cpp 区块链模拟示例(六) 交易
交易(transaction)是比特币的核心所在,而区块链的唯一目的,也正是为了能够安全可靠地存储交易。在区块链中,交易一旦被创建,就没有任何人能够再去修改或是删除它。在今天的文章中,我们会实现交易的通用机制。
如果以前开发过 web 应用,在支付的实现环节,你可能会在数据库中创建这样两张表:
- accounts
- transactions
account(账户)会存储用户信息,里面包括了个人信息和余额。transaction(交易)会存储资金转移信息,也就是资金从一个账户转移到另一个账户这样的内容。在比特币中,支付是另外一种完全不同的方式:
- 没有账户(account)
- 没有余额(balance)
- 没有住址(address)
- 没有货币(coin)
- 没有发送人和接收人(sender,receiver)(这里所说的发送人和接收人是基于目前现实生活场景,交易双方与人是一一对应的。而在比特币中,“交易双方”是地址,地址背后才是人,人与地址并不是一一对应的关系,一个人可能有很多个地址。)
鉴于区块链是一个公开开放的数据库,所以我们并不想要存储钱包所有者的敏感信息(所以具有一定的匿名性)。资金不是通过账户来收集,交易也不是从一个地址将钱转移到另一个地址,也没有一个字段或者属性来保存账户余额。交易就是区块链要表达的所有内容。那么,交易里面到底有什么内容呢?
比特币交易
一笔交易由一些输入(input)和输出(output)组合而来:
typedef struct txoutput {
int value;
string scriptPubKey;
}TXOutput;
typedef struct txinput {
string txid;
int vout;
string scriptSig;
}TXInput;
typedef struct transaction {
string id;
vector<TXInput> vin;
vector<TXOutput> vout;
}Transaction;
对于每一笔新的交易,它的输入会引用(reference)之前一笔交易的输出(这里有个例外,也就是我们待会儿要谈到的 coinbase 交易)。所谓引用之前的一个输出,也就是将之前的一个输出包含在另一笔交易的输入当中。交易的输出,也就是币实际存储的地方。下面的图示阐释了交易之间的互相关联:
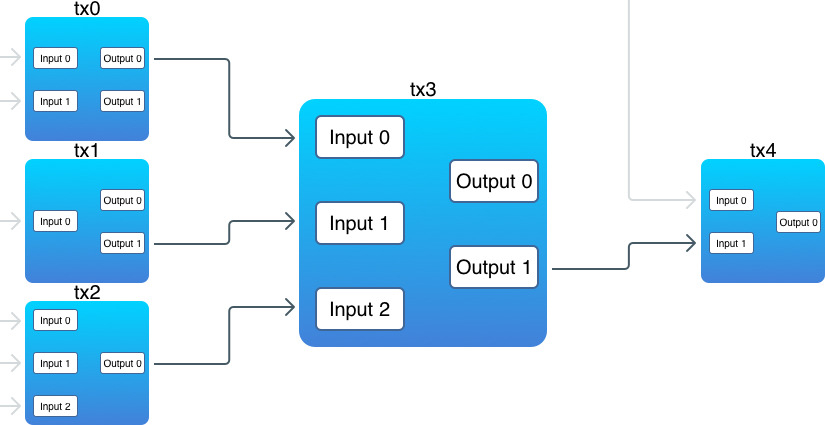
注意:
- 有一些输出并没有被关联到某个输入上
- 一笔交易的输入可以引用之前多笔交易的输出
- 一个输入必须引用一个输出
贯穿本文,我们将会使用像“钱(money)”,“币(coin)”,“花费(spend)”,“发送(send)”,“账户(account)” 等等这样的词。但是在比特币中,实际并不存在这样的概念。交易仅仅是通过一个脚本(script)来锁定(lock)一些价值(value),而这些价值只可以被锁定它们的人解锁(unlock)。
交易输出
让我们先从输出(output)开始:
typedef struct txoutput {
int value;
