logstash-input-jdbc实现mysql 与elasticsearch实时同步(ES与关系型数据库同步)
引言:
elasticsearch 的出现使得我们的存储、检索数据更快捷、方便。但很多情况下,我们的需求是:现在的数据存储在mysql、oracle等关系型传统数据库中,如何尽量不改变原有数据库表结构,将这些数据的insert,update,delete操作结果实时同步到elasticsearch(简称ES)呢?
本文基于以上需求点展开实战讨论。
1.对delete操作的实时同步泼冷水
到目前为止,所有google,stackoverflow,elastic.co,github上面搜索的插件和实时同步的信息,告诉我们:目前同步delete还没有好的解决方案。
折中的解决方案如下:
方案探讨:https://discuss.elastic.co/t/delete-elasticsearch-document-with-logstash-jdbc-input/47490/9
http://stackoverflow.com/questions/34477095/elasticsearch-replication-of-other-system-data/34477639#34477639
方案一,
在原有的mysql数据库表中,新增一个字段status, 默认值为ok,如果要删除数据,实则用update操作,status改为deleted.
这样,就能同步到es中。es中以status状态值区分该行数据是否存在。deleted代表已删除,ok代表正常。
方案二,
使用go elasticsearch 插件实现同步,如:。但是我实操发现,该插件不稳定,bug较多。我也给源码作者提出了bug。
Bug详见:https://github.com/siddontang/go-mysql-elasticsearch/issues/46
关于删除操作的最终讨论解决方案(截止2016年6月24日):
首先,软件删除而非物理删除数据,新增一个 flag 列,标识记录是否已经被删除,这样,相同的记录也会存在于Elasticsearch。可以执行简单的term查询操作,检索出已经删除的数据信息。
其次,若需要执行cleanup清理数据操作(物理删除),只需要在数据库和ES中同时删除掉标记位deleted的记录即可。如:mysql执行:delete from cc where cc.flag=’deleted’; ES同样执行对应删除操作。
2.如何使用 插件实现insert,update 的同步更新操作?
我的上一篇博文:http://blog.csdn.net/laoyang360/article/details/51694519 做了些许探讨。
除了上篇文章提到的三个插件,这里推荐试用过比较好用的logstash的一款插件,名称为: logstash-input-jdbc
3.如何安装logstash-input-jdbc插件?
【注意啦,注意啦20170920】:logstash5.X开始,已经至少集成了logstash-input-jdbc插件。所以,你如果使用的是logstash5.X,可以不必再安装,可以直接跳过这一步。
参考:http://blog.csdn.net/yeyuma/article/details/50240595#quote
网友博文已经介绍很详细,不再赘述。
基本到这一步:
cd /opt/logstash/
sudo bin/plugin install logstash-input-jdbc
到此,基本就能成功。若不能请留言。
4,如何实现实时同步?
4.1 前提:mysql存在的数据库及表
数据库名为:test
test下表名为:cc
表中数据为:
-
mysql> use test;
-
Reading table information for completion of table and column names
-
You can turn off this feature to get a quicker startup with -A
-
-
Database changed
-
mysql> select * from cc;
-
+----+--------------------+---------+---------------------+
-
| id | name | status | modified_at |
-
+----+--------------------+---------+---------------------+
-
| 1 | laoyang360 | ok | 0000-00-00 00:00:00 |
-
| 2 | test002 | ok | 2016-06-23 06:16:42 |
-
| 3 | dllaoyang | ok | 0000-00-00 00:00:00 |
-
| 4 | huawei | ok | 0000-00-00 00:00:00 |
-
| 5 | jdbc_test_update08 | ok | 0000-00-00 00:00:00 |
-
| 7 | test7 | ok | 0000-00-00 00:00:00 |
-
| 8 | test008 | ok | 0000-00-00 00:00:00 |
-
| 9 | test9 | ok | 0000-00-00 00:00:00 |
-
| 10 | test10 | deleted | 0000-00-00 00:00:00 |
-
+----+--------------------+---------+---------------------+
-
9 rows in set (0.01 sec)
4.2 需要两个文件:1)jdbc.conf; 2)jdbc.sql.
