Keras学习基础(2)
目录:
- Keras的模块结构
- 数据预处理
- 模型
- 网络层
- 网络配置
- Keras中的数据处理
- 文本预处理
- 序列预处理
- 图像预处理
- Keras中的模型
- Sequential顺序模型
- Model模型【通用模型】
- Keras中的Layers网络层
- 核心层
- 卷积层
- 池化层
- 循环层
- 嵌入层
- 合并层
- Keras中的网络配置
- 激活函数
- 初始化
- 正则化
- Keras模型保存和读取
- 保存
- 读取
一、Keras的模块结构
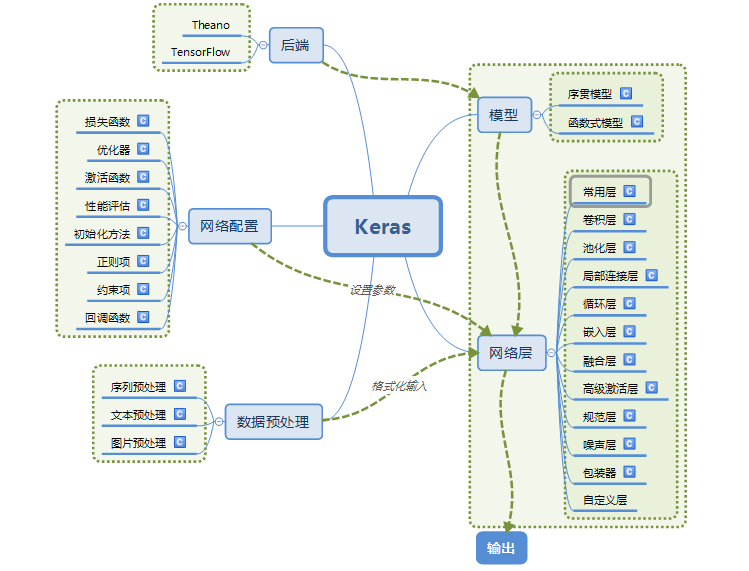
采用keras搭建一个神经网络:
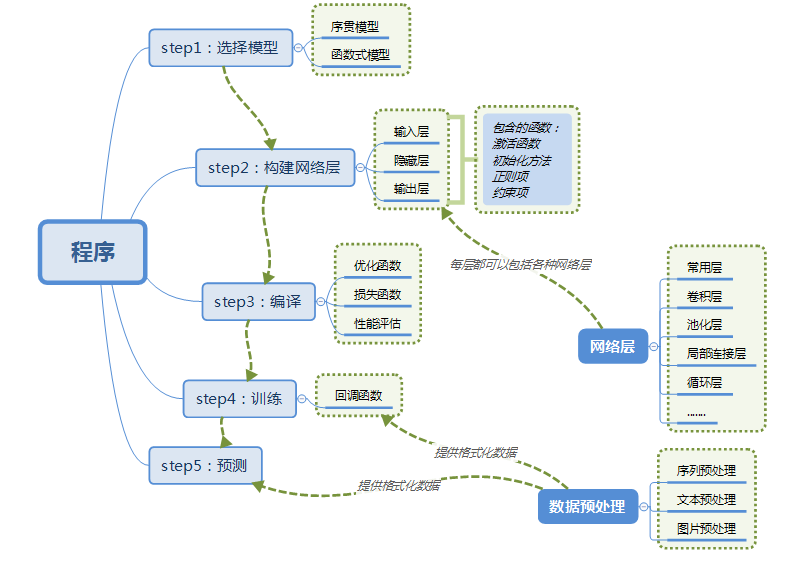
二、Keras的数据处理:
Keras提供的处理数据工具所有函数都在keras.preprocessing这个库中,分布有text、sequence和image三个子库。
1、文本预处理:keras.preprocessing.text【针对英文】
标注(Tokenize):在文本处理中,一般先将原始文本拆解成单字符、单词或者词组,然后将这些拆分后的要素进行索引、标记化供机器学习算法使用。几个步骤如下:
- 文字拆分(text_to_word_sequence)
- 建立索引(one_hot)
- 序列补齐(Padding)
- 转换成矩阵
- 使用标注类批量处理文本文件(Tokenizer)
(1)文字拆分:text_to_word_sequence函数
将一段文字根据预定义的分隔符(不能为空值)切分成字符串或单词(英文)。这个函数返回一个单词列表,但是会先处理一下,如去掉停止词或全转成小写字母等。如以下例子:
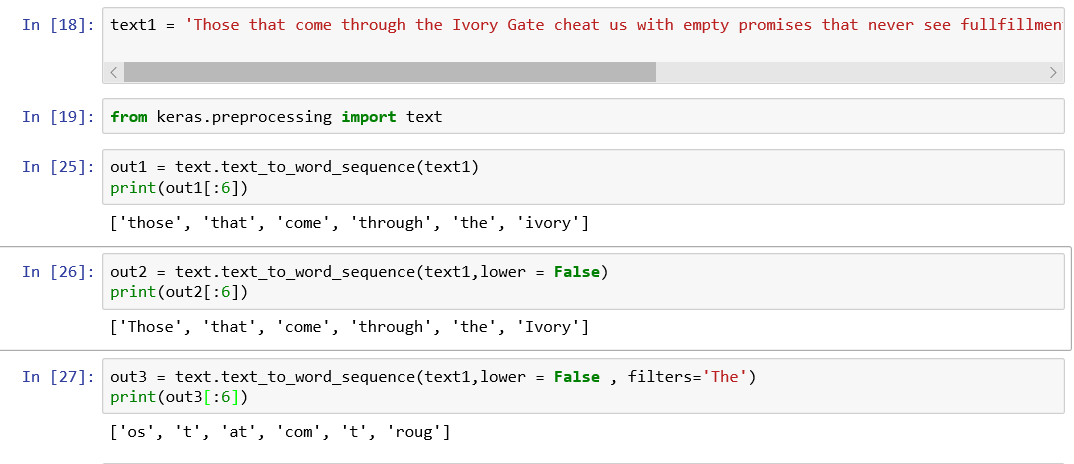
默认情况下,text_to_word_sequence函数使用引号作为分隔符,若在中文分词中,见到引号才分割,若filters = ‘。:’,这时分隔符发生了变化,这个函数使用过滤符号作为分隔符。故中文分词应该使用结巴分词。
(2)建立索引:sort + dict / one-hot编码
完成分词以后,得到的单词或字符不能直接用于建模,还需要将它们转换成数字序号,才能进行后续处理-----建立索引。
- 建立索引的方法1:对于拆分出来的每一个字符或单词,排序之后编号即可。
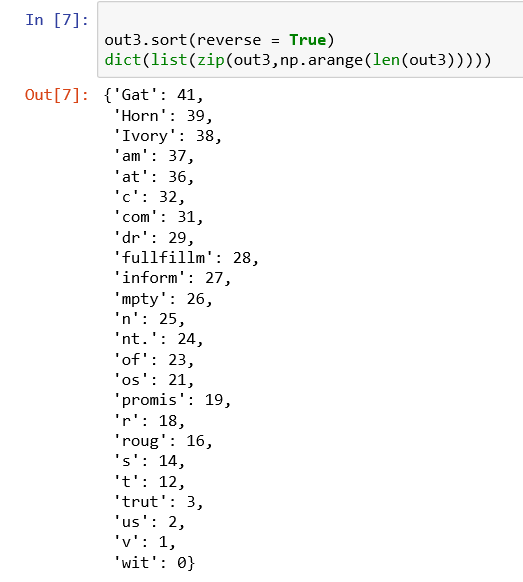
第一句sort将原字符串反向排序,第二句先通过zip命令将每个单词依次与序号配对,然后通过list将配对的数据转为列表,每个元素如('with',0)这样的一对,最后应用字典将列表转成字典完成索引。
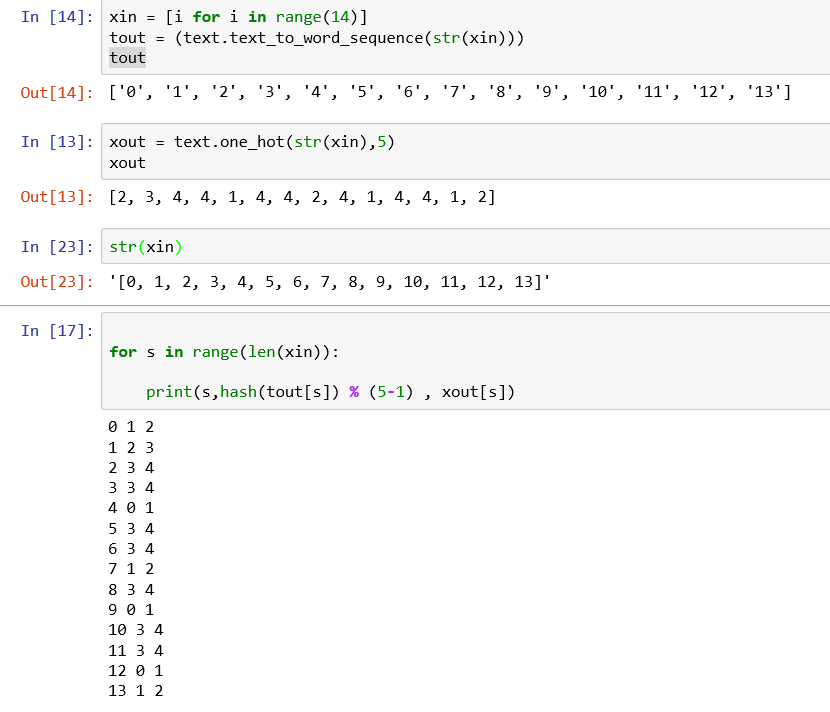
- 建立索引方法2:(one-hot编码)对于K个不同的字符或单词,依次设定一个1到K之间的数值来索引这K个字符或单词构成的词汇表。可采用one-hot函数来实现。
one-hot函数有两个参数:一个是待索引的字符串列表,一个是最大索引值n。这个函数将输入的字符串列表按照规则【hash函数】将其分配给0,……,n-1共n个索引值其中之一。
采用one-hot存在两种情况,如果 n< 不同字符的个数,则产生hash碰撞【即不同的字符串产生相同的hash值,one-hot编码相等】;如果n >= 不同字符的个数,可能产生稀疏。故采用one-hot建立索引都不理想。
one-hot源码解释如下:
(3)序列补齐:补充回上下文信息。pad_sequences函数
最终索引之后的文字信息会被按照索引编号放入多维矩阵中用来建模。这个多维矩阵的行宽对应于所有拆分后的字符或者单词,但是在将索引放入矩阵中之前,需要先进行序列补齐的工作。因为拆分之后,单词之间缺失了上下文信息。
序列补齐分两种情况:
第一种:将不同的长度的文本补齐成统一长度。
自然的文本序列,比如微博或者推特上的一段话,都是一个自然的字符或单词序列,而待建模的数据是由很多微博或者推特组成的,或者对一组文章进行建模,每篇文章的每一句话构成一个文本序列。此时每句话长度不一,需要进行补齐为统一长度。
第二种:将一段话移动固定窗口,即拆分为多个固定窗口的子串。
将一个由K个(K较大)具备一定顺序的单词串拆分成小块的连续子串,每个子串只有M个(M<K)单词。这种情况一般是一大段文字按照固定长度移动一个窗口,将窗口内的单词索引载入多维矩阵的每一行,因此一句话可能会对应于矩阵的多行数据,形成时间步(timestep)。
序列补齐可以使用pad_sequences函数,其输入要素是列表串(list of list)。假设有一个列表串,包含了单词的索引号,下面代码展示了在不同设置选项下使用这个函数如何补齐序列。

padding选项指定是从后面补齐还是前面补齐,
补齐的索引数字默认为0,不过可以通过value选项修改。
