python基础 (编码进阶,文件操作和深浅copy)
1.编码的进阶
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码。
即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。 decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
因此,转码的时候一定要先搞明白,字符串str是什么编码,然后decode成unicode,然后再encode成其他编码 other:
1.在网络传输过程中,不能使用Unicode编码去编译数据,但是str又是unicode编码的,只能在传输或者存储过程中将unicode装转化成非unicode,所以需要(3)
2.windows: 编码:gbk.
linux,mac: 编码是utf-8.
3.bytes数据类型,与str几乎一模一样.(二进制的形式)
2.文件操作(文件光标是重点,可能会有坑)
文件可以从多个维度进行管理:文件重命名,获取文件属性,判断文件是否存在,备份文件,读写文件,打包解压等等。
在python读取文件只需要通过内置函数open来打开文件即可,open函数接受文件名称和打开模式作为参数,返回一个文件对象,操作完文件之后,通过文件对象的close方法关闭即可
info = open('',encoding='utf-8',mode='r') #要加上编码方式,读取到info文件对象里面
print(info.read()) #通过info文件对象的read方法读取文件的所有内容,并打印
info.close() #关闭这个文件对象
open函数默认以"r"的方式打开,也可以知道那个文件的打开模式
r:默认以读的方式打开,如果文件不存在,抛出FileFoundError异常
w:以写模式打开,如果文件非空,则已有的内容将会被覆盖,如果文件不存在,将创建文件并写入
a:在文件末尾追加数据的方式写入,没有文件则创建文件写入
x:创建一个新文件,如果文件存在,则抛出FileExisError异常
r+:可读写文件。可读;可写;可追加 ,先读后写
w+:写读
U:表示在读取时,可以将\r\n自动转换成 \n (与 r 或 r+ 模式同使用, rU或者r+U)
b:表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注,一般都是非文字的文件,按字节读取)
open函数的其他方法
info.close() #关闭文件
info.flush() #刷新缓冲区,将缓冲区的数据立即写入到文件
info.isatty() #判断文件是否连接到终端设备,返回bool值
info.read(10) #读取文件前10个字符,从文件中读取指定的字符数,默认读取全部,rb模式下是字节
info.readline(3)) #读取前3个字符,默认每次最多读取一行数据,每行的最后包含换行符'\n'
info.readlines() #将文件存入到列表中,列表中的么一行就是文件中的每一行
info.readable #判断文件是否可读,返回布尔值
info.seek(3) #移动文件读取的指针,如果文件中包含中文,移动指针必须是3的倍数,不然会报错,因为一个中文字符等于3个字节
seek(0,0) 文件开头 seek(0,1) 当前位置 seek(0,2) 文件最后
info.seekable #判断文件指针是否可用,返回布尔值
info.tell() #获取指针位置
info.truncate() #截断,把指针后面的内容删除,并写入文件,必须在可写模式下操作,读取的是字节
f = open('text.txt','r+',encoding='utf-8')
f.seek(9) #把指针移动到第9个字节后面(即第3个中文后面)
f.truncate() #把第3个中文后面所有的字符删除,并写入文件
f.close()
info.writable() #判断文件是否可写,返回布尔值
info.write() #把字符串写入文件,并返回字符数
info.writelines() #写一个字符串列表到文件 在计算机中,每打开一个文件就需要占用一个文件句柄,而一个进程拥有的文件句柄是有限的,并且文件句柄也会占用操作系统的资源,所以,在打开文件以后要及时关闭文件,避免文件句柄泄露
1.可以使用finally关闭文件句柄,并且在什么情况是都会关闭(但是不提倡,因为python提倡优美,简洁)
try:
info = open("test.txt",encoding='utf-8',mode='r')
peint(info)
finally:
info.close()
2.使用上下文管理器(会打开文件,然后自动关闭,不用close函数)
with open('data.txt',encoding='utf-8',mode='r') as info,open('data.txt',encoding='utf-8',mode='w')as info2:
print(info.read()) 如何读取大文件?(for循环过程中,每使用一行,便在内存生成一行,用完即回收地址)
使用上下文管理器和for循环,因为for循环不仅可以遍历如字符串,列表,元祖等可迭代序列,还可以使用可迭代协议来便利迭代对象,文件对象就实现了可迭代协议
with open('data',encoding='utf-8',mode=='r') as info:
for line in info:
print(line.upper()) 使用print语句也可以将数据写入到文件
with open ("","a+",encoding="utf-8") as info:
print(1,2,'hello,world',sep='\n',file=info) #通过追加读写方式打开文件,并把标准输出(file)写入到文件 文件的修改:(world,wps等大公司的文件修改都是如此)
#1,以读的模式打开原文件.
