Paper | 亚像素运动补偿 + 视频超分辨
目录
论文:Detail-revealing Deep Video Super-resolution
Tao, Xin, et al. "Detail-revealing deep video super-resolution." Proceedings of the IEEE International Conference on Computer Vision. 2017.
Over 40 citations (2019).
1. ABSTRACT
摘要是最亮眼的部分,需要简洁明了地点出:
- 简要背景介绍,及其存在的问题或者动机。
- 提出的方法。
- 达到的效果。
作者指出,视频超分辨中最关键的环节,是从相邻帧中获取有效信息。
获取方法无非是 frame alignment 和运动补偿。
而作者正是通过引入 SPMC layer ,实现了更合理的 frame alignment ,从而取得了更好的效果。
- 之前的基于 CNN 的视频超分辨方法,需要 align multiple frames to the reference 。
我们发现,合理的 frame alignment 和运动补偿,对超分辨结果非常关键。- 我们提出了 sub-pixel motion compensation (SPMC) 层。
- 该运动补偿层在 SR 网络中的适应性很好,与整体 CNN 网络配合默契,效果超过了 state-of-the-art 且不需要调参。
2. INTRODUCTION
Introduction 是对工作的概述,说白了就是对 Abstract 的全面拓展。注意以下几点:
- 在介绍动机或解决的问题时,只需要简要说明前人的工作,但目的是引出自己工作的不同和进步。
回顾前人工作不能太详细,详细部分在后面的 Related Work 部分。 - 贡献点是需要着重强调的,最好有最精炼、最亮眼的数据支持。详细数据也应该
首先作者再次强调了 alignment 对视频 SR 的重要性。这实际上也是 Motivation 。
其次,作者用两个大标题:Motion Compensation 和 Detail Fusion ,回答了 Motivation 中需要解决的两大核心问题。
最后,作者再用一个大标题:Scalability ,补充阐述了本文的第三大贡献点。
这种写作方式值得借鉴,在分段概述工作的同时,还说清楚了贡献点,简洁明了。
图像 SR 只能从 external 样本中获取先验知识(因为测试集和训练集是分开的);但对于一个好的视频 SR 系统,它必须能够从多帧中提取信息,而不借助外部力量(其他视频的样本)。
因此,多帧 align 和 fuse 是视频 SR 的两大核心问题。
Motion Compensation
帧间的剧烈运动,使得我们很难在多帧中寻找同一物体。但是,亚像素的运动是微小的,因此有助于细节的恢复。
大多数前人的工作,都通过预测 optical flow 或通过 block-matching ,来实现帧间运动补偿。
