Ruby用百度搜索爬虫
Ruby用百度搜索爬虫
博主ruby学得断断续续,打算写一个有点用的小程序娱乐一下,打算用ruby通过百度通道爬取网络信息。
第三方库准备
- mechanize:比较方便地处理网络请求,类似于Python中的requests
- nokogiri:解析HTML文本,采用的是jquery选择器
步骤分析
- 用mechanize创建一个agent对象
- 我们首先登录百度主页
- 找到百度『搜索』框的表单
- 填写表单内容
- 提交表单(agent用该表单的内容发出submit动作)
- 分析百度获得的搜索结果列表
- 用nokogiri解析HTML文本,提取出我们感兴趣的内容
代码
require 'mechanize'
require 'nokogiri'
# 百度搜索的关键字,可修改
keyword = 'ruby'
# 创建一个agent对象
agent = Mechanize.new
# 发送get请求获取页面
page = agent.get 'http://www.baidu.com/'
# 根据名字属性定位表单
search_form = page.form_with :name => 'f'
# 填表,搜索框的name是wd
search_form.field_with(:name => "wd").value = keyword
# 提交表单
search_results = agent.submit search_form
doc = Nokogiri::HTML(search_results.body)
doc.css('.c-container > h3 > a').each{
|item|
puts item.text
}
测试结果
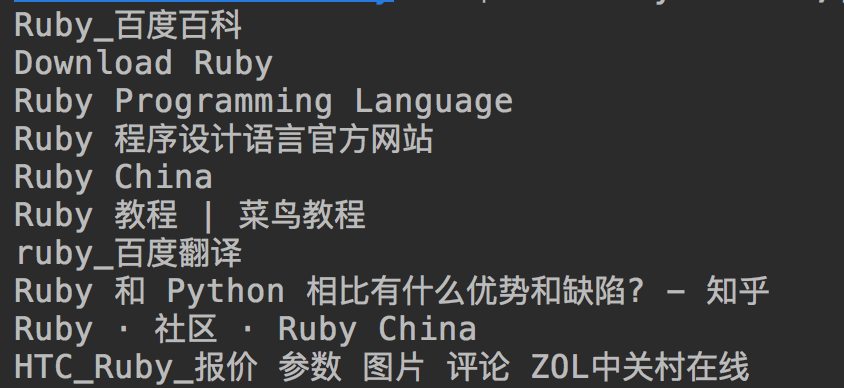
Ruby用百度搜索爬虫的更多相关文章
- 利用python爬取海量疾病名称百度搜索词条目数的爬虫实现
实验原因: 目前有一个医疗百科检索项目,该项目中对关键词进行检索后,返回的结果很多,可惜结果的排序很不好,影响用户体验.简单来说,搜索出来的所有符合疾病中,有可能是最不常见的疾病是排在第一个的,而最有 ...
- PHP网络爬虫实践:抓取百度搜索结果,并分析数据结构
百度的搜索引擎有反爬虫机制,我先直接用guzzle试试水.代码如下: <?php /** * Created by Benjiemin * Date: 2020/3/5 * Time: 14:5 ...
- 使用python抓取百度搜索、百度新闻搜索的关键词个数
由于实验的要求,需要统计一系列的字符串通过百度搜索得到的关键词个数,于是使用python写了一个相关的脚本. 在写这个脚本的过程中遇到了很多的问题,下面会一一道来. ps:我并没有系统地学习过pyth ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- python爬取百度搜索结果ur汇总
写了两篇之后,我觉得关于爬虫,重点还是分析过程 分析些什么呢: 1)首先明确自己要爬取的目标 比如这次我们需要爬取的是使用百度搜索之后所有出来的url结果 2)分析手动进行的获取目标的过程,以便以程序 ...
- 百度搜索:有关Baiduspider的10个问题
猫宁!!! 参考链接: http://help.baidu.com/question?prod_id=99&class=476&id=2996 https://ziyuan.baidu ...
- Python:输入关键字进行百度搜索并爬取搜索结果
学习自:手把手教你用Python爬取百度搜索结果并保存 - 云+社区 - 腾讯云 如何利用python模拟百度搜索,Python交流,技术交流区,鱼C论坛 指定关键字,对其进行百度搜索,保存搜索结果, ...
- jsonp模拟获取百度搜索相关词汇
随便写了个jsonp模拟百度搜索相关词汇的小demo,帮助新手理解jsonp的用法. <!DOCTYPE html><html lang="en">< ...
- Splinter学习--初探1,模拟百度搜索
Splinter是以Selenium, PhantomJS 和 zope.testbrowser为基础构建的web自动化测试工具,基本原理同selenium 支持的浏览器包括:Chrome, Fire ...
随机推荐
- 隐藏WIN10资源管理器中的3D对象文件夹
1.WIN+R,打开运行窗口,输入“regdeit”启动注册表编辑器 2.定位到 HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersio ...
- 根据现有的XML文件生成其对应的实体类
方法如下: 1.将完整的Xml文本复制一下, 2.在vs2013(或以上版本) .net4.5项目下建立一个类文件, 3.依次选择菜单:编辑->选择性粘贴->将XML粘贴为类.
- lua 日期的一些函数
--根据日期获取星期几 function getWeekNum(strDate) local ymd = Split(strDate,"-") t = ]),month=]),da ...
- javascript获取时间戳
时间戳: 时间戳是自 1970 年 1 月 1 日(00:00:00 GMT)以来的秒数.它也被称为 Unix 时间戳(Unix Timestamp). JavaScript 获取当前时间戳: < ...
- Summary of continuous function spaces
In general differential calculus, we have learned the definitions of function continuity, such as fu ...
- nginx做负载均衡 tomcat获得客户端真实ip
因项目需要做tomcat2台机器的负载均衡,配置好负载环境后,发现tomcat的日志一律是我前置nginx代理服务器的ip 通过百度教材发现需要修改nginx的配置文件,修改代理头信息,传递给后方,后 ...
- Json常用组件
Json2.js 开发者:json官网:http://www.json.org/. 适用环境:用于在不支持JSON对象的浏览器(通常是国内使用IE内核的第三方浏览器)下使用.json2.js提供了 ...
- Python学习(十七)—— 数据库(二)
转载自http://www.cnblogs.com/linhaifeng/articles/7356064.html 一. 数据库管理软件的由来 基于我们之前所学,数据要想永久保存,都是保存于文件中, ...
- LeetCode 234. 回文链表
class Solution { public: bool isPalindrome(ListNode* head) { deque<int> d1, d2; ListNode* p = ...
- MATLAB的一些使用的快捷键整理
1.用TAB键可以实现缩进,怎么缩进和取消缩进呢? 在使用脚本编写matlab的程序时,我们通过选中需要的程序,按下tab键就能缩进整个程序.同样的,当我们需要取消缩进时,我们的快捷方法就是:shif ...