#2,以写的模式创建一个新文件.
import os
with open('abc.txt',encoding='utf-8') as f1,\
open('abc.txt.bak',encoding='utf-8',mode='w') as f2:
#3,将原文件内容读取出来,按照要求改成新内容,写入新文件.
for old_line in f1:
new_line = old_line.replace('kobe','god')
f2.write(new_line)
#4,删除原文件.
os.remove('abc')
#5,将新文件重命名成原文件.
os.rename('abc.txt.bak','abc.txt') 各种模式读写关系

3.深浅copy
深浅copy的主要区别在于是否包含可变或者不可变的数据类型 Python中,对象的赋值,拷贝(深/浅拷贝)之间是有差异的,如果使用的时候不注意,就可能产生意外的结果,其实这个是由于共享内存导致的结果 拷贝:原则上就是把数据分离出来,复制其数据,并以后修改互不影响。 1.首先先看一个赋值的情况:使用=进行赋值的时候,数据完全共享
=赋值是在内存中的同一个内存地址被分别贴上了不同的标签,
如果这个内存地址指向的数据是可变的类型元素,那么使用其中任意一个标签来修改这个数据,另外一个也会变化
如果这个内存地址指向的数据是不可变的类型,那么适用其中任意一个标签来修改这个数据,都会在内存中新创建一个数据,并且另一个不会变 2.浅拷贝:

如图,这就是浅拷贝的原理,其中l1和l2的id不同。l2拷贝l1的时候只拷贝了他的第一层,也就是在其他内存中指向了l1的第一层数据,但是l2无法拷贝l1的第二层数据,也就是列表中的列表,所以他就只能指向l1中的第二层数据 由此,当修改l1中第二层数据的时候,浅拷贝l1的l2中的第二层数据也随之发生改变,但是指向的第二层的内存地址还是一样 浅拷贝之后,如果改变了可变的数据类型之后,二者可变类型数据的id不会发生变化,如果改变了不可变数据类型的话,二者改变了的不可变的数据的id才不一样
3.深拷贝:
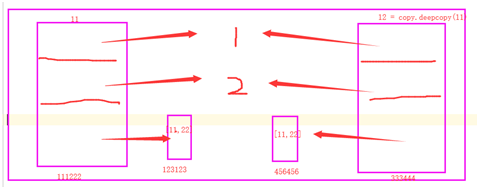
不论是同一个代码块,不同代码块下:不仅创建一个新外壳(列表),外壳里面的可变的数据类型也创建一份新的,但是不可变的数据类型共用一个. 1
2
3
4
import copy
l1 = [1, 2, 3, [11, 22, 33]]
# l2 = copy.copy(l1) 浅拷贝
l2 = copy.deepcopy(l1)
能进行深浅copy的数据类型 :dict list set
python基础 (编码进阶,文件操作和深浅copy)的更多相关文章
- python基础之 编码进阶,文件操作和深浅copy
1.编码的进阶 字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码.即先将其他编码的字符串解码(decode)成unicode,再从unic ...
- Python自动化 【第三篇】:Python基础-集合、文件操作、字符编码与转码、函数
1. 集合 1.1 特性 集合是一个无序的,不重复的数据组合,主要作用如下: 去重,把一个列表变成集合实现自动去重. set可以看成数学意义上的无序和无重复元素的集合,因此,两 ...
- python基础3之文件操作、字符编码解码、函数介绍
内容概要: 一.文件操作 二.字符编码解码 三.函数介绍 一.文件操作 文件操作流程: 打开文件,得到文件句柄并赋值给一个变量 通过句柄对文件进行操作 关闭文件 基本操作: #/usr/bin/env ...
- 第三章:Python基础の函数和文件操作实战
本課主題 Set 集合和操作实战 函数介紹和操作实战 参数的深入介绍和操作实战 format 函数操作实战 lambda 表达式介绍 文件操作函数介紹和操作实战 本周作业 Set 集合和操作实战 Se ...