如果不用maxlen选项设定补齐序列的长度,则按照最长列表元素的长度来设定。如果设定的补齐序列的长度小于一些列表元素的长度,那么会产生截断。截断的标准是假如补齐序列的长度为k,则保留最后k个索引值。
(4)转换为矩阵
所有的建模都只能使用多维矩阵,因此最后必须将索引过的文字元素转换成可以用于建模的矩阵。keras提供了两种方法。
第一种:使用pad_sequences函数。该函数可建立相应的矩阵。
第二种:使用下面要介绍的标注类来进行。因为一般要将文字转换为矩阵的情况多对应多个不同的文本(比如不同的小说),或者同一个文本的不同段落(比如同一个小说的不同章节等)。因此对应大量元素的列表串。
(5)使用标注类批量处理文本文件:Tokenizer class
当批量处理文本文件时,需要一种更高效的方法。keras提供了一个标注类(Tokenizer class)来进行文本处理。当批量处理文本文件时,一般所有文本会被读入一个大的列表中,每一个元素是单个文件的文本或者一大段文本。
上面的方法针对单一字符串设计的,标注类的方法是针对一个文本列表设计的。
Tokenizer class对应的操作数据有两种类型,分别是文本列表和单词串列表,对应的方法包含“text"或者”sequences"字样,对应于文本列表的方法都是将文本拆分成单词串以后执行相应的操作。
假设已经通过open(file).read()函数将一系列文本文件读入alltext这个列表变量中,每一个元素是一个文本文件中的文本。在进行所有预处理之前,先初始化标注对象:
from keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer(nb_words = 1000)
tokenizer.fit_on_texts(alltext)
fit_on_texts()函数的作用是对于输入的文本计算一些关键统计量,并对里面的元素进行索引。
- 首先,依次遍历文本列表变量元素,对于每 一个字符串元素,使用上面提到的 text_to_word_sequence函数进行拆分,并统一 为小写字符。
- 其次,计算单词出现的总频率和在不同文件 中分别出现的频率,并对单词表排序。
- 最后,计算总的单词量,并对每一个单词建 立一个总的索引和一个在不同文件中的索引。
完成上述准备工作之后,就可以对整个列表 中的元素进行拆分了。
word_sequences = tokenizer.texts_to_sequences(alltext)
将每一个文本字符串拆分成单词以后,还需要对每个字符串做序列补齐的工作,才能将其最 终转换为可用于建模的矩阵。这时就要用到上面 提到的pad_sequences函数,其用法一样:
padded_word_sequences = pad_sequences(word_sequences,maxlen = MAX_sequence_length)
在标注类中有两个方法是用来将文本序列列 表转换为待建模矩阵的,即text_to_matrix和 sequence_to_matrix。其中text_to_matrix基于后 者,对从文本序列列表中抽取的每一个序列元素 应用sequence_to_matrix转换为矩阵。
2、序列数据预处理:TimeseriesGenerator
keras.preprocessing.sequence.TimeseriesGenerator(data, targets, length, sampling_rate=1, stride=1, start_index=0, end_index=None, shuffle=False, reverse=False, batch_size=128)
- TimeseriesGenerator用来生成批量时序数据,这个类以一系列相等间隔以及一些时间序列参数(如步长、历史长度等)汇集的数据点作为输入,以生成用于训练/验证的批次数据。
- pad_sequences:将多个序列截断或补齐为相同长度。
- skipgrams:生成skipgram词对。
- make_sampling_table:生成一个基于单词的概率采样表。
TimeseriesGenerator例子:
from keras.preprocessing.sequence import TimeseriesGenerator
import numpy as np data = np.array([[i] for i in range(50)])
targets = np.array([[i] for i in range(50)]) data_gen = TimeseriesGenerator(data, targets,
length=10, sampling_rate=2,
batch_size=2)
assert len(data_gen) == 20 batch_0 = data_gen[0]
