fork函数详解
一、fork入门知识
一个进程,包括代码、数据和分配给进程的资源。fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
我们来看一个例子:
/*
* fork_test.c
* version 1
* Created on: 2010-5-29
* Author: wangth
*/
#include <unistd.h>
#include <stdio.h>
int main ()
{
pid_t fpid; //fpid表示fork函数返回的值
int count=;
fpid=fork();
if (fpid < )
printf("error in fork!");
else if (fpid == ) {
printf("i am the child process, my process id is %d/n",getpid());
printf("我是爹的儿子/n");//对某些人来说中文看着更直白。
count++;
}
else {
printf("i am the parent process, my process id is %d/n",getpid());
printf("我是孩子他爹/n");
count++;
}
printf("统计结果是: %d/n",count);
return ;
}
运行结果是:
i am the child process, my process id is 5574
我是爹的儿子
统计结果是: 1
i am the parent process, my process id is 5573
我是孩子他爹
统计结果是: 1
在语句fpid=fork()之前,只有一个进程在执行这段代码,但在这条语句之后,就变成两个进程在执行了,这两个进程的几乎完全相同,将要执行的下一条语句都是if(fpid<0)……
为什么两个进程的fpid不同呢,这与fork函数的特性有关。fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值;
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。
fork出错可能有两种原因:
1)当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN。
2)系统内存不足,这时errno的值被设置为ENOMEM。
创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。
每个进程都有一个独特(互不相同)的进程标识符(process ID),可以通过getpid()函数获得,还有一个记录父进程pid的变量,可以通过getppid()函数获得变量的值。
fork执行完毕后,出现两个进程,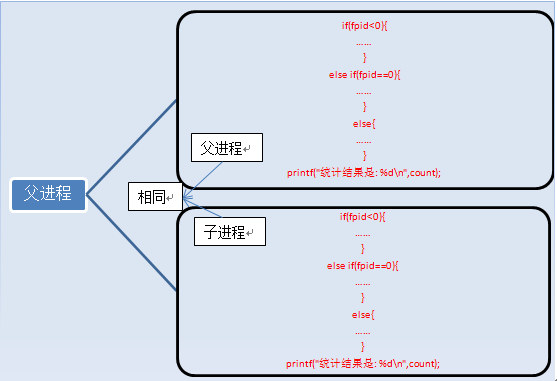
执行完fork后,进程1的变量为count=0,fpid!=0(父进程)。进程2的变量为count=0,fpid=0(子进程),这两个进程的变量都是独立的,存在不同的地址中,不是共用的,这点要注意。可以说,我们就是通过fpid来识别和操作父子进程的。
有人可能疑惑为什么不是从#include处开始复制代码的,这是因为fork是把进程当前的情况拷贝一份,执行fork时,进程已经执行完了int count=0;fork只拷贝下一个要执行的代码到新的进程。
二、fork进阶知识
1.先看一份代码:
/*
* fork_test.c
* version 2
* Created on: 2010-5-29
* Author: wangth
*/
#include <unistd.h>
#include <stdio.h>
int main(void)
{
int i=;
printf("i son/pa ppid pid fpid/n");
//ppid指当前进程的父进程pid
//pid指当前进程的pid,
//fpid指fork返回给当前进程的值
for(i=;i<;i++){
pid_t fpid=fork();
if(fpid==)
printf("%d child %4d %4d %4d/n",i,getppid(),getpid(),fpid);
else
printf("%d parent %4d %4d %4d/n",i,getppid(),getpid(),fpid);
}
return ;
}
运行结果是:
i son/pa ppid pid fpid
0 parent 2043 3224 3225
0 child 3224 3225 0
1 parent 2043 3224 3226
1 parent 3224 3225 3227
1 child 1 3227 0
1 child 1 3226 0
这份代码比较有意思,我们来认真分析一下:
第一步:在父进程中,指令执行到for循环中,i=0,接着执行fork,fork执行完后,系统中出现两个进程,分别是p3224和p3225(后面我都用pxxxx表示进程id为xxxx的进程)。可以看到父进程p3224的父进程是p2043,子进程p3225的父进程正好是p3224。我们用一个链表来表示这个关系:
p2043->p3224->p3225
第一次fork后,p3224(父进程)的变量为i=0,fpid=3225(fork函数在父进程中返向子进程id),代码内容为:
for(i=;i<;i++){
pid_t fpid=fork();//执行完毕,i=0,fpid=3225
if(fpid==)
printf("%d child %4d %4d %4d/n",i,getppid(),getpid(),fpid);
else
printf("%d parent %4d %4d %4d/n",i,getppid(),getpid(),fpid);
}
return ;
p3225(子进程)的变量为i=0,fpid=0(fork函数在子进程中返回0),代码内容为:
for(i=;i<;i++){
pid_t fpid=fork();//执行完毕,i=0,fpid=0
if(fpid==)
printf("%d child %4d %4d %4d/n",i,getppid(),getpid(),fpid);
