Self-Taught Learning
the promise of self-taught learning and unsupervised feature learning is that if we can get our algorithms to learn from unlabeled data, then we can easily obtain and learn from massive amounts of it.Even though a single unlabeled example is less informative than a single labeled example, if we can get tons of the former---for example, by downloading random unlabeled images/audio clips/text documents off the internet---and if our algorithms can exploit this unlabeled data effectively, then we might be able to achieve better performance than the massive hand-engineering and massive hand-labeling approaches.
Learning features
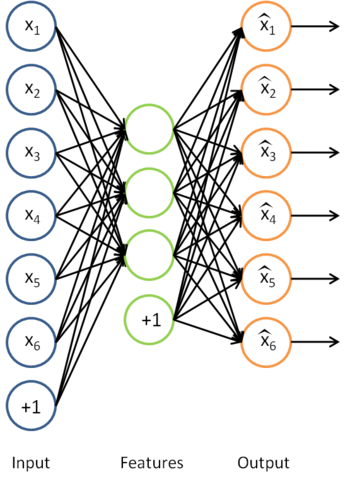
We have already seen how an autoencoder can be used to learn features from unlabeled data. Concretely, suppose we have an unlabeled training set
with
unlabeled examples. (The subscript "u" stands for "unlabeled.") We can then train a sparse autoencoder on this data (perhaps with appropriate whitening or other pre-processing):
Having trained the parameters
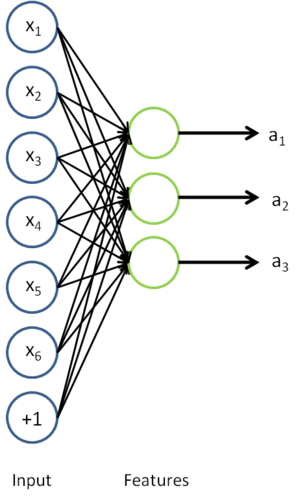
of this model, given any new input
, we can now compute the corresponding vector of activations
of the hidden units. As we saw previously, this often gives a better representation of the input than the original raw input
This is just the sparse autoencoder that we previously had, with with the final layer removed.
Now, suppose we have a labeled training set
of
examples. (The subscript "l" stands for "labeled.") We can now find a better representation for the inputs. In particular, rather than representing the first training example as
, we can feed
. To represent this example, we can either just replace the original feature vector with
.
Thus, our training set now becomes
(if we use the replacement representation, and use
to represent the
-th training example), or
(if we use the concatenated representation). In practice, the concatenated representation often works better; but for memory or computation representations, we will sometimes use the replacement representation as well.
Finally, we can train a supervised learning algorithm such as an SVM, logistic regression, etc. to obtain a function that makes predictions on the
values. Given a test example
, we would then follow the same procedure: For feed it to the autoencoder to get
. Then, feed either
to the trained classifier to get a prediction.
On pre-processing the data
During the feature learning stage where we were learning from the unlabeled training set
to represent the data as
(or used PCA whitening or ZCA whitening). If this is the case, then it is important to save away these preprocessing parameters, and to use the same parameters during the labeled training phase and the test phase, so as to make sure we are always transforming the data the same way to feed into the autoencoder. In particular, if we have computed a matrix
On the terminology of unsupervised feature learning
There are two common unsupervised feature learning settings, depending on what type of unlabeled data you have. The more general and powerful setting is the self-taught learning setting, which does not assume that your unlabeled data xu has to be drawn from the same distribution as your labeled data xl. The more restrictive setting where the unlabeled data comes from exactly the same distribution as the labeled data is sometimes called the semi-supervised learning setting. This distinctions is best explained with an example, which we now give.
Suppose your goal is a computer vision task where you'd like to distinguish between images of cars and images of motorcycles; so, each labeled example in your training set is either an image of a car or an image of a motorcycle. Where can we get lots of unlabeled data? The easiest way would be to obtain some random collection of images, perhaps downloaded off the internet. We could then train the autoencoder on this large collection of images, and obtain useful features from them. Because here the unlabeled data is drawn from a different distribution than the labeled data (i.e., perhaps some of our unlabeled images may contain cars/motorcycles, but not every image downloaded is either a car or a motorcycle), we call this self-taught learning.
