浅析requests库响应对象的text和content属性
在做爬虫时请求网页的requests库是必不可少的,我们常常会用到 res = resquests.get(url) 方法,在获取网页的html代码时常常使用res的text属性: html = res.text,在下载图片或文件时常常使用res的content属性:
- with open(filename, 'wb') as fp:
- fp.write(res.content)
下面我们来看看 'text' 和 'content' 的不同之处:
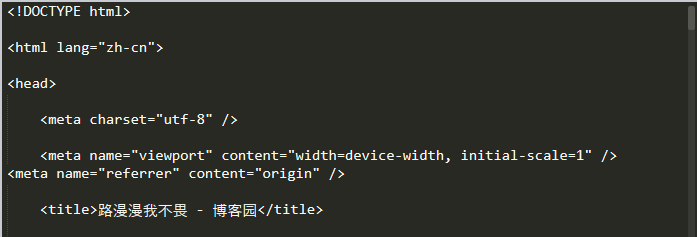
输出本博客的响应对象的 text
- import requests
- url = 'https://www.cnblogs.com/huwt/'
- res = requests.get(url, timeout = 6)
- print(res.text)
(只截取到<title>标签)
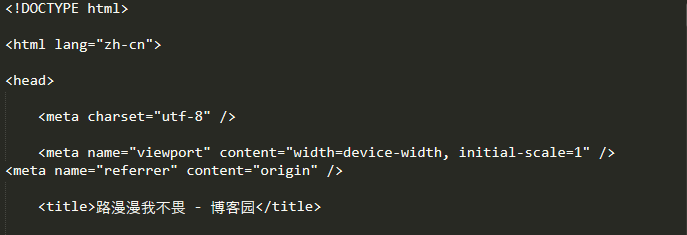
输出本博客的响应对象的 content
- import requests
- url = 'https://www.cnblogs.com/huwt/'
- res = requests.get(url, timeout = 6)
- print(res.content)
(只截取到<title>标签)

通过<title>标签我们可以看出 res.text 直接输出了汉字,而 res.content 好像是以十六进制的形式来表示汉字
为了让进一步了解text 和 content 我们来看看它们的类型:
- import requests
- url = 'https://www.cnblogs.com/huwt/'
- res = requests.get(url, timeout = 6)
- print(type(res.text))
- print(type(res.content))

我们可以看到res.text是字符串类型,而res.content是二进制类型
为了进一步验证我们使用bytes类型的decode()方法对content进行‘utf-8’编码再显示
- import requests
- url = 'https://www.cnblogs.com/huwt/'
- res = requests.get(url, timeout = 6)
- print(res.content.decode('utf-8'))
发现和res.text显示的内容完全一样
因此我们可以得出结论:
- resp.text返回的是Unicode型的数据。
- resp.content返回的是bytes型也就是二进制的数据。、
- 获取文本一般使用res.text, 获取图片或文件一般使用res.conten
再做几点补充:
- text是content经过编码之后的字符串,那编码方式是什么呢?
- 在返回text时requests会基于 HTTP 头部对响应的编码作出有根据的推测,但不一定准确,有可能出现乱码,
- 而我们可以手动指定一种编码方式:res.encoding = '需要的编码方式'
- 或让requests根据body进行猜测:res.encoding = res.apparent_encoding
参考学习:
https://zhidao.baidu.com/question/941417472703558372.html
https://www.cnblogs.com/loveyouyou616/p/8135678.html
https://www.cnblogs.com/chownjy/p/6625299.html
https://www.jianshu.com/p/0e0336b370f3
浅析requests库响应对象的text和content属性的更多相关文章
- requests库响应消息体的四种格式
1.r.text 文本响应内容,返回字符串类型,获取网页html时用: 2.r.content 字节响应内容,返回字节类型,下载图片或者文件时用: 3.r.json json解码响应内容,返回字典 ...
- Requests库的文档高级用法
高级用法 本篇文档涵盖了 Requests 的一些高级特性. 会话对象 会话对象让你能够跨请求保持某些参数.它也会在同一个 Session 实例发出的所有请求之间保持 cookie, 期间使用 url ...