-
[root@5b9dbaaa148a logstash_jdbc_test]# cat jdbc.conf
-
input {
-
stdin {
-
}
-
jdbc {
-
# mysql jdbc connection string to our backup databse 后面的test对应mysql中的test数据库
-
jdbc_connection_string => "jdbc:mysql://192.168.1.1:3306/test"
-
# the user we wish to excute our statement as
-
jdbc_user => "root"
-
jdbc_password => "******"
-
# the path to our downloaded jdbc driver
-
jdbc_driver_library => "/elasticsearch-jdbc-2.3.2.0/lib/mysql-connector-java-5.1.38.jar"
-
# the name of the driver class for mysql
-
jdbc_driver_class => "com.mysql.jdbc.Driver"
-
jdbc_paging_enabled => "true"
-
jdbc_page_size => "50000"
-
#以下对应着要执行的sql的绝对路径。
-
statement_filepath => "/usr/local/logstash/bin/logstash_jdbc_test/jdbc.sql"
-
#定时字段 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新(测试结果,不同的话请留言指出)
-
schedule => "* * * * *"
-
#设定ES索引类型
-
type => "cc_type"
-
}
-
}
-
-
filter {
-
json {
-
source => "message"
-
remove_field => ["message"]
-
}
-
}
-
-
output {
-
elasticsearch {
-
#ESIP地址与端口
-
hosts => "192.168.1.1:9200"
-
#ES索引名称(自己定义的)
-
index => "cc_index"
-
#自增ID编号
-
document_id => "%{id}"
-
}
-
stdout {
-
#以JSON格式输出
-
codec => json_lines
-
}
-
}
-
-
#要执行的sql语句。
-
选择哪些信息同步到ES中。
-
[root@5b9dbaaa148a logstash_jdbc_test]# cat jdbc.sql
-
select
-
*
-
from
-
where cc.modified_at > :sql_last_value
[注意啦!注意啦!注意啦!]
cc.modified_at, 这个modified_at是我自己定义的更改时间字段,默认值default是now()当前时间。
而 :sql_last_value如果input里面use_column_value => true, 即如果设置为true的话,可以是我们设定的字段的上一次的值。
默认 use_column_value => false, 这样 :sql_last_value为上一次更新的最后时刻值。
也就是说,对于新增的值,才会更新。这样就实现了增量更新的目的。
有童鞋问,如何全量更新呢? 答案:就是去掉where子句即可。
步骤1:
在logstash的bin路径下新建文件夹logstash_jdbc_test,并将上两个文件 1)jdbc.conf,2)jdbc.sql.模板拷贝到里面。
步骤2:
按照自己的mysql地址、es地址、建立的索引名称、类型名称修改conf,以及要同步内容修改sql。
步骤3:
执行logstash, 如下:
[root@5b9dbaaa148a plugins]# ./logstash -f ./logstash_jdbc_test/jdbc.conf
步骤4:
验证同步是否成功。
可以通过: 如下图所示:
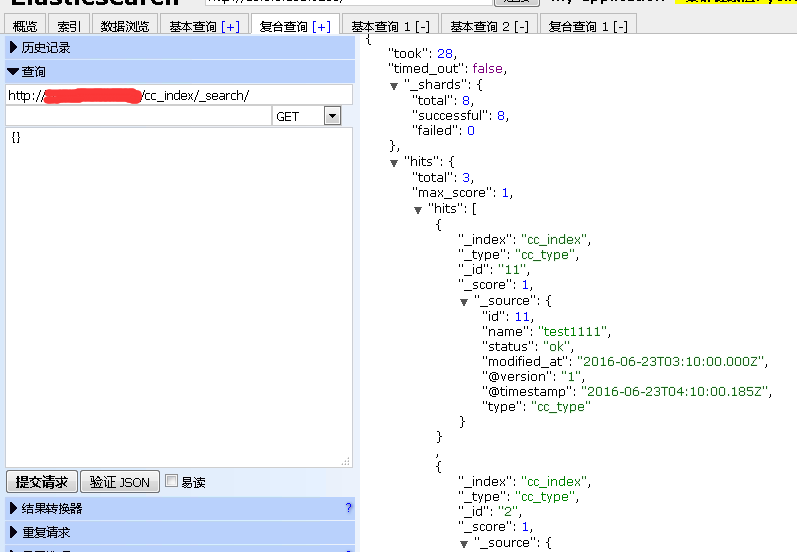
5,注意事项
如果你要测试go-mysql-elasticsearch可能会遇到下面三个Bug及解决方案如下:
【Bug1】
How to Setting The Binary Log Format
http://dev.mysql.com/doc/refman/5.7/en/binary-log-setting.html
【Bug2】
what is inner http status address
https://github.com/siddontang/go-mysql-elasticsearch/issues/11
【Bug3】
[2016/06/23 10:19:38] canal.go:146 [Error] canal start sync binlog err: ERROR 1236 (HY000): Misconfigured master - server id was not set
http://dba.stackexchange.com/questions/76089/error-1236-from-master-after-restored-replication
原文地址:https://blog.csdn.net/zkf541076398/article/details/79973090
logstash-input-jdbc实现mysql 与elasticsearch实时同步(ES与关系型数据库同步)的更多相关文章
- mysql 与elasticsearch实时同步常用插件及优缺点对比(ES与关系型数据库同步)
前言: 目前mysql与elasticsearch常用的同步机制大多是基于插件实现的,常用的插件包括:elasticsearch-jdbc, elasticsearch-river-MySQL , g ...