string scriptPubKey;
}TXOutput;
实际上,正是输出里面存储了“币”(注意,也就是上面的 Value 字段)。而这里的存储,指的是用一个数学难题对输出进行锁定,这个难题被存储在 ScriptPubKey 里面。在内部,比特币使用了一个叫做 Script 的脚本语言,用它来定义锁定和解锁输出的逻辑。虽然这个语言相当的原始(这是为了避免潜在的黑客攻击和滥用而有意为之),并不复杂,但是我们并不会在这里讨论它的细节。你可以在这里 找到详细解释。
在比特币中,
value字段存储的是 satoshi 的数量,而不是>有 BTC 的数量。一个 satoshi 等于一百万分之一的 >BTC(0.00000001 BTC),这也是比特币里面最小的货币单位>(就像是 1 分的硬币)。
由于还没有实现地址(address),所以目前我们会避免涉及逻辑相关的完整脚本。ScriptPubKey 将会存储一个任意的字符串(用户定义的钱包地址)。
顺便说一下,有了一个这样的脚本语言,也意味着比特币其实也可以作为一个智能合约平台。
关于输出,非常重要的一点是:它们是不可再分的(invisible),这也就是说,你无法仅引用它的其中某一部分。要么不用,如果要用,必须一次性用完。当一个新的交易中引用了某个输出,那么这个输出必须被全部花费。如果它的值比需要的值大,那么就会产生一个找零,找零会返还给发送方。这跟现实世界的场景十分类似,当你想要支付的时候,如果一个东西值 1 美元,而你给了一个 5 美元的纸币,那么你会得到一个 4 美元的找零。
交易输入
这里是输入:
typedef struct txinput {
string txid;
int vout;
string scriptSig;
}TXInput;
正如之前所提到的,一个输入引用了之前一笔交易的一个输出:Txid 存储的是这笔交易的 ID,Vout 存储的是该输出在这笔交易中所有输出的索引(因为一笔交易可能有多个输出,需要有信息指明是具体的哪一个)。ScriptSig 是一个脚本,提供了可作用于一个输出的 ScriptPubKey 的数据。如果 ScriptSig 提供的数据是正确的,那么输出就会被解锁,然后被解锁的值就可以被用于产生新的输出;如果数据不正确,输出就无法被引用在输入中,或者说,也就是无法使用这个输出。这种机制,保证了用户无法花费属于其他人的币。
再次强调,由于我们还没有实现地址,所以 ScriptSig 将仅仅存储一个任意用户定义的钱包地址。我们会在下一篇文章中实现公钥(public key)和签名(signature)。
来简要总结一下。输出,就是 “币” 存储的地方。每个输出都会带有一个解锁脚本,这个脚本定义了解锁该输出的逻辑。每笔新的交易,必须至少有一个输入和输出。一个输入引用了之前一笔交易的输出,并提供了数据(也就是 ScriptSig 字段),该数据会被用在输出的解锁脚本中解锁输出,解锁完成后即可使用它的值去产生新的输出。
也就是说,每一笔输入都是之前一笔交易的输出,那么从一笔交易开始不断往前追溯,它涉及的输入和输出到底是谁先存在呢?换个说法,这是个鸡和蛋谁先谁后的问题,是先有蛋还是先有鸡呢?