x, y = batch_0
assert np.array_equal(x,
np.array([[[0], [2], [4], [6], [8]],
[[1], [3], [5], [7], [9]]]))
assert np.array_equal(y,
np.array([[10], [11]]))
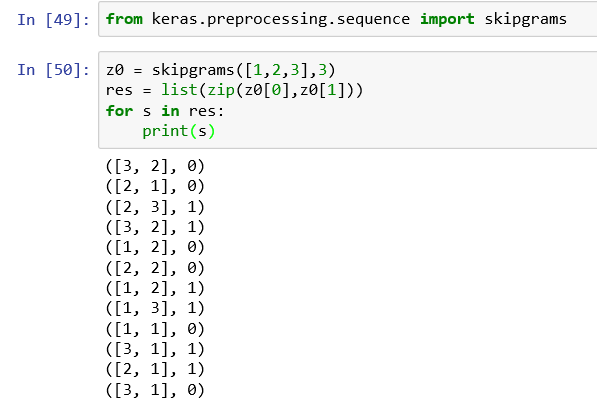
skipgrams例子:skipgrams函数将一个词向量索引标号按照 两种可选方式转化为一系列两两元素的组合 (w1,w2)和标注z。如果w2跟w1是紧挨着 的,则标注z为1,为正样本;如果w2是从不相邻 的其他元素中随机抽取的,则标注z为负样本。
3、图片数据处理:
Keras为图片数据的输入提供了一个很好的接 口,即 Keras.preprocessing.image.ImageDataGenerator类。 这个类生成一个数据生成器(Generator)对象, 依照循环批量产生对应于图像信息的多维矩阵。 根据后台运行环境的不同,比如是TensorFlow还 是Theano,多维矩阵的不同维度对应的信息分别 是图像二维的像素点,第三维对应于色彩通道, 因此如果是灰度图像,那么色彩通道只有一个维度;如果是RGB色彩,那么色彩通道有三个维 度。
三、keras的模型:
Keras中包含了两种定义模型的方法:Sequential模型和Model模型。
1、Sequential模型:
这种模型各层之间是依次顺序的线性关系,在第k层和第k+1层之间可以加上各种元素来构造神经网络。这些元素可以通过一个列表来指定,然后作为参数传递给序列模型来生成相应的模型。如以下代码:
from keras.models import Sequential
from keras.layers import Dense,Activation
layers = [ Dense ( 32 , input_shape = (784,)) ,
Activation('relu'),
Dense(10),
Activation('softmax') ] model = Sequential(layers)
除了一开始直接在一个列表中指定所有元素外,也可以像下面这个例子一样逐层添加:
from keras.models import Sequential
from keras.layers import Dense , Activation model = Sequential() model.add(Dense(32,input_shape = (784,))) model.add(Activation('relu') model.add(Dense(10)) model.add(Activation('softmax')
2、Model模型
Model模型可以用来设计非常复杂、任意拓扑结构的神经网络,例如有向无环网络、共享层网络等。类似于序列模型,Model模型通过函数化的应用接口来定义模型。使用函数化的应用接口有多个好处,比如:决定函数执行结果的唯一要素是其返回值,而决定返回值的唯一要素则是其参数,减轻了代码测试的工作量。
案例1----全连接神经网络拟合MNIST的分类模型,输入数据是28*28的图像、
from keras.layers import Input, Dense
from keras.models import Model # 定义输入层input,每一个图像拉成784个像素点的向量
inputs = Input(shape=(784,)) #定义各个连接层,包括激活函数,假设从输入层开始,定义两个隐含层,都有64个神经元
x = Dense(64, activation='relu')(inputs)
x = Dense(64, activation='relu')(x) #定义输出层
y = Dense(10, activation='softmax')(x) #定义模型对象
model = Model(input=inputs, output=y) #编译,对数据进行拟合
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(data, labels) # starts
案例2----双输入、双输出:LSTM时序预测
输入:
新闻语料;新闻语料对应的时间
输出:
新闻语料的预测模型;新闻语料+对应时间的预测模型
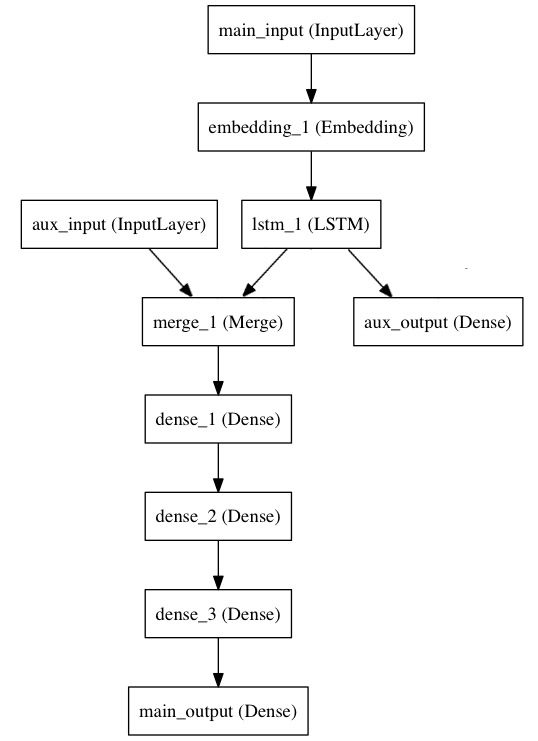
代码:
from keras.layers import Input, Embedding, LSTM, Dense
from keras.models import Model # 标题输入:接收一个含有 100 个整数的序列,每个整数在 1 到 10000 之间。
