Java--ConcurrentHashMap原理分析
一、背景:
线程不安全的HashMap
效率低下的HashTable容器
锁分段技术
二、应用场景
三、源码解读
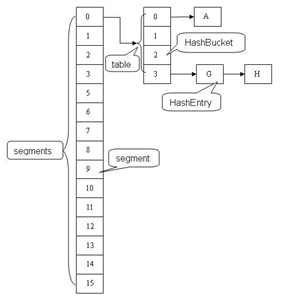
/**
* The segments, each of which is a specialized hash table
*/
final Segment<K,V>[] segments;
不变(Immutable)和易变(Volatile)
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
其它
定位操作:
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
数据结构

static final class Segment<K,V> extends ReentrantLock implements Serializable {
/**
* The number of elements in this segment's region.
*/
transient volatileint count;
/**
* Number of updates that alter the size of the table. This is
* used during bulk-read methods to make sure they see a
* consistent snapshot: If modCounts change during a traversal
* of segments computing size or checking containsValue, then
* we might have an inconsistent view of state so (usually)
* must retry.
*/
transient int modCount;
/**
* The table is rehashed when its size exceeds this threshold.
* (The value of this field is always <tt>(int)(capacity *
* loadFactor)</tt>.)
*/
transient int threshold;
/**
* The per-segment table.
*/
transient volatile HashEntry<K,V>[] table;
/**
* The load factor for the hash table. Even though this value
* is same for all segments, it is replicated to avoid needing
* links to outer object.
* @serial
*/
final float loadFactor;
}
删除操作remove(key)
public V remove(Object key) {
hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
}
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
*for (HashEntry<K,V> p = first; p != e; p = p.next)
*newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}


get操作
V get(Object key, int hash) {
if (count != 0) { // read-volatile 当前桶的数据个数是否为0
HashEntry<K,V> e = getFirst(hash); 得到头节点
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
returnnull;
}
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
put操作
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
- 是否需要扩容。在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阀值,数组进行扩容。值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容。
- 如何扩容。扩容的时候首先会创建一个两倍于原容量的数组,然后将原数组里的元素进行再hash后插入到新的数组里。为了高效ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
boolean containsKey(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key))
returntrue;
e = e.next;
}
}
returnfalse;
}
size()操作
Java--ConcurrentHashMap原理分析的更多相关文章
- ConcurrentHashMap原理分析(1.7与1.8)-put和 get 需要执行两次Hash
ConcurrentHashMap 与HashMap和Hashtable 最大的不同在于:put和 get 两次Hash到达指定的HashEntry,第一次hash到达Segment,第二次到达Seg ...
- Java ConcurrentHashMap 源代码分析
Java ConcurrentHashMap jdk1.8 之前用到过这个,但是一直不清楚原理,今天抽空看了一下代码 但是由于我一直在使用java8,试了半天,暂时还没复现过put死循环的bug 查了 ...
- Java NIO原理分析
Java IO 在Client/Server模型中,Server往往需要同时处理大量来自Client的访问请求,因此Server端需采用支持高并发访问的架构.一种简单而又直接的解决方案是“one-th ...
- Java集合:ConcurrentHashMap原理分析
集合是编程中最常用的数据结构.而谈到并发,几乎总是离不开集合这类高级数据结构的支持.比如两个线程需要同时访问一个中间临界区(Queue),比如常会用缓存作为外部文件的副本(HashMap).这篇文章主 ...
- 【Java并发编程】1、ConcurrentHashMap原理分析
集合是编程中最常用的数据结构.而谈到并发,几乎总是离不开集合这类高级数据结构的支持.比如两个线程需要同时访问一个中间临界区(Queue),比如常会用缓存作为外部文件的副本(HashMap).这篇文章主 ...
- Java 中 ConcurrentHashMap 原理分析
一.Java并发基础 当一个对象或变量可以被多个线程共享的时候,就有可能使得程序的逻辑出现问题. 在一个对象中有一个变量i=0,有两个线程A,B都想对i加1,这个时候便有问题显现出来,关键就是对i加1 ...
- Java集合---ConcurrentHashMap原理分析
集合是编程中最常用的数据结构.而谈到并发,几乎总是离不开集合这类高级数据结构的支持.比如两个线程需要同时访问一个中间临界区(Queue),比如常会用缓存作为外部文件的副本(HashMap).这篇文章主 ...
- java并发系列(七)-----ConcurrentHashMap原理分析(JDK1.8)
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashM ...
- 【Java并发编程】23、ConcurrentHashMap原理分析(1.7和1.8版本对比)
jdk 1.8版本 ConcurrentHashMap在1.8中的实现,相比于1.7的版本基本上全部都变掉了.首先,取消了Segment分段锁的数据结构,取而代之的是数组+链表(红黑树)的结构.而对于 ...
- [转载] ConcurrentHashMap原理分析
转载自http://blog.csdn.net/liuzhengkang/article/details/2916620 集合是编程中最常用的数据结构.而谈到并发,几乎总是离不开集合这类高级数据结构的 ...
随机推荐
- 【Codeforces Round #440 (Div. 2) C】 Maximum splitting
[链接] 我是链接,点我呀:) [题意] 在这里输入题意 [题解] 肯定用尽量多的4最好. 然后对4取模的结果 为0,1,2,3分类讨论即可 [代码] #include <bits/stdc++ ...
- bootstrap课程2 bootstrap的栅格系统的主要作用是什么
bootstrap课程2 bootstrap的栅格系统的主要作用是什么 一.总结 一句话总结:响应式布局(就是适应不同的屏幕,手机,平板,电脑) 1.bootstrap的栅格系统如何使用? row ...
- 【u249】新斯诺克
Time Limit: 1 second Memory Limit: 128 MB [问题描述] 斯诺克又称英式台球,是一种流行的台球运动.在球桌上,台面四角以及两长边中心位置各有一个球洞,使用的球分 ...
- 认识PWA
原文 简书原文:https://www.jianshu.com/p/f38f21ed45dc 大纲 前言 1.什么是PWA 2.PWA 应该具备的特点 3.PWA基础 4.构建 PWA 的业务场景 5 ...
- [CSS] Conditionally Apply Styles Using Feature Queries @supports
While browsers do a great job of ignoring styles they don’t understand, it can be useful to provide ...
- GeoTiff如何存储颜色表的研究
作者:朱金灿 来源:http://blog.csdn.net/clever101 在一次偶然的机会中得知tiff图像时可以存诸颜色表的,心想以后用GeoTiff来保存图像分类图像就十分方便了.于是研究 ...
- mysql去除字段内容的空格和换行回车
MySQL 去除字段中的换行和回车符 解决方法: UPDATE tablename SET field = REPLACE(REPLACE(field, CHAR(10), ''), ...
- 怎样解决CRITICAL glance [-] AttributeError: 'NoneType' object has no attribute 'drivername'
今天在配置OpenStack的Glance时.前边进行的都非常顺利.当作到这一步时sudo glance-manage db_sync时出现了例如以下错误 依据错误提示,想到可能是配置问题.于是就查找 ...
- NBU7.0 RMAN 异机恢复 not found in NetBackup catalog
问题描写叙述: RMAN> run { 2> allocate channel t1 type 'sbt_tape'; 3> send 'NB_ORA_SERV=netback ...
- php定时任务(自己)
php定时任务(自己) 一.总结 一句话总结:可用php.exe连接php文件和bat文件,bat文件在计划任务中可以设置定时执行, 二. 1.php 2.bat E: "D:\softwa ...