先有蛋
在比特币中,是先有蛋,然后才有鸡。输入引用输出的逻辑,是经典的“蛋还是鸡”问题:输入先产生输出,然后输出使得输入成为可能。在比特币中,最先有输出,然后才有输入。换而言之,第一笔交易只有输出,没有输入。
当矿工挖出一个新的块时,它会向新的块中添加一个 coinbase 交易。coinbase 交易是一种特殊的交易,它不需要引用之前一笔交易的输出。它“凭空”产生了币(也就是产生了新币),这也是矿工获得挖出新块的奖励,可以理解为“发行新币”。
在区块链的最初,也就是第一个块,叫做创世块。正是这个创世块,产生了区块链最开始的输出。对于创世块,不需要引用之前交易的输出。因为在创世块之前根本不存在交易,也就没有不存在有交易输出。
来创建一个 coinbase 交易:
Transaction* NewCoinbaseTX(string to, string data) {
if (data == "")
data = "Reward to " + to;
TXInput txin = TXInput{ "",-,data };
TXOutput txout = TXOutput{ subsidy ,to };
Transaction* tx = new Transaction();
tx->id = "";
tx->vin.push_back(txin);
tx->vout.push_back(txout);
SetID(tx);
return tx;
}
coinbase 交易只有一个输出,没有输入。在我们的实现中,它的 Txid 为空,Vout 等于 -1。并且,在目前的视线中,coinbase 交易也没有在 ScriptSig 中存储一个脚本,而只是存储了一个任意的字符串。
在比特币中,第一笔 coinbase 交易包含了如下信息:“The Times 03/Jan/2009 Chancellor on brink of second bailout for banks”。可点击这里查看.
subsidy 是奖励的数额。在比特币中,实际并没有存储这个数字,而是基于区块总数进行计算而得:区块总数除以 210000 就是 subsidy。挖出创世块的奖励是 50 BTC,每挖出 210000 个块后,奖励减半。在我们的实现中,这个奖励值将会是一个常量(至少目前是)。
将交易保存到区块链
从现在开始,每个块必须存储至少一笔交易。如果没有交易,也就不可能挖出新的块。这意味着我们应该移除 Block 的 Data 字段,取而代之的是存储交易:
struct block {
time_t timeStamp;
//string data;
vector<struct transaction*> transactions;
string prevBlockHash;
string hash;
int64_t nonce;
};
NewBlock 和 NewGenesisBlock 也必须做出相应改变:
struct block* NewBlock(vector<struct transaction*> transactions, string prevBlockHash) {
struct block* block = new Block{ time(NULL),transactions,prevBlockHash,"", };
ProofOfWork* pow = NewProofOfWork(block);
string hash = "";
int64_t nonce = Run(hash, pow);
if (pow != NULL) {
delete pow;
pow = NULL;
}
block->hash = hash;
block->nonce = nonce;
return block;
}
struct block* NewGenesisBlock(struct transaction* coinbase) {
vector<struct transaction*> vec;
vec.push_back(coinbase);
return NewBlock(vec,"");
}
接下来修改创建新链的函数:
struct blockchain* CreateBlockchain(string address) {
string tip;
const string genesisCoinbaseData = "The Times 03/Jan/2009 Chancellor on brink of second bailout for banks";
struct transaction* cbtx = NewCoinbaseTX(address, genesisCoinbaseData);
struct block* genesis = NewGenesisBlock(cbtx);
g_db[genesis->hash] = genesis;
g_db["l"] = genesis;
tip = genesis->hash;
struct blockchain* bc = new Blockchain{ tip, &g_db };
return bc;
}
现在,这个函数会接受一个地址作为参数,这个地址会用来接收挖出创世块的奖励。
工作量证明