- Python 字符编码及其文件操作
本章节内容导航: 1.字符编码:人识别的语言与机器机器识别的语言转化的媒介. 2.字符与字节:字符占多少个字节,字符串转化 3.文件操作:操作硬盘中的一块区域:读写操作 注:浅拷贝与深拷贝 用法: d ...
- Python基础7:文件操作
[ 文件操作] 1 对文件操作流程 打开文件,得到文件句柄并赋值给一个变量 通过句柄对文件进行操作 关闭文件 现有文件如下: 昨夜寒蛩不住鸣. 惊回千里梦,已三更. 起来独自绕阶行. 人悄悄,帘外月胧 ...
- python学习笔记-(七)python基础--集合、文件操作&函数
本节内容 1.集合操作 2.文件操作 3.字符编码与转码 4.函数操作 1.集合操作 集合是一个无序的.不重复的数据组合: 1.1 常用操作 它的作用是: 1)自动去重:列表变成集合,自动去重: &g ...
- Python基础-week03 集合 , 文件操作 和 函数详解
一.集合及其运算 1.集合的概念 集合是一个无序的,不重复的数据组合,它的主要作用如下 *去重,把一个列表变成集合,就自动去重了 *关系测试,测试两组数据之前的交集.并集.差集.子集.父级.对称差集, ...
- python基础学习笔记——文件操作
文件操作 初始文件操作 使用Python来读写文件是非常简单的操作,我们使用open()函数来打开一个文件,获取到文件句柄,然后通过文件句柄就可以进行各种各样的操作了 根据打开方式的不同能够执行的操作 ...
随机推荐
- Numpy、SciPy、MatPlotLib在Python2.7.9下的安装与配置
前言: Python安装完Numpy,SciPy和MatplotLib后,可以成为非常犀利的科研利器.网上关于这三个库的安装都写得非常不错,但是大部分人遇到的问题并不是如何安装,而是安装好后因为配置不 ...
- 【java】final修饰符介绍
final: 最终,作为一个修饰符特点:1.可以修饰类,函数,变量2.被final修的的类不能被继承.因此类用final修饰可以避免被继承,被子类重写功能.3.被final修饰的方法不可以被重写.4. ...
- 【java】static用法
static作用: 用来修饰函数成员,成员变量和成员函数.类对象的属性都一致且能共享,比如国籍,这就能用static修饰,name不能共享,因为每个人都有自己的名字. 特有内容(name)随着对象存储 ...
- shell脚本大小写转换
几个方法 1.tr命令 2.sed替换 3.awk的tolower() toupper() 4.perl语言 详见 http://blog.51cto.com/wangxiaoyu/197623 L ...
- 如何配置nginx负载均衡配置(轮询,权重,ip绑定)
集群是为了解决单节点无法服务高并发的情况,在集群中nginx是如何分配将来自客户端的请求 转发给服务器的 负载均衡可以提高网站的吞吐量(接受和响应),减轻单台服务器的压力 负载均衡提供了三种策略:轮询 ...
- Python-实列
"""题目:有四个数字:1.2.3.4,能组成多少个互不相同且无重复数字的三位数?各是多少? 程序分析:可填在百位.十位.个位的数字都是1.2.3.4.组成所有的排列后再 ...
- github 添加wiki
亲们支持我的新博客哦==>地址(以后更新会尽量在新博客更新,欢迎大家访问加入我的后宫w) ) 平时都是写readMe和docs的,一直眼瞎没有注意到有wiki这个功能 随便找一个写了wiki的看 ...
- npm下载安装文件太慢..修改这个就好了..治好多年的便秘..真香预警
修改 npm 的安装目录下的 npmrc文件 增加一条 registry=http://registry.cnpmjs.org 将原来的https改成下面的http $ npm config set ...
- Java double 加、减、乘、除
double类型的数值接相加的时候,结果可能出现精度误差为此Java提供了高精度计算的方法:java.math.*里面提供了BigDecimal类 import org.junit.Test; imp ...
- Jenkins部署报weblogic.deploy.api.tools.deployer.DeployerException: Java heap space
Jenkins部署报weblogic.deploy.api.tools.deployer.DeployerException: Java heap space异常 解决办法: 在MAVEN_OPTS中 ...