Hadoop基础-HDFS的读取与写入过程剖析
Hadoop基础-HDFS的读取与写入过程剖析
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
本篇博客会简要介绍hadoop的写入过程,并不会设计到源码,我会用图和文字来描述hdfs的写入过程。
一.hdfs写数据流程
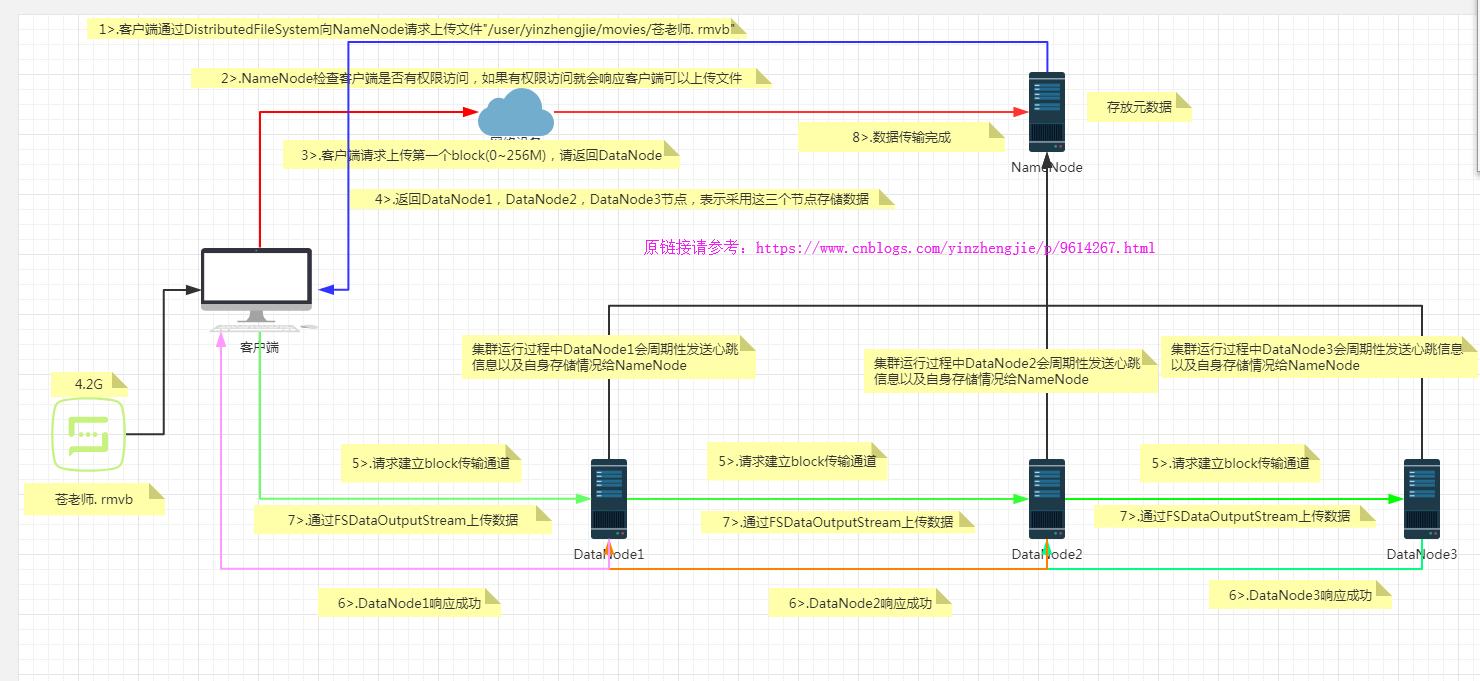
如上图所示,想要把一个4.2G的文件写入到hdfs集群中,它是怎么实现的呢?其步骤简要如下:
1>.客户端向NameNode请求在"/user/yinzhengjie/movies/"目录下上传一个名称叫“苍老师.rmvb”的视频;
2>.NameNode检查客户端是否有权限上传,如果有返回客户端可以上传,否则返回权限被拒绝。
3>.客户端请求第一个block上传到哪几个DataNode服务器上;
4>.NameNode返回3个DataNode节点,分别为DataNode1,DataNode2,DataNode3(如上图所示);
5>.客户端请求DataNode1上传数据,DataNode1收到请求会继续调用DataNode2,然后DataNode2再调用DataNode3,将这个同学管道简历完成;
6>.DataNode1,DataNode2,DataNode3逐级应答客户端
7>.客户端开始往DataNode1上传第一个block(先从磁盘读取数据存放到一个本地内存缓冲区),以package为单位,DataNode1收到一个package就会传给DataNode2,DataNode2传给DataNode3;DataNode1每传一个packet会放入一个应答队列等待应答;
8>.当一个block传输完成后,客户端再次请求NameNode上传第二个block的服务器。(重复执行3~7步)
HDFS Client:
DistributedFileSystem:分布式文件系统,负责链接NameNode
FSDataOutputStream:数据输出流,负责数据的存储和输出 NameNode:
存放元数据 DataNode:
存储数据 一致性模型:
hdfs默认的写入方式是:客户端开始往DataNode1上传第一个block(先从磁盘读取数据存放到一个本地内存缓冲区),
以package为单位,DataNode1收到一个package就会传给DataNode2,DataNode2传给DataNode3;DataNode1每传一个
