
锁分段技术
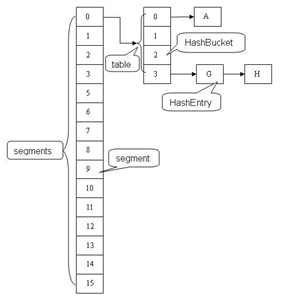
二、应用场景
三、源码解读
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
其它
定位操作:
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
hash计算方法:(todojdk1.6代码)
计算元素在数组Node[]的位置,高16位于低16位 进行异或运算在与运算
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
数据结构

static final class Segment<K,V> extends ReentrantLock implements Serializable {
/**
* The number of elements in this segment's region.
*/
transient volatileint count;
/**
* Number of updates that alter the size of the table. This is
* used during bulk-read methods to make sure they see a
* consistent snapshot: If modCounts change during a traversal
* of segments computing size or checking containsValue, then
* we might have an inconsistent view of state so (usually)
* must retry.
*/
transient int modCount;
/**
* The table is rehashed when its size exceeds this threshold.
* (The value of this field is always <tt>(int)(capacity *
* loadFactor)</tt>.)
*/
transient int threshold;
/**
* The per-segment table.
*/
transient volatile HashEntry<K,V>[] table;
/**
* The load factor for the hash table. Even though this value
* is same for all segments, it is replicated to avoid needing
* links to outer object.
* @serial
*/
final float loadFactor;
}
删除操作remove(key)
public V remove(Object key) {
hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
}
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
*for (HashEntry<K,V> p = first; p != e; p = p.next)
*newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}


get操作
V get(Object key, int hash) {
if (count != 0) { // read-volatile 当前桶的数据个数是否为0
HashEntry<K,V> e = getFirst(hash); 得到头节点
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
returnnull;
}
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
put操作
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
- 是否需要扩容。在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阀值,数组进行扩容。值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容。
- 如何扩容。扩容的时候首先会创建一个两倍于原容量的数组,然后将原数组里的元素进行再hash后插入到新的数组里。为了高效ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
boolean containsKey(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key))
returntrue;
e = e.next;
}
}
returnfalse;
}
size()操作
java基础 (三)之ConcurrentHashMap(转)的更多相关文章
- Java 基础三、接口与内部类
1. 在Java程序语言中,接口是对类的一种描述.例如Arrays类中sort方法声明可以对对象进行排序,但前提是对象所属的类必须实现Comparable接口. public interface ...
- java基础系列之ConcurrentHashMap源码分析(基于jdk1.8)
1.前提 在阅读这篇博客之前,希望你对HashMap已经是有所理解的,否则可以参考这篇博客: jdk1.8源码分析-hashMap:另外你对java的cas操作也是有一定了解的,因为在这个类中大量使用 ...
- java基础(三)
1.枚举类,使用enum定义的枚举类默认继承java.lang.Enum,而不是Object类.枚举类的所有实例必须在枚举类中显示列出,否则这个枚举类永远都不能产生实例.相关内容较多,需要后续继续跟进 ...
- java基础三种循环的使用及区别
摘要:Java新人初学时自己的一些理解,大神们路过勿喷,有什么说的不对不足的地方希望能给予指点指点,如果觉得可以的话,希望可以点一个赞,嘿嘿,在这里先谢了.在这里我主要说的是初学时用到的Java三个循 ...
- java 基础三
1 运算符 1.1 比较运算符 比较运算符的结果都是boolean类型,也即是要么是true,要么是false. 比较运算符"=="不能写成"=". > ...
- Java基础(三)-final关键字分析
今天来谈谈final关键字的作用, 虽然有很多博文关于final进行了很深的研究,但还是要去记录下谈谈自己的见解加深下印象.下面直接进入主题: 一.final关键字的作用 1.被final修饰的类不能 ...
- java基础(三)-----java的三大特性之多态
面向对象编程有三大特性:封装.继承.多态. 封装隐藏了类的内部实现机制,可以在不影响使用的情况下改变类的内部结构,同时也保护了数据.对外界而已它的内部细节是隐藏的,暴露给外界的只是它的访问方法. 继承 ...
- java基础(三):反射、反序列化破解单列模式和解决方式
单例模式指的是一个类只有一个对象,通过一些措施达到达到这个目的.但是反射和反序列化可以获得多个不同的对象. 先简单的认识一下单例模式 一:单例模式 通过私有构造器,声明一个该类的静态对象成员,提供一个 ...
- Java基础三(Scanner键盘输入、Random随机数、流程控制语句)
1.引用类型变量的创建及使用2.流程控制语句之选择语句3.流程控制语句之循环语句4.循环高级 ###01创建引用类型变量公式 * A: 创建引用类型变量公式 * a: 我们要学的Scanner类是属于 ...
- java基础(三) 加强型for循环与Iterator
引言 从JDK1.5起,增加了加强型的for循环语法,也被称为 "for-Each 循环".加强型循环在操作数组与集合方面增加了很大的方便性.那么,加强型for循环是怎么解析的 ...
随机推荐
- 补充:MySQL经典45道题型
一. 设有一数据库,包括四个表:学生表(Student).课程表(Course).成绩表(Score)以及教师信息表(Teacher). 四个表的结构分别如表1-1的表(一)~表 ...
- sj 网页前端与后台数据交互的3种方式
1.ajax 网页访问 2.form 表单 用户名<input class="yonghu" type="text" id="user&quo ...
- ajaxFileUpload只能上传一次,和上传同名图片不能上传等bug问题
createUploadForm: function (id, fileElementId) { //create form var formId = 'jUploadForm' + id; var ...
- Java中Integer和int的异同
public void Test1() { int a = 128; Integer b = 128; Integer c = 128; //Integer会自动拆箱成int,所以为ture Syst ...
- nginx基本用法和HTTPS配置
nginx作用讲解:1.反向代理:需要多个程序共享80端口的时候就需要用到反向代理,nginx是反向代理的一种实现方式.2.静态资源管理:一般使用nginx做反向代理的同时,应该把静态资源交由ngin ...
- 学习gstreamer
1. 对gst 的框架认识. 第一篇文章有结构图说明,清楚易懂:第二篇文章介绍了gst的简单使用 http://www.cnblogs.com/jingzhishen/p/3709639.html h ...
- Selenium IDE
Selenium IDE : Selenium IDE作为Firefox浏览器的一款插件,依附于firefox浏览器,打开它的录制功能,它会忠实的记录,你对firefox的操作,并可以回放它所记录的你 ...
- sql server创建windows账户
--不要干坏事 sql server中使用xp_cmdshell --1.允许配置高级选项 GO RECONFIGURE GO --2.开启xp_cmdshell服务 RECONFIGURE GO - ...
- 转换编码utf-8
用这个enca -x utf-8 * 或者是 filename,还有别的方法,参见:https://blog.csdn.net/a280606790/article/details/8504133 我 ...
- sql server调优
SQLServer调优:查询语句运行几个指标值监测\ https://www.cnblogs.com/zhijianliutang/p/4179110.html