In contrast, if we happen to have lots of unlabeled images lying around that are all images of either a car or a motorcycle, but where the data is just missing its label (so you don't know which ones are cars, and which ones are motorcycles), then we could use this form of unlabeled data to learn the features. This setting---where each unlabeled example is drawn from the same distribution as your labeled examples---is sometimes called the semi-supervised setting. In practice, we often do not have this sort of unlabeled data (where would you get a database of images where every image is either a car or a motorcycle, but just missing its label?), and so in the context of learning features from unlabeled data, the self-taught learning setting is more broadly applicable.
自学习 VS 半监督学习
半监督学习假设,未标记数据和已标记数据拥有相同的数据分布
Self-Taught Learning的更多相关文章
- 一个Self Taught Learning的简单例子
idea: Concretely, for each example in the the labeled training dataset xl, we forward propagate the ...
- The Brain vs Deep Learning Part I: Computational Complexity — Or Why the Singularity Is Nowhere Near
The Brain vs Deep Learning Part I: Computational Complexity — Or Why the Singularity Is Nowhere Near ...
- What is machine learning?
What is machine learning? One area of technology that is helping improve the services that we use on ...
- How do I learn machine learning?
https://www.quora.com/How-do-I-learn-machine-learning-1?redirected_qid=6578644 How Can I Learn X? ...
- (转) Ensemble Methods for Deep Learning Neural Networks to Reduce Variance and Improve Performance
Ensemble Methods for Deep Learning Neural Networks to Reduce Variance and Improve Performance 2018-1 ...
- A Brief Overview of Deep Learning
A Brief Overview of Deep Learning (This is a guest post by Ilya Sutskever on the intuition behind de ...
- 5 Techniques To Understand Machine Learning Algorithms Without the Background in Mathematics
5 Techniques To Understand Machine Learning Algorithms Without the Background in Mathematics Where d ...
- 深度学习Deep learning
In the last chapter we learned that deep neural networks are often much harder to train than shallow ...
- 【转】The most comprehensive Data Science learning plan for 2017
I joined Analytics Vidhya as an intern last summer. I had no clue what was in store for me. I had be ...
- Neural Networks and Deep Learning
Neural Networks and Deep Learning This is the first course of the deep learning specialization at Co ...
随机推荐
- poj2823/hdu3415 - 数据结构 单调队列
poj2823 题目链接 长度为N的数组,求宽度k的滑动窗口在数组上滑动时窗口内的最大值或最小值 如果用单调队列做,求最小值时,队列应该严格递增的.所以插入时,队尾大于等于插入值的元素都应被舍弃,因为 ...
- UI Framework-1: Aura Gesture Recognizer
Gesture Recognizer Gesture Recognizer Overview This document describes the process by which Touch Ev ...
- ES6学习笔记(十九)Module 的语法-export和import
1.概述 历史上,JavaScript 一直没有模块(module)体系,无法将一个大程序拆分成互相依赖的小文件,再用简单的方法拼装起来.其他语言都有这项功能,比如 Ruby 的require.Pyt ...
- unity C# 获取有关文件、文件夹和驱动器的信息
class FileSysInfo { static void Main() { // You can also use System.Environment.GetLogicalDrives to ...
- Java基础学习总结(14)——Java对象的序列化和反序列化
一.序列化和反序列化的概念 把对象转换为字节序列的过程称为对象的序列化. 把字节序列恢复为对象的过程称为对象的反序列化. 对象的序列化主要有两种用途: 1) 把对象的字节序列永久地保存到硬盘上,通常存 ...
- android 选取部分 log 的两种方法
Grep多个条件: android logcat -v time | grep -e A -e B 选取多个android log tag: android logcat -v time -s TAG ...
- html5缓存
HTML5 提供了两种在client存储数据的新方法: localStorage - 没有时间限制的数据存储 sessionStorage - 针对一个 session 的数据存储 这些都是由 coo ...
- UVA 10515 - Powers Et Al.(数论)
UVA 10515 - Powers Et Al. 题目链接 题意:求出m^n最后一位数 思路:因为m和n都非常大,直接算肯定是不行的,非常easy想到取最后一位来算,然后又非常easy想到最后一位不 ...
- [python]pip坏了怎么办?
今天,给一位新同事配置pip,用get-pip.py安装之后.出现错误: raise DistributionNotFound(req) # XXX put more info here pkg_r ...
- JAVA 解析复杂的json字符串
转自:https://blog.csdn.net/lovelovelovelovelo/article/details/73614473String parameter = { success : 0 ...