07、RDD持久化

|
持久化级别 |
|
|
MEMORY_ONLY |
以非序列化的Java对象的方式持久化在JVM内存中。如果内存无法完全存储RDD所有的partition,那么那些没有持久化的partition就会在下一次需要使用它的时候,重新被计算 |
|
MEMORY_AND_DISK |
同上,但是当某些partition无法存储在内存中时,会持久化到磁盘中。下次需要使用这些partition时,需要从磁盘上读取 |
|
MEMORY_ONLY_SER |
同MEMORY_ONLY,但是会使用Java序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大CPU开销 |
|
MEMORY_AND_DSK_SER |
同MEMORY_AND_DSK。但是使用序列化方式持久化Java对象 |
|
DISK_ONLY |
使用非序列化Java对象的方式持久化,完全存储到磁盘上 |
|
MEMORY_ONLY_2 MEMORY_AND_DISK_2 等等 |
如果是尾部加了2的持久化级别,表示会将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可 |
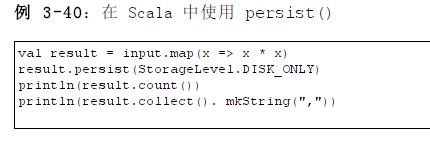
}
07、RDD持久化的更多相关文章
- Spark RDD概念学习系列之rdd持久化、广播、累加器(十八)
1.rdd持久化 2.广播 3.累加器 1.rdd持久化 通过spark-shell,可以快速的验证我们的想法和操作! 启动hdfs集群 spark@SparkSingleNode:/usr/loca ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- 【Spark调优】:RDD持久化策略
[场景] Spark对RDD执行一系列算子操作时,都会重新从头到尾计算一遍.如果中间结果RDD后续需要被被调用多次,可以显式调用 cache()和 persist(),以告知 Spark,临时保存之前 ...
- spark rdd持久化的简单对比
未使用rdd持久化 使用后 通过对比可以发现,未使用RDD持久化时,第一次计算比使用RDD持久化要快,但之后的计算显然要慢的多,差不多10倍的样子 代码 public class PersistRDD ...
- 8、RDD持久化
一.RDD持久化 1.不使用RDD持久化的问题 2.RDD持久化原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的par ...
- Spark练习之创建RDD(集合、本地文件),RDD持久化及RDD持久化策略
Spark练习之创建RDD(集合.本地文件) 一.创建RDD 二.并行化集合创建RDD 2.1 Java并行创建RDD--计算1-10的累加和 2.2 Scala并行创建RDD--计算1-10的累加和 ...
- 五、RDD持久化
Spark最重要的一个功能是它可以通过各种操作(operations)持久化(或者缓存)一个集合到内存中.当你持久化一个RDD的时候,每一个节点都将参与计算的所有分区数据存储到内存中,并且这些数据可以 ...
- spark复习笔记(6):RDD持久化
在spark中最重要的功能之一是跨操作在内存中持久化数据集.当你持久化一个RDD的时候,每个节点都存放了一个它在内存中计算的一个分区,并在该数据集的其他操作中进行重用,持久化一个RDD的时候,节点上的 ...
- Spark性能调优篇二之重构RDD架构及RDD持久化
如果一个RDD在两个地方用到,就持久化他.不然第二次用到他时,会再次计算. 直接调用cache()或者presist()方法对指定的RDD进行缓存(持久化)操作,同时在方法中指定缓存的策略. 原文:h ...
随机推荐
- train_test_split数据切分
train_test_split 数据切分 格式: X_train,X_test, y_train, y_test =cross_validation.train_test_split(train_d ...
- 实践出真知-所谓"java没有指针",那叫做引用!
java没有指针,那我们如何实现动态数组呢? 上篇评论提及 ”不仅有vector,还有ArrayList,还有List,可做选择“. "java没有指针",那叫做引用! 今天尝试了 ...
- 反向传播算法(前向传播、反向传播、链式求导、引入delta)
参考链接: 一文搞懂反向传播算法
- mybatis的xml处理大于和小于号问题
https://blog.csdn.net/u022812849/article/details/42123007
- git合并
git 里合并了两个分支以后,是不是两个分支的内容就完全一样了? 不是.看合并到哪个分支,这个分支有两个分支所有的内容.另外一个分支不变. 合并操作( merge )对当前所在分支产生影响. 合并分支 ...
- P1967 货车运输
P1967 货车运输最大生成树+lca+并查集 #include<iostream> #include<cstdio> #include<queue> #inclu ...
- CSRF自动化检测
CSRF自动化检测: 这里主要是对POST型form表单的检测 1. 根据URL获取form表单组成的数组 2. 遍历表单数组,对比不设置cookie与设置了cookie两种情况下的表单是否还存在,如 ...
- Dijkstra算法之 Java详解
转载:http://www.cnblogs.com/skywang12345/ 迪杰斯特拉算法介绍 迪杰斯特拉(Dijkstra)算法是典型最短路径算法,用于计算一个节点到其他节点的最短路径. 它的主 ...
- python数据结构之插入排序
插入排序(英语:Insertion Sort)是一种简单直观的排序算法.它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入.插入排序在实现上,在从后向前扫描 ...
- 声明式调用---Feign
Feign:Feign是一种声明式.模板化的HTTP客户端. 用我的理解来说,Feign的功能类似dubbo暴露服务,但是与dubbo稍有不同的是Feign是HTTP REST接口的形式暴露的. 这一 ...