packet会放入一个应答队列等待应答。
据说所述,默认的写入方式可靠性很强,但是也意味着会消耗着大量的传输时间,浪费了大量的时间。如果客户端开始往
DataNode1上传第一个block成功后,DataNode1立即写入数据到磁盘并告诉NameNode写入完毕,接下来就上传第二个block,
与此同时,DataNode1会将client传来的数据同步到其它两个节点中。
想要使用一致性模型,我们在写入的时候只要调用输出流的“hflush()”一致性刷新方法即可。
二.hdfs读数据流程
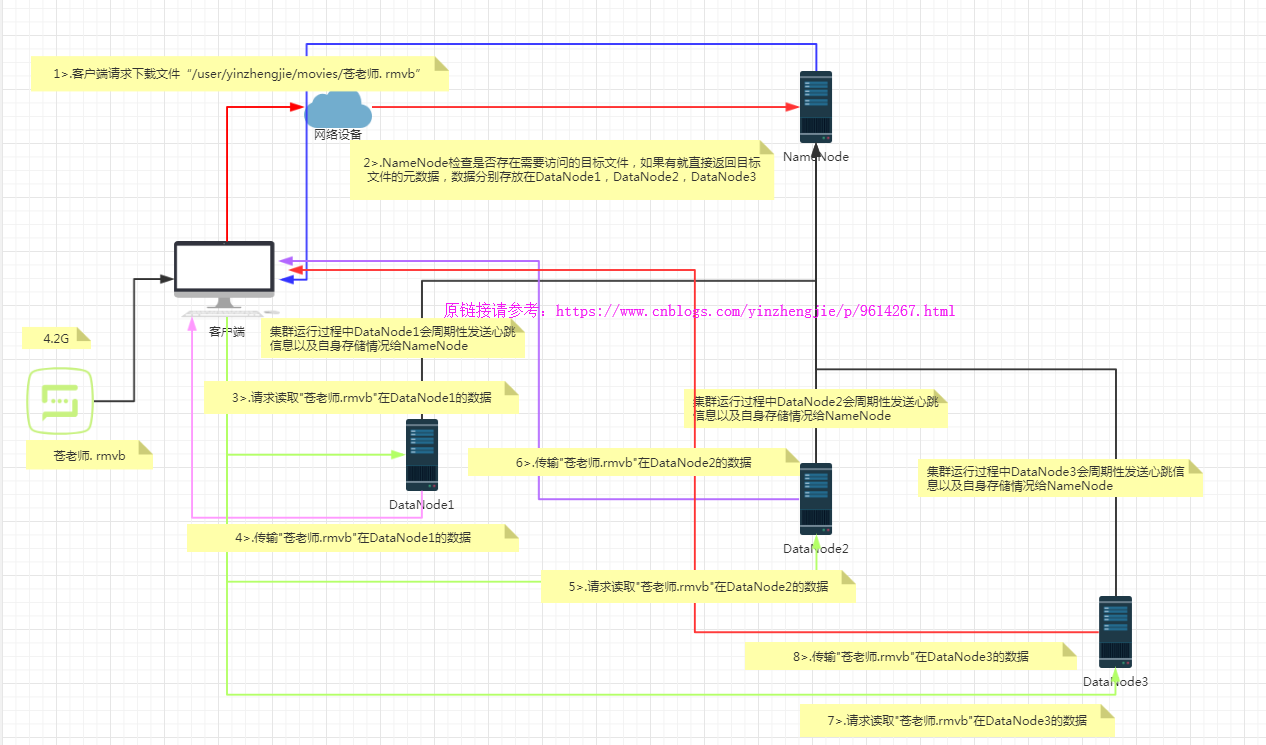
如上图所示,想要把一个4.2G的文件从hdfs集群中读取,它是怎么实现的呢?其步骤简要如下:
1>.客户端向NameNode请求下载"/user/yinzhengjie/movies/苍老师.rmvb"的文件;
2>.NameNode通过查询元数据,如果找到文件块所在的DataNode地址列表就返回给客户端,如果没有找到元数据信息就返回客户端访问的资源不存在;
3>.客户端拿到NameNode的数据之后,挑选一台DataNode服务器(就近原则,然后随机)请求读取数据;
4>.DataNode开始传输数据给客户端(从磁盘里面读取数据放入流,以package为单位来做实验);
5>.客户端以package为单位接收,现在本地缓存,然后写入目标文件;
一. Hadoop中需要哪些配置文件,其作用是什么?
>core-site.xml:
()fs.defaultFS:hdfs://cluster1(域名),这里的值指的是默认的HDFS路径 。
()hadoop.tmp.dir:/export/data/hadoop_tmp,这里的路径默认是NameNode、DataNode、secondaryNamenode等存放数据的公共目录。用户也可以自己单独指定这三类节点的目录。
()ha.zookeeper.quorum:hadoop101:,hadoop102:,hadoop103:,这里是ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点 。
>.hadoop-env.sh: 只需设置jdk的安装路径,如:export JAVA_HOME=/usr/local/jdk。
>.hdfs-site.xml:
()dfs.replication:他决定着系统里面的文件块的数据备份个数,默认为3个。