else
printf("%d parent %4d %4d %4d/n",i,getppid(),getpid(),fpid);
}
return ;
所以打印出结果:
0 parent 2043 3224 3225
0 child 3224 3225 0
第二步:假设父进程p3224先执行,当进入下一个循环时,i=1,接着执行fork,系统中又新增一个进程p3226,对于此时的父进程,p2043->p3224(当前进程)->p3226(被创建的子进程)。
对于子进程p3225,执行完第一次循环后,i=1,接着执行fork,系统中新增一个进程p3227,对于此进程,p3224->p3225(当前进程)->p3227(被创建的子进程)。从输出可以看到p3225原来是p3224的子进程,现在变成p3227的父进程。父子是相对的,这个大家应该容易理解。只要当前进程执行了fork,该进程就变成了父进程了,就打印出了parent。
所以打印出结果是:
1 parent 2043 3224 3226
1 parent 3224 3225 3227
第三步:第二步创建了两个进程p3226,p3227,这两个进程执行完printf函数后就结束了,因为这两个进程无法进入第三次循环,无法fork,该执行return 0;了,其他进程也是如此。
以下是p3226,p3227打印出的结果:
1 child 1 3227 0
1 child 1 3226 0
细心的读者可能注意到p3226,p3227的父进程难道不该是p3224和p3225吗,怎么会是1呢?这里得讲到进程的创建和死亡的过程,在p3224和p3225执行完第二个循环后,main函数就该退出了,也即进程该死亡了,因为它已经做完所有事情了。p3224和p3225死亡后,p3226,p3227就没有父进程了,这在操作系统是不被允许的,所以p3226,p3227的父进程就被置为p1了,p1是永远不会死亡的,至于为什么,这里先不介绍,留到“三、fork高阶知识”讲。
总结一下,这个程序执行的流程如下: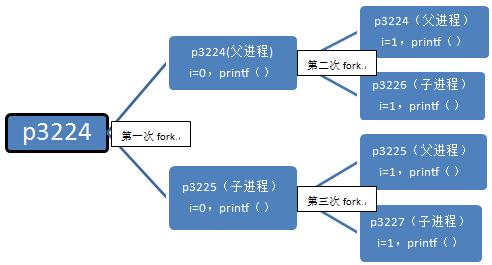
这个程序最终产生了3个子进程,执行过6次printf()函数。
2.我们再来看一份代码:
/*
* fork_test.c
* version 3
* Created on: 2010-5-29
* Author: wangth
*/
#include <unistd.h>
#include <stdio.h>
int main(void)
{
int i=;
for(i=;i<;i++){
pid_t fpid=fork();
if(fpid==)
printf("son/n");
else
printf("father/n");
}
return ;
}
它的执行结果是:
father
son
father
father
father
father
son
son
father
son
son
son
father
son
这里就不做详细解释了,只做一个大概的分析。
for i=0 1 2
father father father
son
son father
son
son father father
son
son father
son
其中每一行分别代表一个进程的运行打印结果。
总结一下规律,对于这种N次循环的情况,执行printf函数的次数为2*(1+2+4+……+2N-1)次,创建的子进程数为1+2+4+……+2N-1个。
3.最后,对printf的缓冲机制做一个简单分析,代码如下:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h> int main()
{
pid_t pid; printf("parent\n");
pid = fork();
if ( == pid)
{
printf("child\n");
}
else if (pid > )
{
printf("parent\n");
}
else if (pid < )
{
printf("error\n");
}
return ;
}
输出结果为:
parent
parent
child
我把第一个printf里的'\n'去掉后,测试的输出结果是:
parentparent
parentchild
为什么两种情况的输出结果差一个parent呢,因为prient函数存在缓冲机制,在详细介绍之前,先对缓冲做简要了解:
缓冲区又称为缓存,它是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。
缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
为什么要引入缓冲区
比如我们从磁盘里取信息,我们先把读出的数据放在缓冲区,计算机再直接从缓冲区中取数据,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作大大快于对磁盘的操作,故应用缓冲区可大大提高计算机的运行速度。
又比如,我们使用打印机打印文档,由于打印机的打印速度相对较慢,我们先把文档输出到打印机相应的缓冲区,打印机再自行逐步打印,这时我们的CPU可以处理别的事情。
现在您基本明白了吧,缓冲区就是一块内存区,它用在输入输出设备和CPU之间,用来缓存数据。它使得低速的输入输出设备和高速的CPU能够协调工作,避免低速的输入输出设备占用CPU,解放出CPU,使其能够高效率工作。
缓冲区的类型
缓冲区 分为三种类型:全缓冲、行缓冲和不带缓冲。
1) 全缓冲
在这种情况下,当填满标准I/O缓存后才进行实际I/O操作。全缓冲的典型代表是对磁盘文件的读写。
2) 行缓冲
在这种情况下,当在输入和输出中遇到换行符时,执行真正的I/O操作。这时,我们输入的字符先存放在缓冲区,等按下回车键换行时才进行实际的I/O操作。典型代表是标准输入(stdin)和标准输出(stdout)。
3) 不带缓冲
也就是不进行缓冲,标准出错情况stderr是典型代表,这使得出错信息可以直接尽快地显示出来。
由此可知,因为printf函数其实调用的是全局宏stdout(标准输出),所以printf的缓冲属于行缓冲。
那什么情况下会刷新缓冲区?