工作量证明算法必须要将存储在区块里面的交易考虑进去,以此保证区块链交易存储的一致性和可靠性。所以,我们必须修改 ProofOfWork.prepareData 方法:
string prepareData(int64_t nonce, ProofOfWork* pow) {
stringstream ss;
ss << pow->block->prevBlockHash << HashTransactions(pow->block) << pow->block->timeStamp << nonce;
return ss.str();
}
不像之前使用 pow.block.Data,现在我们使用 pow.block.HashTransactions() :
string HashTransactions(struct block* b) {
vector<string> txHashes;
for (int i = ; i < b->transactions.size(); i++) {
txHashes.push_back(b->transactions[i]->id);
}
stringstream ss;
for (int i = ; i < txHashes.size(); i++) {
ss << txHashes[i];
}
string hash = sha256(ss.str());
return hash;
}
我们使用哈希提供数据的唯一表示,这个之前也遇到过。我们想要通过仅仅一个哈希,就可以识别一个块里面的所有交易。为此,我们获得每笔交易的哈希,将它们关联起来,然后获得一个连接后的组合哈希。
比特币使用了一个更加复杂的技术:它将一个块里面包含的所有交易表示为一个 Merkle tree ,然后在工作量证明系统中使用树的根哈希(root hash)。这个方法能够让我们快速检索一个块里面是否包含了某笔交易,即只需 root hash 而无需下载所有交易即可完成判断。
来检查一下到目前为止是否正确:
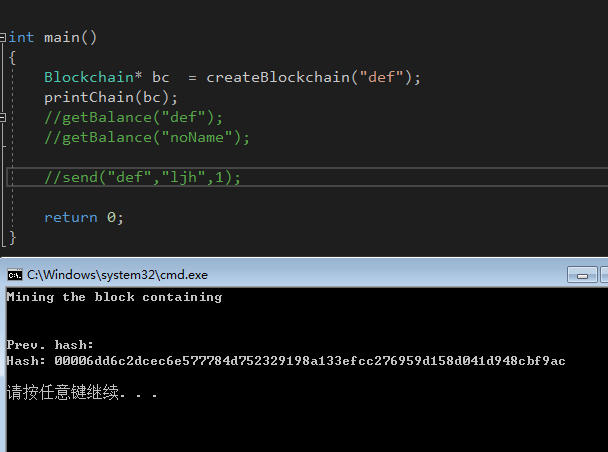
很好!我们已经获得了第一笔挖矿奖励,但是,我们要如何查看余额呢?
未花费的交易输出
我们需要找到所有的未花费交易输出(unspent transactions outputs, UTXO)。未花费(unspent) 指的是这个输出还没有被包含在任何交易的输入中,或者说没有被任何输入引用。在上面的图示中,未花费的输出是:
- tx0, output 1;
- tx1, output 0;
- tx3, output 0;
- tx4, output 0.
当然了,当我们检查余额时,我们并不需要知道整个区块链上所有的 UTXO,只需要关注那些我们能够解锁的那些 UTXO(目前我们还没有实现密钥,所以我们将会使用用户定义的地址来代替)。首先,让我们定义在输入和输出上的锁定和解锁方法:
bool CanUnlockOutputWith(string unlockingData, TXInput* in) {
return in->scriptSig == unlockingData;
}
bool CanBeUnlockedWith(string unlockingData, TXOutput* out) {
return out->scriptPubKey == unlockingData;
}
在这里,我们只是将 script 字段与 unlockingData 进行了比较。在后续文章我们基于私钥实现了地址以后,会对这部分进行改进。
下一步,找到包含未花费输出的交易,这一步相当困难:
vector<struct transaction> FindUnspentTransactions(string address, struct blockchain* bc) {
vector<struct transaction> unspentTXs;
map<string, vector<int>> spentTXOs;
struct blockchainiterator* bci = Iterator(bc);
while () {
struct block* block = Next(bci);
for (int i = ; i < block->transactions.size(); i++) {
string txID = block->transactions[i]->id;
for (int j = ; j < block->transactions[i]->vout.size(); j++) {
if (spentTXOs[txID].size() != ) {
for (int k = ; k < spentTXOs[txID].size(); k++) {
if (spentTXOs[txID][k] == j) {
goto CONFLAG;
}
}//for (int k = 0; k < spentTXOs[txID].size(); k++) {
}//if (spentTXOs[txID].size() != 0) {
if ( CanBeUnlockedWith(address, &(block->transactions[i]->vout[j])) ) {