# 注意我们可以通过传递一个 `name` 参数来命名任何层。
main_input = Input(shape=(100,), dtype='int32', name='main_input') # Embedding 层将输入序列编码为一个稠密向量的序列,每个向量维度为 512。
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input) # LSTM 层把向量序列转换成单个向量,它包含整个序列的上下文信息
lstm_out = LSTM(32)(x) auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out) auxiliary_input = Input(shape=(5,), name='aux_input')
x = keras.layers.concatenate([lstm_out, auxiliary_input]) # 堆叠多个全连接网络层
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x) # 最后添加主要的逻辑回归层
main_output = Dense(1, activation='sigmoid', name='main_output')(x) #定义一个具有双输入和双输出的模型
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output]) #编译模型,给辅助损失分配一个 0.2 的权重
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
loss_weights=[1., 0.2]) model.fit([headline_data, additional_data], [labels, labels],
epochs=50, batch_size=32
案例3-----共享层:函数式模型 的另一个用途是使用共享网络层的模型。


Sequential模型和Model模型主要差异在于如何定义从输入层到输出层的各层结构。
- Sequential模型是先定义序列模型对象,而Model模型先定义输入层到输出层各层要素的,包括尺寸结构。
- Sequential模型可通过add对模型对象依次添加各层信息,Model模型通过不停地封装含有各层网络结构的函数作为参数来定义网络结构的。
- Sequential模型各层只能依次线性添加,而model模型可在原有的网络结构上应用新的结构来快速生成新的模型
两个模型有很多共同的方法和属性:
https://keras.io/zh/models/about-keras-models/

四、Keras中的Layers网络层
在Keras中,定义神经网络的具体结构是通过组织不同的网络层(Layer) 来实现的。
1、核心层
核心层(Core Layer)是构成神经网络最常 用的网络层的集合,包括:全连接层、激活层、
放弃层、扁平化层、重构层、排列层、向量反复 层、Lambda层、激活值正则化层、掩盖层。所有 的层都包含一个输入端和一个输出端,中间包含 激活函数以及其他相关参数等。
(1)全连接层。【Dense】在神经网络中最常见的网 络层就是全连接层,在这个层中实现对神经网络
里面的神经元的激活。比如:y=g(x′w+b),其 中w是该层的权重向量,b是偏置项,g()是激 活函数。如果use_bias选项设置为False,那么偏
置项为0。常见的引用全连接层的语句如下:
model.add(Dense(32,activation = 'relu', use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', activity_regularizer=regularizers.l1_l2(0.2,0.5)))
- 32,表示向下一层输出向量的维度
- activation='relu',表示使用relu函数作为对应 神经元的激活函数
- kernel_initializer='uniform',表示使用均匀分 布来初始化权重向量,类似的选项也可以用 在偏置项上。读者可以参考前面的“初始化 对象”部分的介绍。
- activity_regularizer=regularizers.l1_l2(0.2, 0.5),表示使用弹性网作为正则项,其中一 阶的正则化参数为0.2,二阶的正则化参数为 0.5。
(2)激活层。【activation】激活层是对上一层的输出应 用激活函数的网络层,这是除应用activation选项之外,另一种指定激活函数的方式。其用法很简单,只要在参数中指明所需的激活函数即可,预 先定义好的函数直接引用其名字的字符串,或者 使用TensorFlow和Theano自带的激活函数。如果这是整个网络的第一层,则需要用input_shape指定输入向量的维度。