- 程序结束时调用 exit(0) .
- 遇到 \n , \r 时会刷新缓冲区.
- 手动刷新 fflush .
- 缓冲区满时自动刷新.
我们知道了以上内容后,回到刚才的代码
printf函数在执行输出内容时,操作系统仅仅是把该内容放到了stdout的缓冲队列里,并没有实际的写到屏幕上。但是,只要看到有\n 则会立即刷新stdout,因此就马上能够打印了。
运行了printf("parent")后,“parent”仅仅被放到了缓冲里,程序运行到fork()时缓冲里面的“parent” 被子进程复制过去了。因此在子进程度stdout缓冲里面就也有了parent。所以,最终看到的会是parent 被printf了2次。
而运行printf("parent/n")后,,parent被立即打印到了屏幕上,之后fork()的子进程里的stdout缓冲里不会有“parent”。因此最终看到的结果parent只被printf了1次。
fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,linux中引入了“写时复制“技术,也就是只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。在fork之后exec之前两个进程用的是相同的物理空间(内存区),子进程的代码段、数据段、堆栈都是指向父进程的物理空间,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间,如果没有exec,内核会给子进程的数据段、堆栈段分配相应的物理空间(至此两者有各自的进程空间,互不影响),而代码段继续共享父进程的物理空间(两者的代码完全相同)。而如果是因为exec,由于两者执行的代码不同,子进程的代码段也会分配单独的物理空间。
fork时子进程获得父进程数据空间、堆和栈的复制,所以变量的地址(当然是虚拟地址)也是一样的。
每个进程都有自己的虚拟地址空间,不同进程的相同的虚拟地址显然可以对应不同的物理地址。因此地址相同(虚拟地址)而值不同没什么奇怪。 具体过程是这样的: fork子进程完全复制父进程的栈空间,也复制了页表,但没有复制物理页面,所以这时虚拟地址相同,物理地址也相同,但是会把父子共享的页面标记为“只读”(类似mmap的private的方式),如果父子进程一直对这个页面是同一个页面,知道其中任何一个进程要对共享的页面“写操作”,这时内核会复制一个物理页面给这个进程使用,同时修改页表。而把原来的只读页面标记为“可写”,留给另外一个进程使用。
这就是所谓的“写时复制”。正因为fork采用了这种写时复制的机制,所以fork出来子进程之后,父子进程哪个先调度呢?内核一般会先调度子进程,因为很多情况下子进程是要马上执行exec,会清空栈、堆。。这些和父进程共享的空间,加载新的代码段。。。,这就避免了“写时复制”拷贝共享页面的机会。如果父进程先调度很可能写共享页面,会产生“写时复制”的无用功。所以,一般是子进程先调度滴。
假定父进程malloc的指针指向0x12345678, fork 后,子进程中的指针也是指向0x12345678,但是这两个地址都是虚拟内存地址 (virtual memory),经过内存地址转换后所对应的 物理地址是不一样的。所以两个进城中的这两个地址相互之间没有任何关系。
(注1:在理解时,你可以认为fork后,这两个相同的虚拟地址指向的是不同的物理地址,这样方便理解父子进程之间的独立性) (注2:但实际上,linux为了提高 fork 的效率,采用了 copy-on-write 技术,fork后,这两个虚拟地址实际上指向相同的物理地址(内存页),只有任何一个进程试图修改这个虚拟地址里的内容前,两个虚拟地址才会指向不同的物理地址(新的物理地址的内容从原物理地址中复制得到))
4.