unspentTXs.push_back(*(block->transactions[i]));
}
CONFLAG:
int tmp = ;
}//for (int j = 0; j < block->transactions[i]->vout.size(); i++) {
if (false == IsCoinbase(*(block->transactions[i])) ) {
for (int k = ; k < block->transactions[i]->vin.size(); k++) {
if (CanUnlockOutputWith(address, &(block->transactions[i]->vin[k]))) {
string inTxID = block->transactions[i]->vin[k].txid;
spentTXOs[inTxID].push_back(block->transactions[i]->vin[k].vout);
}
}
}
}//for (int i = 0; i < block->transactions.size(); i++) {
if (block->prevBlockHash == "")
break;
}
return unspentTXs;
}
由于交易被存储在区块里,所以我们不得不检查区块链里的每一笔交易。从输出开始:
if ( CanBeUnlockedWith(address, &(block->transactions[i]->vout[j])) ) {
unspentTXs.push_back(*(block->transactions[i]));
}
如果一个输出被一个地址锁定,并且这个地址恰好是我们要找的未花费交易输出的地址,那么这个输出就是我们想要的。不过在获取它之前,我们需要检查该输出是否已经被包含在一个输入中,也就是检查它是否已经被花费了:
if (spentTXOs[txID].size() != ) {
for (int k = ; k < spentTXOs[txID].size(); k++) {
if (spentTXOs[txID][k] == j) {
goto CONFLAG;
}
}//for (int k = 0; k < spentTXOs[txID].size(); k++) {
}//if (spentTXOs[txID].size() != 0) {
我们跳过那些已经被包含在其他输入中的输出(被包含在输入中,也就是说明这个输出已经被花费,无法再用了)。检查完输出以后,我们将所有能够解锁给定地址锁定的输出的输入聚集起来(这并不适用于 coinbase 交易,因为它们不解锁输出):
if (false == IsCoinbase(*(block->transactions[i])) ) {
for (int k = ; k < block->transactions[i]->vin.size(); k++) {
if (CanUnlockOutputWith(address, &(block->transactions[i]->vin[k]))) {
string inTxID = block->transactions[i]->vin[k].txid;
spentTXOs[inTxID].push_back(block->transactions[i]->vin[k].vout);
}
}
}
这个函数返回了一个交易列表,里面包含了未花费输出。为了计算余额,我们还需要一个函数将这些交易作为输入,然后仅返回一个输出:
vector<TXOutput> FindUTXO(string address, struct blockchain* bc) {
vector<TXOutput> UTXOs;
vector<struct transaction> unspentTransactions = FindUnspentTransactions(address, bc);
for (auto& tx : unspentTransactions) {
for (auto& out : tx.vout) {
if (CanBeUnlockedWith(address, &out)) {
UTXOs.push_back(out);
}
}
}
return UTXOs;
}
就是这么多了!现在我们来实现 getbalance 命令:
void getBalance(string address) {
Blockchain* bc = NewBlockchain(address);
int balance = ;
vector<txoutput> UTXOs = FindUTXO(address, bc);
for (auto& out : UTXOs) {
balance += out.value;
}
std::cout << "Balance of " << address << " : " << balance << std::endl;
}
账户余额就是由账户地址锁定的所有未花费交易输出的总和。
在挖出创世块以后,来检查一下我们的余额:
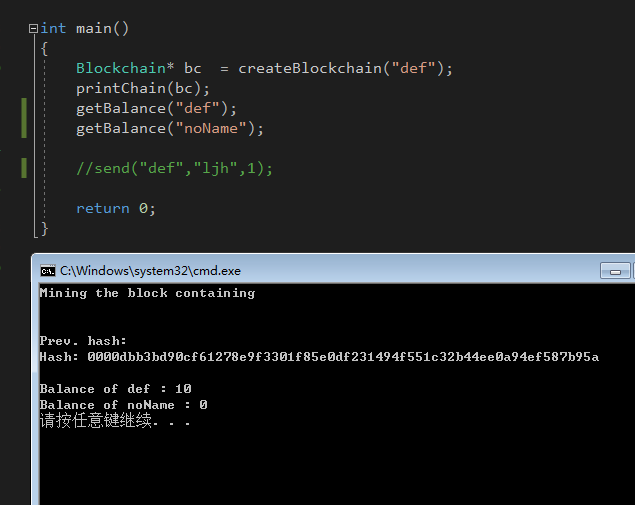
这就是我们的第一笔钱!