(3)放弃层。【Dropout】放弃层(Dropout)是对该层 的输入向量应用放弃策略。在模型训练更新参数的步骤中,网络的某些隐含层节点按照一定比例 随机设置为不更新状态,但是权重仍然保留,从 而防止过度拟合。这个比例通过参数rate设定为0 到1之间的实数。在模型训练时不更新这些节点的参数,因此这些节点并不属于当时的网络;但是保留其权重,因此在以后的迭代次序中可能会 影响网络,在打分的过程中也会产生影响,所以 这个放弃策略通过不同的参数估计值已经相对固 化在模型中了。
(4)扁平化层。【Flatten】扁化层(Flatten)是将一个 维度大于或等于3的高维矩阵按照设定“压扁”为 一个二维的低维矩阵。其压缩方法是保留第一个 维度的大小,然后将所有剩下的数据压缩到第二 个维度中,因此第二个维度的大小是原矩阵第二 个维度之后所有维度大小的乘积。这里第一个维 度通常是每次迭代所需的小批量样本数量,而压 缩后的第二个维度就是表达原图像所需的向量长 度。
比如输入矩阵的维度为(1000,64,32, 32),扁平化之后的维度为(1000,65536),
其中65536=64×32×32。如果输入矩阵的维度为 (None,64,32,32),则扁平化之后的维度为(None,65536)。
(5)重构层。【Reshape】重构层(Reshape)的功能和Numpy的Reshape方法一样,将一定维度的多维矩 阵重新排列构造为一个新的保持同样元素数量但 是不同维度尺寸的矩阵。其参数为一个元组(tuple),指定输出向量的维度尺寸,最终的向 量输出维度的第一个维度的尺寸是数据批量的大 小,从第二个维度开始指定输出向量的维度大小。
比如可以把一个有16个元素的输入向量重构 为一个(None,4,4)的新二维矩阵:最后的输出向量不是(4,4),而是 (None,4,4)。
from keras.layers import Reshape
model = Sequential()
model.add(Reshape((4,4),input_shape = (16,)))
(6)排列层。排列层(Permute)按照给定 的模式来排列输入向量的维度。这个方法在连接
卷积网络和时间递归网络的时候非常有用。其参 数是输入矩阵的维度编号在输出矩阵中的位置。 比如:
from keras.layers import Permute
model = Sequential()
model.add(Permute((2, 1), input_shape=(10, 64)))
# 现在: model.output_shape == (None, 64, 10)
# 注意: `None` 是批表示的维度
将输入向量的第一维和第二维的数据进行交换后输出, 这个例子使用了input_shape参数,它一般在第一 层网络中使用,在接下来的网络层中,Keras能自己分辨输入矩阵的维度大小。
(7)向量反复层。【RepeatVector】向量反复层 就是将输入矩阵重复多次。比如下面这个例子:
输入尺寸:2D 张量,尺寸为 (num_samples, features)。
输出尺寸:3D 张量,尺寸为 (num_samples, n, features)。
from keras.layers import RepeatVector
model = Sequential()
model.add(Dense(32, input_dim=32))
# 现在: model.output_shape == (None, 32)
# 注意: `None` 是批表示的维度 model.add(RepeatVector(3))
# 现在: model.output_shape == (None, 3, 32)
(8)Lambda层。Lambda层可以将任意表达 式包装成一个网络层对象。参数就是表达式,一 般是一个函数,可以是一个自定义函数,也可以 是任意已有的函数。如果使用Theano和自定义函 数,可能还需要定义输出矩阵的维度。如果后台 使用CNTK或TensorFlow,可以自动探测输出矩阵的维度。比如:
from keras.layers import Lambda
model.add(Lambda(lambda x:x**2))
(9)激活值正则化层。ActivityRegularization,这个网络层的作用 是对输入的损失函数更新正则化
(10)掩盖层。Masking,该网络层主要使用在跟时间 有关的模型中,比如LSTM。其作用是输入张量 的时间步,在给定位置使用指定的数值进行“屏蔽”,用以定位需要跳过的时间步。输入张量的时间步一般是输入张量的第1维度(维度从0开始算,见例子),如果输入张量 在该时间步上等于指定数值,则该时间步对应的 数据将在模型接下来的所有支持屏蔽的网络层被 跳过,即被屏蔽。如果模型接下来的一些层不支 持屏蔽,却接收到屏蔽过的数据,则抛出异常。
model = Sequential()