()dfs.data.dir:datanode节点存储在文件系统的目录 。
()dfs.name.dir:是namenode节点存储hadoop文件系统信息的本地系统路径 。
>.mapred-site.xml:
mapreduce.framework.name: yarn指定mr运行在yarn上。 二.请列出正常工作的Hadoop集群中Hadoop都分别需要启动哪些进程,它们的作用分别是什么?
>.NameNode它是hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问,保存有metadate。
>.SecondaryNameNode它不是namenode的冗余守护进程,而是提供周期检查点和清理任务。帮助NN合并editslog,减少NN启动时间。
>.DataNode它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个datanode守护进程。
>.ResourceManager(JobTracker)JobTracker负责调度DataNode上的工作。每个DataNode有一个TaskTracker,它们执行实际工作。
>.NodeManager(TaskTracker)执行任务。
>.DFSZKFailoverController高可用时它负责监控NN的状态,并及时的把状态信息写入ZK。它通过一个独立线程周期性的调用NN上的一个特定接口来获取NN的健康状态。FC也有选择谁作为Active NN的权利,因为最多只有两个节点,目前选择策略还比较简单(先到先得,轮换)。
>.JournalNode 高可用情况下存放namenode的editlog文件。 三.简述Hadoop的几个默认端口及其含义
>.dfs.namenode.http-address:
>.SecondaryNameNode辅助名称节点端口号:
>.dfs.datanode.address:
>.fs.defaultFS: 或者9000
>.yarn.resourcemanager.webapp.address:
Hadoop基础-HDFS的读取与写入过程剖析的更多相关文章
- Hadoop基础-HDFS的读取与写入过程
Hadoop基础-HDFS的读取与写入过程 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 为了了解客户端及与之交互的HDFS,NameNode和DataNode之间的数据流是什么样 ...