发送币
现在,我们想要给其他人发送一些币。为此,我们需要创建一笔新的交易,将它放到一个块里,然后挖出这个块。之前我们只实现了 coinbase 交易(这是一种特殊的交易),现在我们需要一种通用的交易:
Transaction* NewUTXOTransaction(string from, string to, int amount, Blockchain* bc) {
vector<TXInput> inputs;
vector<TXOutput> outputs;
map<string, vector<int>> validOutputs;
int acc = FindSpendableOutputs(from,amount,bc, validOutputs);
if (acc < amount){
std::cerr << "ERROR: Not enough funds" << std::endl;
return NULL;
}
map<string, vector<int>>::iterator it = validOutputs.begin();
for (; it != validOutputs.end(); it++) {
for (auto& out : it->second) {
TXInput input = TXInput{ it->first,out,from };
inputs.push_back(input);
}
}
TXOutput output = TXOutput{ amount, to };
outputs.push_back(output);
if (acc > amount){
TXOutput newout = TXOutput{ acc - amount, from };
outputs.push_back(newout);
}
Transaction* tx = new Transaction{ "", inputs, outputs };
SetID(tx);
return tx;
}
在创建新的输出前,我们首先必须找到所有的未花费输出,并且确保它们存储了足够的值(value),这就是 FindSpendableOutputs 方法做的事情。随后,对于每个找到的输出,会创建一个引用该输出的输入。接下来,我们创建两个输出:
一个由接收者地址锁定。这是给实际给其他地址转移的币。
一个由发送者地址锁定。这是一个找零。只有当未花费输出超过新交易所需时产生。记住:输出是不可再分的。
FindSpendableOutputs 方法基于之前定义的 FindUnspentTransactions 方法:
int FindSpendableOutputs(string address, int amount, struct blockchain* bc, map<string, vector<int>>& unspentOutputs) {
unspentOutputs.clear();
vector<struct transaction> unspentTXs = FindUnspentTransactions(address, bc);
int accumulated = ;
for (auto& tx : unspentTXs) {
string txID = tx.id;
for (int outIdx = ; outIdx < tx.vout.size(); outIdx++) {
if (CanBeUnlockedWith(address, &tx.vout[outIdx]) && accumulated < amount) {
accumulated += tx.vout[outIdx].value;
unspentOutputs[txID].push_back(outIdx);
if (accumulated >= amount){
break;
}
}
}
}
return accumulated;
}
这个方法对所有的未花费交易进行迭代,并对它的值进行累加。当累加值大于或等于我们想要传送的值时,它就会停止并返回累加值,同时返回的还有通过交易 ID 进行分组的输出索引。我们并不想要取出超出需要花费的钱。