补偿完了,再用传统的方法重建 HR 图像。这种方法计算量很大。
近期的深度学习方法,是通过 backward warping 来实现运动补偿的。
我们将要证明,这个看上去合理的方法,实际上对视频 SR 而言是不合理的!通过改进运动补偿机制,SR 效果可以提升。
我们提出的是 SPMC 策略,我们将从理论分析和实验上验证它。
Detail Fusion
当然了,这一部分是 SR 的第二个核心问题。
我们提出了新的 CNN 网络,来与 SPMC 协同合作。
尽管前人的 CNN 网络也可以输出边缘清晰的图像,但是,我们不清楚这些细节是从输入中得到的,还是从外部数据中得到的(训练得到的先验知识)。
后果是,在人脸识别、文字识别等实际应用中,只有真实的细节是有效的。
因此,本文会提供 insightful ablation study ,来验证这一观点。
Scalability
这是一个一直以来被忽视,但在应用中很有意义的 SR 系统特点:可放缩性。
之前的基于学习的网络,受参数影响很大。如果输入的格式不同,那么训练好的网络参数可能就不能用了。
与之相反,我们的网络具有完全的可放缩性。
- 我们的网络可以接收任意大小的输入;
- SPMC 不含任何可训练参数,因此缩放倍数可随意选择;
- 我们的 Conv-LSTM 可以接收任意数量的图片。
3. RELATED WORKS
要按时间顺序,列举具有代表性的重要工作,并且指出本文工作的不同点。
要分别介绍不同环节各自的 Relative work 。
4. SUB-PIXEL MOTION COMPENSATION (SPMC)
概述和铺垫都介绍完了,以下是正文时刻。
网络的不同环节,可以分为多个章节介绍。这就是第一个环节。
在介绍前,一定要说清楚 notations 。有时候借助 notations ,后文讲解起来也更轻松。
在这里,作者定义了帧、帧序列和降质过程:

这部分是理论分析,旨在强调:作第0帧到第i帧的变形( warp ),要比反向变形更合理。
而之前的深度学习工作,几乎都是后者:从第i帧变形到第0帧,再用于补偿。这样做是直观上合理的。
但是,作者接下来指出:前者更有其合理性,是从理论上推导可得的。
首先看涉及到的操作的图解:
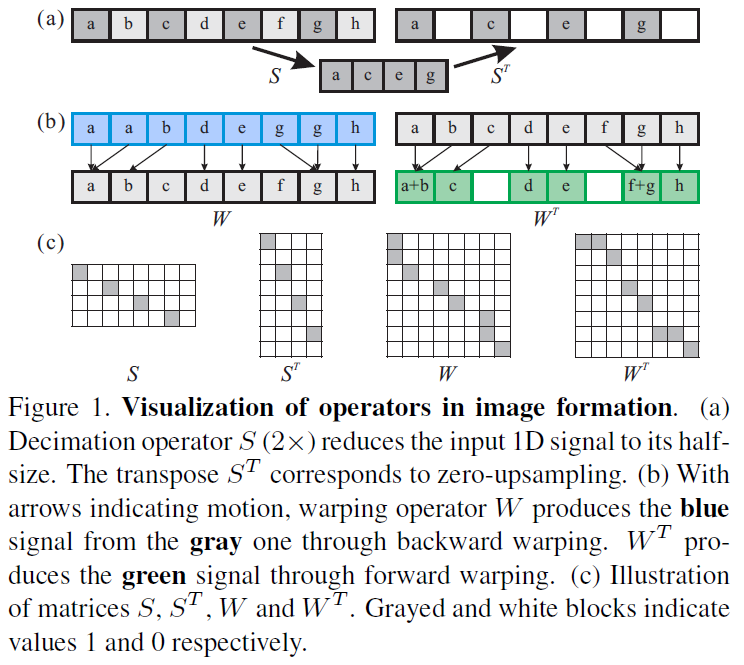
很有意思的是,我们可以把这些操作都理解为矩阵运算。
首先,每一张图片都是一个列向量。如果是一张 8x8 的图片,那么该向量维度就是64。向量中的元素非0即1。
其次,我们对图片的操作有两种:降采样和形变。
如果是2倍降采样,那么 LR 图片是 4x4 的,降采样矩阵就应该是 16x64 。形变矩阵恒为 8x8 。
通过矩阵转置,我们可以看出这两种操作的转置操作的物理意义:降采样的转置是补零升采样,形变的转置操作结果看图,会产生一些新的元素。
注意,转置操作虽然不是逆操作,但操作方向是相反的。如果我们定义正向为第0帧到第i帧,那么转置操作就是从第i帧到第0帧。
那么为什么从第0帧到第i帧的 warp 更合理呢?