- Hadoop基础-HDFS数据清理过程之校验过程代码分析
Hadoop基础-HDFS数据清理过程之校验过程代码分析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想称为一名高级大数据开发工程师,不但需要了解hadoop内部的运行机制,还需 ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hadoop基础-HDFS的API实现增删改查
Hadoop基础-HDFS的API实现增删改查 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客开发IDE使用的是Idea,如果没有安装Idea软件的可以去下载安装,如何安装 ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法
Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. fs.listFiles方法,返回Loc ...
- Hadoop基础-HDFS安全管家之Kerberos实战篇
Hadoop基础-HDFS安全管家之Kerberos实战篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们都知道hadoop有很多不同的发行版,比如:Apache Hadoop ...
- Hadoop基础-HDFS集群中大数据开发常用的命令总结
Hadoop基础-HDFS集群中大数据开发常用的命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本盘博客仅仅列出了我们在实际生成环境中常用的hdfs命令,如果想要了解更多, ...
- Hadoop基础-HDFS的API常见操作
Hadoop基础-HDFS的API常见操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习HDFS时的一些琐碎的学习笔记, 方便自己以后查看.在调用API ...
随机推荐
- github作业
链接: https://github.com/liuyu13/liuyu13-1 总结:git可以学习的东西还有很多.git协议,分布式协作,git项目管理,git技巧,github的使用和实践, ...
- 分布式版本控制系统Git的安装与使用 第二次作业
(本次作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2103) 一.安装Git bash软件和安装notepad++ 二 ...
- [转帖]新的Linux后门开始肆虐 主要攻击中国服务器
新的Linux后门开始肆虐 主要攻击中国服务器 https://www.cnbeta.com/articles/tech/815639.htm 一种新的 Linux 系统后门已经开始肆虐,并主要运行在 ...
- PHP常用工具类积累
第一 请求第三方接口的工具类 例如,封装了get和post请求方法的工具类,代码如下: <?php class HttpClient{ /** * HttpClient * @param arr ...
- Maven概述(一)
Maven是什么? Apache Maven is a software project management and comprehension tool. Based on the concept ...
- BZOJ5311 贞鱼(动态规划+wqs二分+决策单调性)
大胆猜想答案随k变化是凸函数,且有决策单调性即可.去粘了份fread快读板子才过. #include<iostream> #include<cstdio> #include&l ...
- Application Server not specified
IDEA使用tomcat启动web项目,配置页面报错Application Server not specified: 那是因为没有配置tomcat,只要配置一下就好了:
- MT【39】构造二次函数证明
这种构造二次函数的方法最早接触的应该是在证明柯西不等式时: 再举一例: 最后再举个反向不等式的例子: 评:此类题目的证明是如何想到的呢?他们都有一个明显的特征$AB\ge(\le)C^2$,此时构造二 ...
- 自学Linux Shell12.5-while、until命令
点击返回 自学Linux命令行与Shell脚本之路 12.5-while.until命令 until 循环与 while 循环在处理方式上刚好相反. while循环用于不断执行一系列命令,也用于从输入 ...
- 自学Zabbix9.1 Network Discovery 网络发现原理
点击返回:自学Zabbix之路 点击返回:自学Zabbix4.0之路 点击返回:自学zabbix集锦 自学Zabbix9.1 Network Discovery 网络发现原理 1. 网络发现简介 网络 ...