model.add(Masking(mask_value=0., input_shape=(timesteps, features)))
model.add(LSTM(32))
如果输入张量X[batch,timestep,data]对应 于timestep=5,7的数值是0,即X[:,[5,7],:]=0,那么上面的代码指定需要屏蔽的对象 是所有数据为0的时间步,然后接下来的长短记 忆网络在遇到时间步为5和7的0值数据时都会将 其忽略掉。
2、卷积层:
Conv1D、Conv2D和Conv3D的选项几乎相同。
3、池化层:
(1)最大统计量池化方法:MaxPooling1D、MaxPooling2D、MaxPooling3D
(2)平均统计量池化方法:AveragePooling1D、AveragePooling2D和 AveragePooling3D。
(3)全局池化方法:一维池化:GlobalMaxPooling1D和 GlobalAveragePooling1D。二维池化:GlobalMaxPooling2D和 GlobalAveragePooling2D。
4、循环层:
(1)简单循环层:recurrent.SimipleRNN
(2)长短记忆层:LSTM
(3)带记忆门的循环层(GRU)。
5、嵌入层:
嵌入层(Embedding Layer)是使用在模型第 一层的一个网络层,其目的是将所有索引标号映 射到致密的低维向量中,比如[[4],[32],[67]]→[[0.3,0.9,0.2],[-0.2,0.1,0.8],[0.1, 0.3,0.9]]就是将一组索引标号映射到一个三维的 致密向量中,通常用在对文本数据进行建模的时 候。输入数据要求是一个二维张量:(批量数, 序列长度),输出数据为一个三维张量:(批量 数,序列长度,致密向量的维度)。
6、合并层:
合并层是指将多个网络产生的张量通过一定 方法合并在一起,可以参看下一节中的奇异值分 解的例子。合并层支持不同的合并方法,包括: 元素相加(merge.Add)、元素相乘(merge.Multiply)、元素取平均 (merge.Average)、元素取最大 (merge.Maximum)、叠加(merge.Concatenate)、矩阵相乘 (merge.Dot)。
其中,元素相加、元素相乘、元素取平均、 元素取最大方法要求进行合并的张量的维度大小 完全一致。叠加方法要求指定按照哪个维度(axis)进行叠加,除了叠加的维度,其他维度 的大小必须一致。矩阵相乘方法是对两个张量采 用矩阵乘法的形式来合并,因为张量是高维矩 阵,因此需要指定沿着哪个维度(axis)进行乘 法操作。同时可以指定是否标准化 (Normalize),如果是的话 (Normalize=True),则先将两个张量归一化以 后再相乘,这时得到的是余弦相似度。
来自于MIT Technology Review的图很好地解释了合并层:

五、keras的网络配置
1、激活函数
在Keras中使 用激活对象有两种方法:一是单独定义一个激活 层;二是在前置层里面通过激活选项来定义所需 的激活函数。比如,下面两段代码是等效的,前 一段是通过激活层来使用激活对象的;后一段是 使用前置层的激活选项来使用激活对象的。
model.add(Dense(64,input_shape(784,)))
model.add(Activation('tanh')) model.add(Dense(64,input_shape = (784,),activation = 'tanh'))
- tanh
- softmax
- softsign
- softplus
- elu
- relu
- sigmoid
- hard_sigmoid
- linear
2、初始化:
初始化对象(Initializer)用于随机设定网络 层激活函数中的权重值或者偏置项的初始值,包 括kernel_initializer和bias_initializer。好的权重初 始化值能帮助加快模型收敛速度。Keras预先定义
了很多不同的初始化对象,包括:
- Zeros,将所有参数值都初始化为0。
- Ones,将所有参数值都初始化为1。
- Constant(value=1),将所有参数值都初始 化为某一个常量,比如这里设置为1。
- RandomNormal,将所有参数值都按照一个正 态分布所生成的随机数来初始化。正态分布 的均值默认为0,而标准差默认为0.05。可以 通过mean和stddev选项来修改。
- TruncatedNormal,使用一个截断正态分布生 成的随机数来初始化参数向量,默认参数均 值为0,标准差为0.05。对于均值的两个标准 差之外的随机数会被遗弃并重新取样。这种 初始化方法既有一定的多样性,又不会产生 特别偏的值,因此是比较推荐的方法。针对 不同的常用分布选项,Keras还提供了两个基于这种方法的特例,即glorot_normal和 he_normal。前者的标准差不再是0.05,而是 输入向量和输出向量的维度的函数:stddev = √(2/(n1+n2)),其中n1是输入向量的维 度,而n2是输出向量的维度;后者的标准差只是输入向量的维度的函数:stddev = √(2/n1)
