决策树及R语言实现
决策树是什么
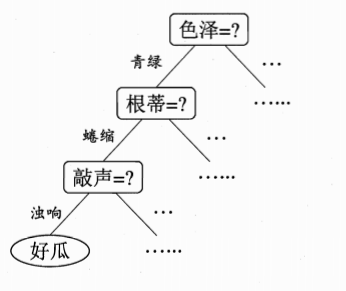
决策树是基于树结构来进行决策,这恰是人类在面临决策问题时一种很自然的处理机制。例如,我们要对“这是好瓜吗?”这样的问题进行决策时,通常会进行一系列的判断或“子决策”:我们先看“它是什么颜色?”,如果是“青绿色”,则我们再看“它的根蒂是什么形态?”,如果是“蜷缩”,我们再判断“它敲起来是什么声音?”,最后我们得出决策:这是一个好瓜。这个决策如图所示:
决策树能做什么
决策树能实现对数据的探索,能对数据轮廓进行描述,能进行预测和分类,了解哪些变量最重要
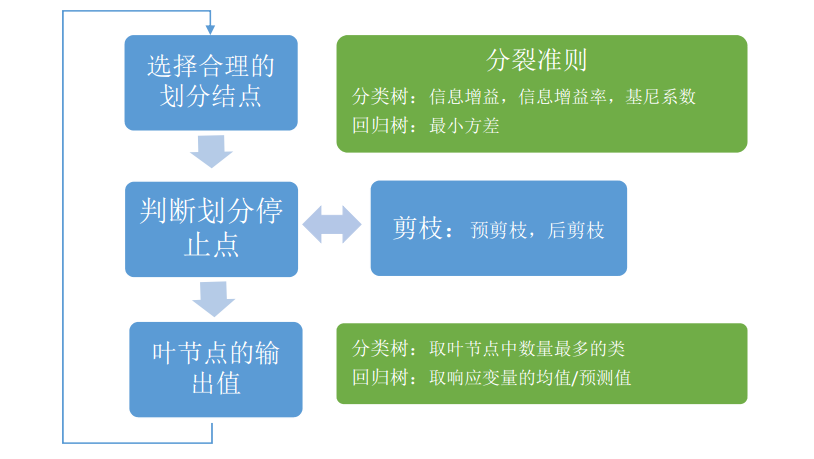
决策树基本流程
几种分列准则
一 信息增益