*********父进程为什么要创建子进程呢?*************
前面我们已经说过了Linux是一个多用户操作系统,在同一时间会有许多的用户在争夺系统的资源.有时进程为了早一点完成任务就创建子进程来争夺资源. 一旦子进程被创建,父子进程一起从fork处继续执行,相互竞争系统的资源.有时候我们希望子进程继续执行,而父进程阻塞,直到子进程完成任务.这个时候我们可以调用wait或者waitpid系统调用.
,对子进程来说,fork返回给它0,但它的pid绝对不会是0;之所以fork返回0给它,是因为它随时可以调用getpid()来获取自己的pid;
fork之后父子进程除非采用了同步手段,否则不能确定谁先运行,也不能确定谁先结束。认为子进程结束后父进程才从fork返回的,这是不对的,fork不是这样的,vfork才这样。
*****************************************为什么返回0呢**************************************************
首先必须有一点要清楚,函数的返回值是储存在寄存器eax中的。
其次,当fork返回时,新进程会返回0是因为在初始化任务结构时,将eax设置为0;
在fork中,把子进程加入到可运行的队列中,由进程调度程序在适当的时机调度运行。也就是从此时开始,当前进程分裂为两个并发的进程。
无论哪个进程被调度运行,都将继续执行fork函数的剩余代码,执行结束后返回各自的值。
***********************************************fork()之后的寄存器具体执行*************************************
【NOTE5】
对于fork来说,父子进程共享同一段代码空间,所以给人的感觉好像是有两次返回,其实对于调用fork的父进程来说,如果fork出来的子进程没有得到调度,那么父进程从fork系统调用返回,同时分析sys_fork知道,fork返回的是子进程的id。再看fork出来的子进程,由 copy_process函数可以看出,子进程的返回地址为ret_from_fork(和父进程在同一个代码点上返回),返回值直接置为0。所以当子进程得到调度的时候,也从fork返回,返回值为0。
关键注意两点:
1.fork返回后,父进程或子进程的执行位置。(首先会将当前进程eax的值做为返回值)
2.两次返回的pid存放的位置。(eax中)
进程调用copy_process得到lastpid的值(放入eax中,fork正常返回后,父进程中返回的就是lastpid)
子进程任务状态段tss的eax被设置成0,
fork.c 中
p->tss.eax=0;(如果子进程要执行就需要进程切换,当发生切换时,子进程tss中的eax值就调入eax寄存器,子进程执行时首先会将eax的内容做为返回值)
当子进程开始执行时,copy_process返回eax的值。
fork()后,就是两个任务同时进行,父进程用他的tss,子进程用自己的tss,在切换时,各用各的eax中的值.
所以,“一次调用两次返回”是2个不同的进程!
看这一句:pid=fork()
当执行这一句时,当前进程进入fork()运行,此时,fork()内会用一段嵌入式汇编进行系统调用:int 0x80(具体代码可参见内核版本0.11的unistd.h文件的133行_syscall0函数)。这时进入内核根据此前写入eax的系统调用功能号便会运行sys_fork系统调用。接着,sys_fork中首先会调用C函数find_empty_process产生一个新的进程,然后会调用C函数 copy_process将父进程的内容复制给子进程,但是子进程tss中的eax值赋值为0(这也是为什么子进程中返回0的原因),当赋值完成后, copy_process会返回新进程(该子进程)的pid,这个值会被保存到eax中。这时子进程就产生了,此时子进程与父进程拥有相同的代码空间,程序指针寄存器eip指向相同的下一条指令地址,当fork正常返回调用其的父进程后,因为eax中的值是新创建的子进程号,所以,fork()返回子进程号,执行else(pid>0);当产生进程切换运行子进程时,首先会恢复子进程的运行环境即装入子进程的tss任务状态段,其中的eax 值(copy_process中置为0)也会被装入eax寄存器,所以,当子进程运行时,fork返回的是0执行if(pid==0)。
参考:
https://blog.csdn.net/jason314/article/details/5640969?utm_source=copy
http://blog.csdn.net/dog_in_yellow/archive/2008/01/13/2041079.aspx
http://blog.chinaunix.net/u1/53053/showart_425189.html
http://blog.csdn.net/saturnbj/archive/2009/06/19/4282639.aspx
http://www.cppblog.com/zhangxu/archive/2007/12/02/37640.html
http://www.qqread.com/linux/2010/03/y491043.html
http://www.yuanma.org/data/2009/1103/article_3998.htm
https://www.jb51.net/article/127400.htm
https://blog.csdn.net/xy010902100449/article/details/44851453
https://blog.csdn.net/shenwansangz/article/details/39184789
fork函数详解的更多相关文章
- Linux环境fork()函数详解
Linux环境fork()函数详解 引言 先来看一段代码吧, 1 #include <sys/types.h> 2 #include <unistd.h> 3 #include ...