- RandomUniform,按照均匀分布所生成的随 机数来初始化参数值,默认的分布参数最小 值为-0.05,最大值为0.05,可以通过minval 和maxval选项分别修改。针对常用的分布选 项,Keras还提供了两个基于这个分布的特例 即glorot_uniform和he_uniform。前者均匀分布 的上下限是输入向量和输出向量的维度的函 数:minval / maxval = -/ + √(6/(n1+n2))。 而在后者 上下限只是输入向量的维度的函数:minval / maxval = -/ + √(6/n1)
- 自定义,用户可以自定义一个与参数维度相 符合的初始化函数。下面的例子来自于Keras 手册,使用后台的正态分布函数生成一组初 始值,在定义网络层的时候调用这个函数即可。
from keras import backend as k
from keras.models import Sequential
from keras.layers import Dense , Activation def my_init(shape , dtype = None):
return k.random_normal(shape,dtype = dtype)
model = Sequential()
model.add(Dense(64,kernel_initializer = my_init))
3、正则化
在神经网络中提供了正则化的手段,分别应用于权重参数、偏置项以及激活函数,对应的选项分别是kernel_regularizer、bias_reuglarizier和activity_regularizer。它们都可以应用Keras.regularizier.Regularizer对象,这个对象提供了定义好的一阶、二阶和混合的正则化方法,分别将前面的Regularizier替换为l1(x)、 l2(x)和l1_l2(x1,x2),其中x或者x1,x2为 非负实数,表明正则化的权重。
自定义权重矩阵的正则项,接受权重矩阵为参数,并且输出单个数值即可。
from keras import backend as K
from keras.models import Sequential
from keras.layers import Dense , Activation model = Sequential()
def l1_reg(weight_matrix):
return 0.01 * K.sum(K.abs(weight_matrix)) model.add(Dense(64, input_dim=64,
kernel_regularizer=l1_reg))
在这个例子中,用户自己定义了一个比例为 0.01的一阶正则化项,返回的单个数值是权重参 数的绝对值的和,乘以0.01这个比例,其用法跟 预先提供的regularizier.l1(x)对象是一样的。
六、模型的保存和读取:keras中的模型主要包括model结构和weight两个部分。
- 读取模型需要导入的包:from keras.models import load_model
- 保存和读取整个模型【包括model结构和参数】:
model.save('my_model.h5') #取个名字,h5是保存的格式,需要安装HDF5模块,pip install h5py
model = load_model(’my_model.h5') #读取模型
- 仅保存和读取权重参数【不保存model结构】:
model.save_weights('my_model_weights.h5') #保存
model.load_weights('my_model_weights.h5') #读取
- 仅保存和读取模型的结构【不保存权重参数】:
from keras.models import model_from_json
#保存模型
- 删除已经存在模型:
del model
- 迁移学习时只想加载某些权重参数,可以通过层名字来加载模型:
model.load_weights('my_model_weights.h5', by_name=True)
参考:
Keras快速上手:基于Python的深度学习实战
Keras中文手册
Keras学习基础(2)的更多相关文章
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 【干货】Keras学习资源汇总
目录: Keras简介 Keras学习手册 Keras学习视频 Keras代码案例 Keras&NLP Keras&CV Keras项目 一.Keras简介 Keras是Python中 ...