假设我们现在有一个 LR 视频序列,每一帧都是 LR 的。
借助降质模型,我们可以从 HR 的第0帧开始,变形到附近的多个i帧,然后降采样。
最后,和 LR 视频中原有的第i帧作差,关于i求和。
如果能使得该误差最小,那么 HR 的第0帧就最有可能是我们想要的。

式(2)推导比较简单。
在我们前面的维度假设下,范数内部是一个列向量。因此其二次范数就是转置和其自身的乘积。
展开矩阵乘法,求其关于 HR 的极小值点,也就是偏导为0点,结果即(2)。
其中二次型偏导参考我的博客:https://www.cnblogs.com/RyanXing/p/9487245.html
然后,根据参考文献提供的假设,第一项求和号内可以变成一个对角阵。因此最终结果可以简化为(3)式。
式(3)的推导可以稍微在纸上写一写。
首先,既然可以变成对角阵,那么我们就只考虑对角线上的元素。
注意,\(W^TS^TSW\) 实际上是 \((SW)^T\) 和 \(SW\) 的乘积。
因此,每一个对角线上的元素,实际上是 \(SW\) 每一列自身的点积结果。
而对角阵的求逆,实际上就是对角线上元素都求倒数。这就是分数线的由来。
p.s. 个人认为这个式子写错了,因为点积不能简化成列向量内部求和(全1向量的作用)。当然也有可能是我一开始维度考虑错了。
总之,以上提到的矩阵操作,并非最终的实现。因为我们不做简单的线性映射。
上述推导是为了说明,由于最终结果中不存在逆向变形项,说明只有正向变形项参与了误差最小化过程。因此正向变形比逆向变形更合理。
5. OUR METHOD
终于到了最终实现了。整个网络是端到端的,分为3个模块,如图:
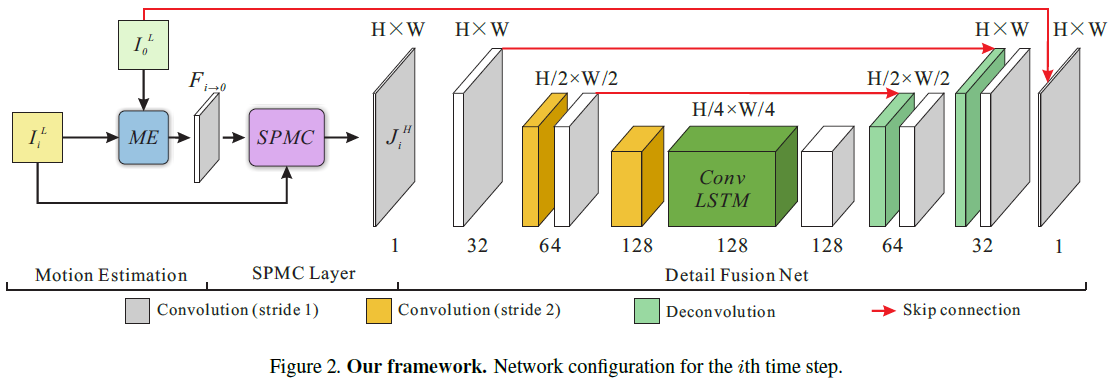
5.1. Motion Estimation and SPMC
首先是 Motion estimation ,得到 motion field: \(F_{i \to 0}\) 及坐标增量,用以后面的运动补偿。
其次是 Motion compensation ,通过 SPMC 层完成:
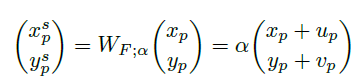
这个式子是精髓。如果只做运动补偿,那么加上 \(F_{i \to 0}\) 提供的坐标增量 \(u_p\) 和 \(v_p\) 就可以了。\(p\) 指的是 LR 图片中每一个像素的位置索引。
但是,作者加入了放缩系数 \(\alpha\) ,使得运动补偿和超分辨同时完成!如图:
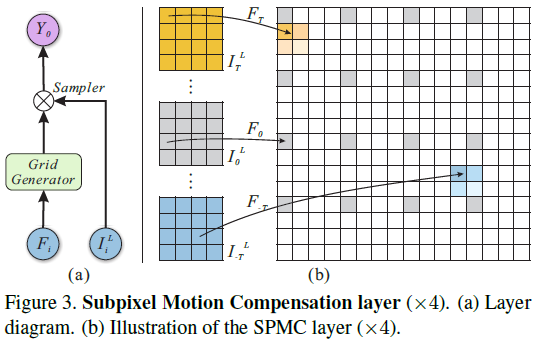
由于运动补偿增量和放缩系数的乘积可以是小数,因此是亚像素层次的,比较灵活。
在这种方法下,超分辨率功能不需要独立训练。
对比之前的转置卷积、重排等操作,升维核或前面的通道都需要缜密的训练。
注意还没完,这种简单的放缩得到的图像,其格式不一定是符合要求的(不一定在格点上,还有可能不全)。
因此,我们利用( HR 要求的格点)与(放大图像的各点)的距离,进行插值。
这样,我们就得到了 HR 图像:i帧。
重复前面的操作,我们会得到大量的 HR 帧序列,称为 \(\{J_i^H\}\) 。
5.2. Detail Fusion Net
接下来的网络会面临以下几点问题:
- 由于输入是 HR 图像,因此通道尺寸会比较大,计算成本高。
- 由于正向变形和补0升采样,4xHR 图像中大约 15/16 的格点都会是0。
- 我们既要重视参考帧(因为 LR 和 HR 的图像结构是大致相同的),又不能过于依赖参考帧(否则和图片 SR 效果类似了)。
因此,最终网络设计考虑了以下几点:
- 先降维,而且是长宽各减半,减小计算成本;
- 在中央使用 Conv-LSTM ,既利用了帧间信息,又利用了帧内信息;
- 多处使用 Skip connection ,加快训练。
由于我们输入 FlowNet 的序列是从 \(t=-T\) 到 \(t=T\) 的视频序列,因此我们会得到 \(2T+1\) 个正向变形的 HR 帧,作为 DF Net 的输入。
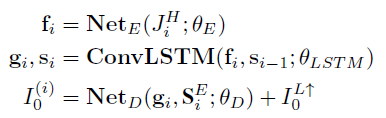
如果对 LSTM 的 time_step 不理解,请参考这个答案:LSTM神经网络输入输出究竟是怎样的? - Scofield的回答 - 知乎
由于 Conv-LSTM 的输入是 2T+1 帧分别经编码网络的输出,因此 Conv-LSTM 的 time step 应该设为 2T+1 ,也就是输入的尺寸。
每一个时间步,输出的是当前时序对应的向量;因此经过 2T+1 个时间步后,才会得到完整的所有帧的对应输出。
最后,由于解码网络只需要学习变形后的附加量,来形成最终的 HR ,因此编码网络的 feature maps 被短接到解码网络中。
6. TRAINING STRATEGY
说清楚训练步骤、配置和损失函数定义。
3个阶段的训练是分开进行的,因为合在一起容易导致断流,使最终结果趋于图片 SR 。
6.1. FlowNet
第一阶段当然是训练 FlowNet :

只需要和真实的 LR 第i帧作差即可。
6.2. DF Network
SPMC 不需要训练,是一个借助 \(F\) 和放大倍数的简单过程。
首先我们固定前面的网络参数。
其次,由于每一个时间步都会输出完整的结果,但显然越到后面越可靠。
因此,分别赋予不同时间步的 MSE 以权重0.5~1,再加起来作为loss。
最后一步是联调。
7. 实验
实验设置非常丰富,首先说明了建库过程,然后说明了训练过程,包括迭代步数、技术细节,最后,分别用实验说明:
- SPMC 层的作用;
- 输入数量、质量对输出的影响;
- 和其他视频 SR 方法的比较;
- 和其他图片 SR 方法的比较。
最后还有复杂度比较,比较了其与其他算法的运行时间,结果是显著低。
Paper | 亚像素运动补偿 + 视频超分辨的更多相关文章
- 寻找Harris、Shi-Tomasi和亚像素角点
Harris.Shi-Tomasi和亚像素角点都是角点,隶属于特征点这个大类(特征点可以分为边缘.角点.斑点). 一.Harris角点检测是一种直接基于灰度图像的角点提取算法,稳定性较高,但是也可能出 ...
- OpenCV亚像素角点cornerSubPixel()源代码分析
上一篇博客中讲到了goodFeatureToTrack()这个API函数能够获取图像中的强角点.但是获取的角点坐标是整数,但是通常情况下,角点的真实位置并不一定在整数像素位置,因此为了获取更为精确的角 ...