- requests库学习案例
requests库使用流程 使用流程/编码流程 1.指定url 2.基于requests模块发起请求 3.获取响应对象中的数据值 4.持久化存储 分析案例 需求:爬取搜狗首页的页面数据 # 爬取搜狗首 ...
- Python爬虫 requests库基础
requests库简介 requests是使用Apache2 licensed 许可证的HTTP库. 用python编写. 比urllib2模块更简洁. Request支持HTTP连接保持和连接池,支 ...
- express-6 请求和响应对象(1)
URL的组成部分 协议: 协议确定如何传输请求.我们主要是处理http和https.其他常见的协议还有file和ftp. 主机名: 主机名标识服务器.运行在本地计算机(localhost)和本地网络的 ...
- Node+Express中请求和响应对象
在用 Express 构建 Web 服务器时,大部分工作都是从请求对象开始,到响应对象终止. url的组成: 协议协议确定如何传输请求.我们主要是处理 http 和 https.其他常见的协议还有 f ...
- 【转载】requests库的7个主要方法、13个关键字参数以及响应对象的5种属性
Python爬虫常用模块:requests库的7个主要方法.13个关键字参数以及响应对象的5种属性 原文链接: https://zhuanlan.zhihu.com/p/67489739
- 4.爬虫 requests库讲解 GET请求 POST请求 响应
requests库相比于urllib库更好用!!! 0.各种请求方式 import requests requests.post('http://httpbin.org/post') requests ...
- 使用Python的requests库进行接口测试——session对象的妙用
from:http://blog.csdn.net/liuchunming033/article/details/48131051 在进行接口测试的时候,我们会调用多个接口发出多个请求,在这些请求中有 ...
随机推荐
- VB.NET 定义多行文本字符的几种方式
vbCrLf 在 .NET 刚刚推出的时候,VB作为一款被微软用来"衬托"C#的语言,在许多细节设计上远不如C#方便. 比如在C#中写一个多行文本,就有各种方式: string s ...
- Eclipse 中打包插件 Fat Jar 的安装与使用
Eclipse可以安装一个叫Fat Jar的插件,用这个插件打包非常方便,Fat Jar的功能非常强大. 首先要下载Fat Jar,下载地址:https://sourceforge.net/proje ...
- webpack打包工具
目的:平时小项目中例如一些网站需要进行打包压缩,用这个工具可以进行打包压缩,就可以上传到服务器. 使用方法: 1,引进需要打包的项目,把入口html替换掉项目中的index.html,把引进的js,c ...
- Android分享内容和接收分享内容小小实现
先来说说分享,毕竟没有分享何来接收分享可谈? 分享目前已实现的有两种方式:后台代码实现.ShareActionProvider实现,接着先说通过代码实现 Intent intent=new Inten ...
- Python:SQLMap源码精读—基于错误的盲注(error-based blind)
目标网址 http://127.0.0.1/shentou/sqli-labs-master/Less-5/?id=1 Payload的生成 <test> <title>MyS ...
- Kafka项目实战-用户日志上报实时统计之分析与设计
1.概述 本课程的视频教程地址:<Kafka实战项目之分析与设计> 本课程我通过一个用户实时上报日志案例作为基础,带着大家去分析Kafka这样一个项目的各个环节,从而对项目的整体设计做比 ...
- 使用Dockerfile创建支持SSH服务的镜像
1.前面我们学习了使用Dockerfile,那接下来我们就用Dockerfile创建一个支持SSH服务的镜像. 2.首先创建一个目录ssh_centos [root@rocketmq-nameserv ...
- leetcode — valid-parentheses
import java.util.Stack; /** * Source : https://oj.leetcode.com/problems/valid-parentheses/ * * Creat ...
- Netty入门简介
前言 Netty是一个高性能.异步事件驱动的NIO框架,它提供了对TCP.UDP和文件传输的支持,作为一个异步NIO框架,Netty的所有IO操作都是异步非阻塞的,通过Future-Listener机 ...
- Crypto++应用:非对称加密RSA
1,非对称加密RSA: (1)乙方生成两把密钥(公钥和私钥).公钥是公开的,任何人都可以获得,私钥则是保密的. (2)甲方获取乙方的公钥,然后用它对信息加密. (3)乙方得到加密后的信息,用私钥解密. ...