现在,我们可以修改 Blockchain.MineBlock 方法:
void MineBlock(vector<struct transaction*> transactions, struct blockchain* bc) {
string lastHash;
struct block* p = g_db["l"];
if (p == NULL)
return;
lastHash = p->hash;
struct block* newBlock = NewBlock(transactions, lastHash);
(*(bc->db))[newBlock->hash] = newBlock;
(*(bc->db))["l"] = newBlock;
bc->tip = newBlock->hash;
}
最后,让我们来实现 send 方法:
void send(string from,string to,int amount) {
Blockchain* bc = NewBlockchain(from);
Transaction* tx = NewUTXOTransaction(from, to, amount, bc);
vector<Transaction*> tmp;
tmp.push_back(tx);
MineBlock(tmp, bc);
printChain(bc);
getBalance(from);
getBalance(to);
std::cout << "sucess!!" << std::endl;
}
发送币意味着创建新的交易,并通过挖出新块的方式将交易打包到区块链中。不过,比特币并不是一连串立刻完成这些事情(不过我们的实现是这么做的)。相反,它会将所有新的交易放到一个内存池中(mempool),然后当一个矿工准备挖出一个新块时,它就从内存池中取出所有的交易,创建一个候选块。只有当包含这些交易的块被挖出来,并添加到区块链以后,里面的交易才开始确认。
让我们来检查一下发送币是否能工作(正确与错误情况):
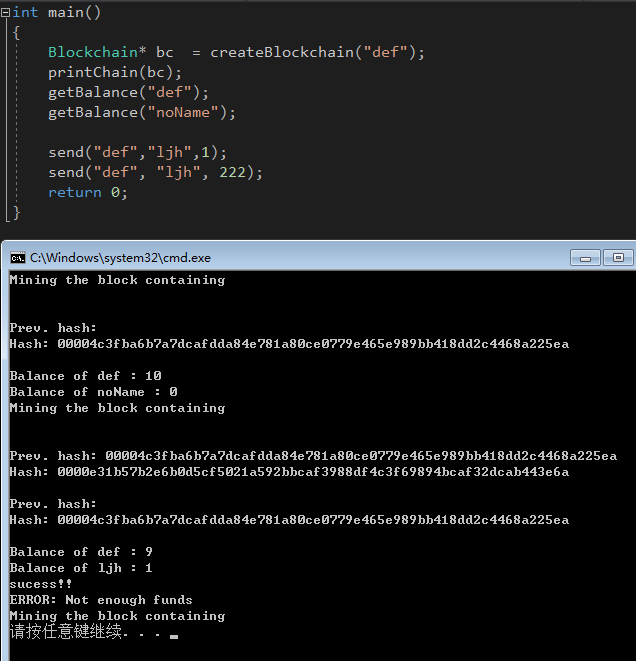
总结
虽然不容易,但是现在终于实现交易了!不过,我们依然缺少了一些像比特币那样的一些关键特性:
地址(address)。我们还没有基于私钥(private key)的真实地址。
奖励(reward)。现在挖矿是肯定无法盈利的!
UTXO 集。获取余额需要扫描整个区块链,而当区块非常多的时候,这么做就会花费很长时间。并且,如果我们想要验证后续交易,也需要花费很长时间。而 UTXO 集就是为了解决这些问题,加快交易相关的操作。
内存池(mempool)。在交易被打包到块之前,这些交易被存储在内存池里面。在我们目前的实现中,一个块仅仅包含一笔交易,这是相当低效的。
工程代码见群下载 文件名为part4.zip
参考博文:
https://blog.csdn.net/simple_the_best/article/details/78236282
https://jeiwan.cc/posts/building-blockchain-in-go-part-4/
cpp 区块链模拟示例(六) 交易的更多相关文章
- cpp 区块链模拟示例(一)工程建立
/* 作 者: itdef 欢迎转帖 请保持文本完整并注明出处 技术博客 http://www.cnblogs.com/itdef/ 技术交流群 群号码:432336863欢迎c c++ window ...
- cpp 区块链模拟示例(四) 区块链工作量证明
本文主要在之前的区块链原形上添加了工作量证明,并且为后继的交易功能做好准备. 上一个章节我们已经创建了区块链的基本原形,但是区块的哈希计算和加入太过于简单,如果按照这种速度添加区块那么区块链估计一个小 ...
- cpp 区块链模拟示例(二)工程代码解析
/* 作 者: itdef 欢迎转帖 请保持文本完整并注明出处 技术博客 http://www.cnblogs.com/itdef/ 技术交流群 群号码:432336863欢迎c c++ window ...