- canal 实现Mysql到Elasticsearch实时增量同步
简介: MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品.MySQL是一种关系数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第二篇:canal 实现Mysql到Elasticsearch实时增量同步
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484377&idx=1&sn=199bc88 ...
- logstash input jdbc连接数据库
示例 以下配置能够实现从 SQL Server 数据库中查询数据,并增量式的把数据库记录导入到 ES 中. 1. 查询的 SQL 语句在 statement_filepath => " ...
- MySQL系列(十二)--如何设计一个关系型数据库(基本思路)
设计一个关系型数据库,也就是设计RDBMS(Relational Database Management System),这个问题考验的是对RDBMS各个模块的划分, 以及对数据库结构的了解.只要讲述 ...
- LogStash如何通过jdbc 从mysql导入elasticsearch
input { stdin { } jdbc { # mysql jdbc connection string to our backup databse jdbc_connection_string ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第五篇:logstash-input-jdbc实现mysql 与elasticsearch实时同步深入详解
文章转载自: https://blog.csdn.net/laoyang360/article/details/51747266 引言: elasticsearch 的出现使得我们的存储.检索数据更快 ...
- 一脸懵逼学习HBase---基于HDFS实现的。(Hadoop的数据库,分布式的,大数据量的,随机的,实时的,非关系型数据库)
1:HBase官网网址:http://hbase.apache.org/ 2:HBase表结构:建表时,不需要指定表中的字段,只需要指定若干个列族,插入数据时,列族中可以存储任意多个列(即KEY-VA ...
- JavaWeb学习笔记(十四)—— 使用JDBC处理MySQL大数据
一.什么是大数据 所谓大数据,就是大的字节数据,或大的字符数据.大数据也称之为LOB(Large Objects),LOB又分为:clob和blob,clob用于存储大文本,blob用于存储二进制数据 ...
随机推荐
- luogu2341 [HAOI2006]受欢迎的牛
题目大意 每头奶牛都梦想成为牛棚里的明星.被所有奶牛喜欢的奶牛就是一头明星奶牛.所有奶牛都是自恋狂,每头奶牛总是喜欢自己的.奶牛之间的“喜欢”是可以传递的——如果A喜欢B,B喜欢C,那么A也喜欢C.牛 ...
- oc62--block1
// // main.m // Block的应用场景 // typedef void (^workBlock)(); #import <Foundation/Foundation.h> / ...
- hdoj--5100--Chessboard(数学推理)
Chessboard Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) To ...
- 洛谷P1725琪露诺(单调队列优化dp)
P1725 琪露诺 题目描述 在幻想乡,琪露诺是以笨蛋闻名的冰之妖精.某一天,琪露诺又在玩速冻青蛙,就是用冰把青蛙瞬间冻起来.但是这只青蛙比以往的要聪明许多,在琪露诺来之前就已经跑到了河的对岸.于是琪 ...
- flash 遮住 div 解决办法
被遮盖的div 下面的代码 <!--列表菜单--> <div id="opreationmenu" style="posit ...
- Cracking the Coding Interview 10.7
Design an algorithm to find the kth number such that the only prime factors are 3,5 and 7 方法一: a[i]= ...
- asp.net MVC 路由注册
1.命名空间的优先级 在路由注册时指定的命名空间比当前 ControllerBuilder 的默认命名空间具有更高的匹配优先级,但是对于这两个集合中的所有命名空间却具有相同的匹配优先级.换句话说,用于 ...
- linux下常用命令失效
注意:修改一下PATH环境变量 export PATH=/bin:/usr/bin/:. 可以把这句话加到你的.profile或者.bash_profile里,这样每次登录的时候都会生效
- CSS清除浮动_清除float浮——详解overflow:hidden 与clear:both属性
最近刚好碰到这个问题,看完这个就明白了.写的很好,所以转载了! CSS清除浮动_清除float浮动 CSS清除浮动方法集合 一.浮动产生原因 - TOP 一般浮动是什么情况呢?一般是一个盒子里 ...
- JAVA软件工程师应该具备的技能有哪些?
前言:有朋友问我:学历和能力哪个重要?我个人觉得能力大于学历,没有能力哪来的学历,学历只是证明能力的一方面.为此在能力方面畅谈java软件工程师必备的能力.作为一名合格的java工程师,不仅需要学历, ...