二 增益率

三 基尼系数

停止条件
1.如果节点中所有观测属于一类。
2.如果该节点中所有观测的属性取值一致。
3.如果树的深度达到设定的阈值。
4.如果该节点所含观测值小于设定的父节点应含观测数的阈值。
5.如果该节点的子节点所含观测数将小于设定的阈值。
6.如果没有属性能满足设定的分裂准则的阈值。
C4.5,对连续属性的处理
在C4.5中,对连续属性的处理如下:
1. 对特征的取值进行升序排序
2. 两个特征取值之间的中点作为可能的分裂点,将数据集分成两部分,计算每个可能的分裂点的信息增益(InforGain)。优化算法就是只计算分类属性发生改变的那些特征取值。
3. 选择修正后信息增益(InforGain)最大的分裂点作为该特征的最佳分裂点
4. 计算最佳分裂点的信息增益率(Gain Ratio)作为特征的Gain Ratio。注意,此处需对最佳分裂点的信息增益进行修正:减去log2(N-1)/|D|(N是连续特征的取值个数,D是训练数据数目,此修正的原因在于:当离散属性和连续属性并存时,C4.5算法倾向于选择连续特征做最佳树分裂点)
R代码实现(C5.0)
一.导入数据集,把目标变量转为因子
setwd("D:\\R_edu\\data")
rm(list=ls())
accepts<-read.csv("accepts.csv")
str(accepts)
accepts$bad_ind<-as.factor(accepts$bad_ind)
names(accepts)
accepts=accepts[,c(,:)]
根据业务理解生成更有意义的衍生变量,不过这些变量都是临时的,因为没有经过数据清洗,此处仅作一个示例
二.将数据分为训练集和测试集
set.seed()
select<-sample(:nrow(accepts),length(accepts$bad_ind)*0.7)
train=accepts[select,]
test=accepts[-select,]
summary(train$bad_ind)
三.运行C50算法建模
train<-na.omit(train)
library(C50)
ls('package:C50')
tc<-C5.0Control(subset =F,CF=0.25,winnow=F,noGlobalPruning=F,minCases =)
model <- C5.(bad_ind ~.,data=train,rules=F,control =tc)
summary( model )
四.图形展示
plot(model)
C5imp(model)
五.生成规则
rule<- C5.(bad_ind ~.,data=train,rules=T,control =tc)
summary( rule )
CRAT算法处理离散型变量
- 记m为样本T中该属性取值的种类数
- 穷举将m种取值分为两类的划分
- 对上述所有划分计算GINI系数
R代码实现CART算法
rpart包中有针对CART决策树算法提供的函数,比如rpart函数
以及用于剪枝的prune函数
rpart函数的基本形式:rpart(formula,data,subset,na.action=na.rpart,method.parms,control,...)
一.设置向前剪枝的条件
tc <- rpart.control(minsplit=,minbucket=,maxdepth=,xval=,cp=0.005)
rpart.control对树进行一些设置
minsplit是最小分支节点数,这里指大于等于20,那么该节点会继续分划下去,否则停止
minbucket:树中叶节点包含的最小样本数
maxdepth:决策树最大深度
xval:交叉验证的次数
cp全称为complexity parameter,指某个点的复杂度,对每一步拆分,模型的拟合优度必须提高的程度
二.建模
rpart.mod=rpart(bad_ind ~.,data=train,method="class",
parms = list(prior = c(0.65,0.35), split = "gini"),
control=tc)
summary(rpart.mod)
#.3看变量重要性
rpart.mod$variable.importance
#cp是每次分割对应的复杂度系数
rpart.mod$cp
plotcp(rpart.mod)
三.画树图
library(rpart.plot)
rpart.plot(rpart.mod,branch=, extra=, under=TRUE, faclen=,
cex=0.8, main="决策树")
四.CART剪枝
prune函数可以实现最小代价复杂度剪枝法,对于CART的结果,每个节点均输出一个对应的cp
prune函数通过设置cp参数来对决策树进行修剪,cp为复杂度系数
我们可以用下面的办法选择具有最小xerror的cp的办法:
rpart.mod.pru<-prune(rpart.mod, cp= rpart.mod$cptable[which.min(rpart.mod$cptable[,"xerror"]),"CP"])
rpart.mod.pru$cp
五.绘制剪枝后的树状图
library(rpart.plot)
rpart.plot(rpart.mod.pru,branch=, extra=, under=TRUE, faclen=,
cex=0.8, main="决策树")
六.CART预测
- 使用模型对测试集进行预测使用模型进行预测
- 使用模型进行预测
rpart.pred<-predict(rpart.mod.pru,test)
可以看到,rpart.pred的结果有两列,第一列是为0的概率,第二列是为1的概率
通过设定阀值,得到预测分类
pre<-ifelse(rpart.pred[,]>0.5,,)
决策树及R语言实现的更多相关文章
- R语言︱决策树族——随机森林算法
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:有一篇<有监督学习选择深度学习 ...
- R语言学习——根据信息熵建决策树KD3
R语言代码 决策树的构建 rm(list=ls()) setwd("C:/Users/Administrator/Desktop/R语言与数据挖掘作业/实验3-决策树分类") #s ...
- R语言学习笔记—决策树分类
一.简介 决策树分类算法(decision tree)通过树状结构对具有某特征属性的样本进行分类.其典型算法包括ID3算法.C4.5算法.C5.0算法.CART算法等.每一个决策树包括根节点(root ...
- 决策树ID3原理及R语言python代码实现(西瓜书)
决策树ID3原理及R语言python代码实现(西瓜书) 摘要: 决策树是机器学习中一种非常常见的分类与回归方法,可以认为是if-else结构的规则.分类决策树是由节点和有向边组成的树形结构,节点表示特 ...
- 数据挖掘算法R语言实现之决策树
数据挖掘算法R语言实现之决策树 最近,看到很多朋友问我如何用数据挖掘算法R语言实现之决策树,想要了解这方面的内容如下: > library("party")导入数据包 > ...
- 关联规则-R语言实现
关联规则code{white-space: pre;} pre:not([class]) { background-color: white; }if (window.hljs && ...
- R语言与数据分析
K最近邻(k-Nearest Neighbor,KNN)分类算法 R语言实现包:R语言中有kknn package实现了weighted k-nearest neighbor. 决策树: R语言实现决 ...
- 机器学习与R语言
此书网上有英文电子版:Machine Learning with R - Second Edition [eBook].pdf(附带源码) 评价本书:入门级的好书,介绍了多种机器学习方法,全部用R相关 ...
- 数据分析与R语言
数据结构 创建向量和矩阵 函数c(), length(), mode(), rbind(), cbind() 求平均值,和,连乘,最值,方差,标准差 函数mean(), sum(), min(), m ...
随机推荐
- 深入分析JS原型链以及为什么不能在原型链上使用对象
在刚刚接触JS原型链的时候都会接触到一个熟悉的名词:prototype:如果你曾经深入过prototype,你会接触到另一个名词:__proto__(注意:两边各有两条下划线,不是一条).以下将会围绕 ...
- Linux 内核版本命名
Linux 内核版本命名在不同的时期有其不同的规范,我们熟悉的也许是 2.x 版本奇数表示开发版.偶数表示稳定版,但到 2.6.x 以及 3.x 甚至将来的 4.x ,内核版本命名都不遵守这样的约定. ...
- SVN提交代码的规范
协同开发中SVN的使用规范 先更新,再提交 SVN更新的原则是要随时更新,随时提交.当完成了一个小功能,能够通过编译并且自己测试之后,谨慎地提交. 如果在修改的期间别人也更改了svn的对应文件, ...
- Spring 02多种注入方式和注解实现DI
一.Bean作用域 spring容器创建的时候,会将所有配置的bean对象创建出来,默认bean都是单例的.代码通过getBean()方法从容器获取指定的bean实例,容器首先会调用Bean类的无参构 ...
- React服务端渲染总结
欢迎吐槽 : ) 本demo地址( 前端库React+mobx+ReactRouter ):https://github.com/Penggggg/react-ssr.本文为笔者自学总结,有错误的地方 ...
- [LeetCode] Island Perimeter 岛屿周长
You are given a map in form of a two-dimensional integer grid where 1 represents land and 0 represen ...
- [LeetCode] Maximum Gap 求最大间距
Given an unsorted array, find the maximum difference between the successive elements in its sorted f ...
- 图解javascript
- 使用 Docker 编译 OpenWRT(Widora)
Docker 是一种新的被称之为容器的虚拟机.本文将使用此工具,进行 OpenWRT 的编译. 在 Docker 中下载 Ubuntu 14.04 的镜像 使用以下命令可以十分方便的从远程服务器上将 ...
- vue.js 第三课
1.构造器 constructor 2.属性和方法 properties methods 3.实例生命周期 instance_lifecycle 1.vue.js都是通过 var vm=new V ...