- cpp 区块链模拟示例(三)新基本原形工程的建立
/* 作 者: itdef 欢迎转帖 请保持文本完整并注明出处 技术博客 http://www.cnblogs.com/itdef/ 技术交流群 群号码:432336863欢迎c c++ window ...
- cpp 区块链模拟示例(五) 序列化
有了区块和区块链的基本结构,有了工作量证明,我们已经可以开始挖矿了.剩下就是最核心的功能-交易,但是在开始实现交易这一重大功能之前,我们还要预先做一些铺垫,比如数据的序列化和启动命令解析. 根据< ...
- cpp 区块链模拟示例(七) 补充 Merkle树
Merkle 树 完整的比特币数据库(也就是区块链)需要超过 140 Gb 的磁盘空间.因为比特币的去中心化特性,网络中的每个节点必须是独立,自给自足的,也就是每个节点必须存储一个区块链的完整副本.随 ...
- 区块链开发(六)truffle使用入门和testrpc安装
在上篇博文中我们已经成功安装了truffle及所需相关环境,此篇就简单介绍一些truffle的使用及目录结构等. 简介truffle和testrpc truffle是本地的用来编译.部署智能合约的工具 ...
- 通过blockchain_go分析区块链交易原理
原文链接-石匠的Blog 1.背景 在去中心化的区块链中进行交易(转账)是怎么实现的呢?本篇通过blockchain_go来分析一下.需要进行交易,首先就需要有交易的双方以及他们的认证机制,其次是各自 ...
- 从Go语言编码角度解释实现简易区块链——实现交易
在公链基础上实现区块链交易 区块链的目的,是能够安全可靠的存储交易,比如我们常见的比特币的交易,这里我们会以比特币为例实现区块链上的通用交易.上一节用简单的数据结构完成了区块链的公链,本节在此基础上对 ...
随机推荐
- SpringBoot Web开发(3) WebMvcConfigurerAdapter过期替代方案
springboot2.0中 WebMvcConfigurerAdapter过期替代方案 最近在学习尚硅谷的<springboot核心技术篇>,项目中用到SpringMVC的自动配置和扩展 ...
- 【spring】之xml和Annotation,Bean注入的方式
基于xml形式Bean注入 @Data @AllArgsConstructor @NoArgsConstructor public class PersonBean { private Integer ...
- [转][C#]加密解密类
{ public static class Crypter { private static string FDefaultPassword = typeof(Crypter).FullName; p ...
- 20165312 2017-2018-2 《JAVA程序设计》第4周学习总结
一.课本五六章知识点总结 1.第五章 继承是一种由已有的类创建新类的机制 子类继承父类的成员变量和方法 子类继承的方法只能操作子类继承和隐藏的成员变量 子类重写或新增的方法只能操作子类继承和新声明的成 ...
- Zabbix监控进程(进程消失后钉钉报警)
用于python报警的脚本如下:(钉钉机器人的连接需要修改) #!/usr/bin/python3# -*- coding: utf-8 -*-# Author: aiker@gdedu.ml# My ...
- Runtime 解读
首先,第一个问题, 1>runtime实现的机制是什么,怎么用,一般用于干嘛? 这个问题我就不跟大家绕弯子了,直接告诉大家, runtime是一套比较底层的纯C语言API, 属于1个C语言库, ...
- std::set
std::set 不重复key 默认less排序 代码 #include <iostream> #include <set> class Person { public: ...
- Java虚拟机------JVM内存区域
JVM内存区域运行时数据区域分为两种: JVM内存区域 运行时数据区域分为两种: 线程隔离的数据区: 程序计数器 Java虚拟机栈 本地方法栈 所有线程程共享的数据区: Java堆 方法区 JVM 内 ...
- mysql相关碎碎念
取得当天: SELECT curdate(); mysql> SELECT curdate();+------------+| curdate() |+------------+| 2013- ...
- Python中字符串/字典/json之间的转换
import json #定义一个字典d1,字典是无序的 d1 = { "a": None, "b": False, "c": True, ...