- 亚像素Sub Pixel
亚像素Sub Pixel 评估图像处理算法时,通常会考虑是否具有亚像素精度. 亚像素概念的引出: 图像处理过程中,提高检测方法的精度一般有两种方式:一种是提高图像系统的光学放大倍数和CCD相机的分辨率 ...
- OpenCV亚像素级的角点检测
亚像素级的角点检测 目标 在本教程中我们将涉及以下内容: 使用OpenCV函数 cornerSubPix 寻找更精确的角点位置 (不是整数类型的位置,而是更精确的浮点类型位置). 理论 代码 这个教程 ...
- opencv亚像素级角点检测
一般角点检测: harris cv::cornerHarris() shi-tomasi cv::goodFeaturesToTrack() 亚像素级角点检测是在一般角点检测基础之上将检测出的角点精确 ...
- 未来直播 “神器”,像素级视频分割是如何实现的 | CVPR 冠军技术解读
被誉为计算机视觉领域 "奥斯卡" 的 CVPR 刚刚落下帷幕,2021 年首届 "新内容 新交互" 全球视频云创新挑战赛正火热进行中,这两场大赛都不约而同地将关 ...
- 【工程应用七】接着折腾模板匹配算法 (Optimization选项 + no_pregeneration模拟 + 3D亚像素插值)
在折腾中成长,在折腾中永生. 接着玩模板匹配,最近主要研究了3个课题. 1.创建模型的Optimization选项模拟(2022.5.16日) 这两天又遇到一个做模板匹配隐藏的高手,切磋起来后面就还是 ...
- Kindle Paper White 使用感受视频上线啦!
大家可以通过以下链接前往我的主页观看视频哦! https://www.youtube.com/watch?v=CESqzxTrAq4&t=322s 欢迎大家点赞.关注! 这期视频用iPhone ...
- OpenCV——Harris、Shi Tomas、自定义、亚像素角点检测
#include <opencv2/opencv.hpp> #include <iostream> using namespace cv; using namespace st ...
随机推荐
- 怎样让scrollview滚动到底部?
- (void)scrollsToBottomAnimated:(BOOL)animated { CGFloat offset = self.tableView.contentSize.height ...
- IntelliJ IDEA 中创建maven项目
IDEA作为最好得开发工具之一集成了maven工具,今天记录一下我创建使用idea创建maven项目 1.双击IDEA图标,进入到如下界面,在该页面中,点击箭头所示的“Create New Proje ...
- 清除eclipse,STS workspace历史记录
记一下 打开eclipse下的/configuration/.settings目录 修改文件org.eclipse.ui.ide.prefs文件 把RECENT_WORKSPACES这项修改为你需要的 ...
- python大法好——Python2.x与3.x版本区别
python大法好——Python2.x与3.x版本区别 Python的3.0版本,常被称为Python 3000,或简称Py3k.相对于Python的早期版本,这是一个较大的升级. 为了不带 ...
- leetcode146
public class LRUCache { ; ; long sernumbers; long SerNumbers { get { if (sernumbers <= long.MaxVa ...
- css:元素水平垂直居中的多种方式
CSS元素(文本.图片)水平垂直居中方法 1.text-align:center; 2.margin:0 auto; 3.display:inline-block; + text-align:ce ...
- Vue开源项目汇总(史上最全)(转)
目录 UI组件 开发框架 实用库 服务端 辅助工具 应用实例 Demo示例 UI组件 element ★13489 - 饿了么出品的Vue2的web UI工具套件 Vux ★8133 - 基于Vue和 ...
- ReactNative项目结构目录详解
在使用 react-native init TestProject 在新建项目时,会看到如下目录 React Native结构目录 名称 描述 android目录 Android项目目录,包含了使用A ...
- DML DDL DCL
转自:https://blog.csdn.net/level_level/article/details/4248685
- API接口认证
restful API接口可以很方便的让其他系统调用,为了让指定的用户/系统可以调用开放的接口,一般需要对接口做认证; 接口认证有两种方式: 1.认证的token当做post/get的参数,serve ...