- 现代3D图形编程学习-基础简介(2) (译)
本书系列 现代3D图形编程学习 基础简介(2) 图形和渲染 接下去的内容对渲染的过程进行粗略介绍.遇到的部分内容不是很明白也没有关系,在接下去的章节中,会被具体阐述. 你在电脑屏幕上看到的任何东西,包 ...
- 现代3D图形编程学习-基础简介(1) (译)
本书系列 现代3D图形编程学习 基础简介 并不像本书的其他章节,这章内容没有相关的源代码或是项目.本章,我们将讨论向量,图形渲染理论,以及OpenGL. 向量 在阅读这本书的时候,你需要熟悉代数和几何 ...
- JavaScript学习基础部分
JavaScript学习基础 一.简介 1.JavaScript 是因特网上最流行的脚本语言,并且可在所有主要的浏览器中运行,比方说 Internet Explorer. Mozilla.Firefo ...
- (转) 基于Theano的深度学习(Deep Learning)框架Keras学习随笔-01-FAQ
特别棒的一篇文章,仍不住转一下,留着以后需要时阅读 基于Theano的深度学习(Deep Learning)框架Keras学习随笔-01-FAQ
- 【IOS学习基础】NSObject.h学习
一.<NSObject>协议和代理模式 1.在NSObject.h头文件中,我们可以看到 // NSObject类是默认遵守<NSObject>协议的 @interface N ...
- git学习基础教程
分享一个git学习基础教程 http://pan.baidu.com/s/1o6ugkGE 具体在网盘里面的内容..需要的学习可以直接下.
随机推荐
- HTMLParser in python
You can know form the name that the HTMLParser is something used to parse HTML files. In python, th ...
- c/c++ 数据结构之位图(bitmap)具体解释
1. 概述 位图(bitmap)是一种很经常使用的结构,在索引.数据压缩等方面有广泛应用. 本文介绍了位图的实现方法及其应用场景. 2. 位图实现 2014728101320" alt=& ...
- 小米手机 js 脚本取src为空的适配问题
今天測试提上来一个问题 我android webview 中运行了一段js脚本.去替换原来的图片.可是小米手机上竟然没起作用 花了一个中午的午休看问题 贴出来帮助下遇到相同的问题的朋友吧.我百度了半天 ...
- 体验决定销量,真假4K争论仅仅是忽悠人而已
随着4K电视越来越多.网上关于真假4K电视的争论也越来越激烈,RGB与RGBW的死掐也进入了白热化阶段.从某种意义上讲.真假4K话题是4K电视市场竞争加剧的必定结果.并且这场争论已经严重影响了 ...
- hdu 4768 异或运算
http://acm.hdu.edu.cn/showproblem.php?pid=4768 貌似非常多人是用的二分 可是更好的做法貌似还是异或 对于第k个人.假设他接到偶数个传单.那么异或的结果还是 ...
- storm 并行度
1个worker进程运行的是1个topology的子集(注:不会出现1个worker为多个topology服务).1个worker进程会启动1个或多个executor线程来运行1个topology的c ...
- Android 系统开机logo的修改【转】
本文转载自:http://blog.csdn.net/yandongqiangZHRJ/article/details/8585273 看到了好几个修改logo的博文,但是说的不是很清楚,在这里亲手送 ...
- XHprof 使用 (转)
原文地址:http://blog.csdn.net/maitiandaozi/article/details/8896293 XHProf是facebook开源出来的一个php轻量级的性能分析工具,跟 ...
- (Go)10.流程控制示例
package main import ( "math/rand" "fmt" ) func main() { //var n int n := rand.In ...
- centos7用rpm安装mysql5.7【初始用yum安装发现下载非常慢,就考虑本地用迅雷下载rpm方式安装】
1.下载 4个rpm包 mysql-community-client-5.7.26-1.el7.x86_64.rpmmysql-community-common-5.7.26-1.el7.x86_64 ...