- 【转】linux 中fork()函数详解
在看多线程的时候看到了这个函数,于是学习了下,下面文章写的通俗易懂,于是就开心的看完了,最后还是很愉快的算出了他最后一个问题. linux 中fork()函数详解 一.fork入门知识 一个进程,包括 ...
- Linux中fork()函数详解(转载)
linux中fork()函数详解 一.fork入门知识 一个进程,包括代码.数据和分配给进程的资源.fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事, ...
- Linux C 中 fork() 函数详解
一.fork入门知识 一个进程,包括代码.数据和分配给进程的资源.fork() 函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同 ...
- fork()函数详解
原文链接:http://blog.csdn.net/jason314/article/details/5640969 一.fork入门知识 一个进程,包括代码.数据和分配给进程的资源.fork()函 ...
- Linux中fork()函数详解(转)
一.fork入门知识 一个进程,包括代码.数据和分配给进程的资源.fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同, ...
- 【Linux 进程】fork函数详解
一.fork入门知识 一个进程,包括代码.数据和分配给进程的资源.fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同, ...
- linux中fork函数详解(转)
add by zhj: 在Linux,创建进程是用fork(),它其实就是拷贝父进程的数据段和其它数据,这相当于C函数调用中的值传递,这是 此后两者的修改都互不影响.因为两者的数据虽相同,但却在不同的 ...
- 知识点查缺补漏贴02:Linux环境fork()函数详解
引言 先来看一段代码吧, #include <sys/types.h> #include <unistd.h> #include <stdio.h> #includ ...
随机推荐
- Glide错误java.lang.IllegalArgumentException: You cannot start a load for a destroyed activity
解决办法 在使用Glide的那段代码加是否在主线程判断 if(Util.isOnMainThread()) { Glide.with(ClassifyItemDetailActivity.this). ...
- Tomcat学习(一)——使用Eclipse绑定Tomcat并发布应用
1.下载Tomcat 官网地址:http://tomcat.apache.org/whichversion.html 2.目录结构 bin:脚本目录 启动脚本:startup.bat 停止脚本:shu ...
- 读 Real-Time Rendering 收获 - chapter 6. texturing
Texturing, at its simplest, is a techinique for efficiently modeling the surface's properties.
- str 数据类型的用法
---------------------------------------------------------------------------------------------------- ...
- linux中对socket的理解 socket高并发
1.socket是什么? 其实准确的来说,socket并不仅仅用于linux而已,它也应用于TCP/IP中.笼统的来说,socket就是指的“IP地址+端口号”.比如我有一个ssh服务器A,这时候我有 ...
- MySQL数据类型及后面小括号的意义
1,数值类型 1.1数值类型的种类 标准 SQL 中的数值类型,包括严格数值类型(INTEGER.SMALLINT.DECIMAL.NUMERIC),以及近似数值数据类型(FLOAT.REAL.DOU ...
- 洛谷 P2738 [USACO4.1]篱笆回路Fence Loops
P2738 [USACO4.1]篱笆回路Fence Loops 题目描述 农夫布朗的牧场上的篱笆已经失去控制了.它们分成了1~200英尺长的线段.只有在线段的端点处才能连接两个线段,有时给定的一个端点 ...
- POJ 1741 Tree 树的分治(点分治)
题目大意:给出一颗无根树和每条边的权值,求出树上两个点之间距离<=k的点的对数. 思路:树的点分治.利用递归和求树的重心来解决这类问题.由于满足题意的点对一共仅仅有两种: 1.在以该节点的子树中 ...
- Cube Simulation zoj3429 模拟
Description Here's a cube whose size of its 3 dimensions are all infinite. Meanwhile, there're 6 pro ...
- iOS CST NSDate
好像是从ios4.1開始[NSDate date];获取的是GMT时间,这个时间和北京时间相差8个小时.下面代码能够解决问题 - (void)tDate { NSDate *date = [NSDat ...