ZooKeeper环境搭建(单机/集群)(转)
前提:
配置文件主要是在$ZOOKEEPER_HOME/conf/zoo.cfg,刚解压时为zoo_sample.cfg,重命名zoo.cfg即可。
配置文件常用项参考:http://www.cnblogs.com/EasonJim/p/7483880.html
ZooKeeper基于Java开发,所以在运行前需要安装JDK。
环境搭建:
一、ZooKeeper的搭建方式
ZooKeeper安装方式有三种,单机模式和集群模式以及伪集群模式。
- 单机模式:ZooKeeper只运行在一台服务器上,适合测试环境;
- 伪集群模式:就是在一台物理机上运行多个ZooKeeper 实例;
- 集群模式:ZooKeeper运行于一个集群上,适合生产环境,这个计算机集群被称为一个“集合体”(ensemble)
ZooKeeper通过复制来实现高可用性,只要集合体中半数以上的机器处于可用状态,它就能够保证服务继续。为什么一定要超过半数呢?这跟ZooKeeper的复制策略有关:ZooKeeper确保对ZNode树的每一个修改都会被复制到集合体中超过半数的机器上。
1.1、ZooKeeper的单机模式搭建
下载ZooKeeper:http://www.cnblogs.com/EasonJim/p/7481710.html
解压:
tar -zxvf ZooKeeper-3.4.9.tar.gz
移动到文件夹:
sudo mv ZooKeeper-3.4.9 /usr/local/zk
配置文件:在conf目录下删除zoo_sample.cfg文件,创建一个配置文件zoo.cfg。
只关注以下几项
tickTime=2000
dataDir=/usr/local/zk/data
dataLogDir=/usr/local/zk/logs
clientPort=2181
注意:以上路径的文件夹需要手动创建,且要赋予权限,并且不能放在/tmp文件夹。
创建文件夹:
#创建
sudo mkdir -p /usr/local/zk/data
sudo mkdir -p /usr/local/zk/logs
#设置权限
sudo chmod -R 777 /usr/local/data
sudo chmod -R 777 /usr/local/logs
配置环境变量:为了今后操作方便,我们需要对ZooKeeper的环境变量进行配置,方法如下在/etc/profile文件中加入如下内容:
export ZOOKEEPER_HOME=/usr/local/zk
export PATH=.:$HADOOP_HOME/bin:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$PATH
启动ZooKeeper的Server:zkServer.sh start;关闭ZooKeeper的Server:zkServer.sh stop
1.2、ZooKeeper的伪集群模式搭建
ZooKeeper不但可以在单机上运行单机模式ZooKeeper,而且可以在单机模拟集群模式 ZooKeeper的运行,也就是将不同节点运行在同一台机器。我们知道伪分布模式下Hadoop的操作和分布式模式下有着很大的不同,但是在集群为分布式模式下对ZooKeeper的操作却和集群模式下没有本质的区别。显然,集群伪分布式模式为我们体验ZooKeeper和做一些尝试性的实验提供了很大的便利。比如,我们在实验的时候,可以先使用少量数据在集群伪分布模式下进行测试。当测试可行的时候,再将数据移植到集群模式进行真实的数据实验。这样不 但保证了它的可行性,同时大大提高了实验的效率。这种搭建方式,比较简便,成本比较低,适合测试和学习,如果你的手头机器不足,就可以在一台机器上部署了 3个Server。
1.2.1、注意事项
在一台机器上部署了3个Server,需要注意的是在集群为分布式模式下我们使用的每个配置文档模拟一台机器,也就是说单台机器及上运行多个ZooKeeper实例。但是,必须保证每个配置文档的各个端口号不能冲突,除了clientPort不同之外,dataDir也不同。另外,还要在dataDir所对应的目录中创建myid文件来指定对应的ZooKeeper服务器实例。
- clientPort端口:如果在1台机器上部署多个Server,那么每台机器都要不同的clientPort,比如Server1是2181,Server2是2182,Server3是2183
- dataDir和dataLogDir:dataDir和dataLogDir也需要区分下,将数据文件和日志文件分开存放,同时每个Server的这两变量所对应的路径都是不同的
- server.X和myid: server.X这个数字就是对应,data/myid中的数字。在3个Server的myid文件中分别写入了0,1,2,那么每个Server中的zoo.cfg都配server.0,server.2,server.3就行了。因为在同一台机器上,后面连着的2个端口,3个Server都不要一样,否则端口冲突。
下面是我所配置的集群伪分布模式,分别通过zoo1.cfg、zoo2.cfg、zoo3.cfg来模拟由三台机器的ZooKeeper集群
1.2.1.1、此时需要在/usr/local/zk/conf文件夹下创建三个文件zoo1.cfg、zoo2.cfg、zoo3.cfg
代码清单zoo1.cfg如下:
# The number of milliseconds of each tick
tickTime=2000 # The number of ticks that the initial
# synchronization phase can take
initLimit=10 # The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5 # the directory where the snapshot is stored.
dataDir=/usr/local/zk/data_1 # the port at which the clients will connect
clientPort=2181 #the location of the log file
dataLogDir=/usr/local/zk/logs_1 server.0=localhost:2287:3387
server.1=localhost:2288:3388
server.2=localhost:2289:3389
代码清单zoo2.cfg如下:
# The number of milliseconds of each tick
tickTime=2000 # The number of ticks that the initial
# synchronization phase can take
initLimit=10 # The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5 # the directory where the snapshot is stored.
dataDir=/usr/local/zk/data_2 # the port at which the clients will connect
clientPort=2182 #the location of the log file
dataLogDir=/usr/local/zk/logs_2 server.0=localhost:2287:3387
server.1=localhost:2288:3388
server.2=localhost:2289:3389
代码清单zoo3.cfg如下:
# The number of milliseconds of each tick
tickTime=2000 # The number of ticks that the initial
# synchronization phase can take
initLimit=10 # The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5 # the directory where the snapshot is stored.
dataDir=/usr/local/zk/data_3 # the port at which the clients will connect
clientPort=2183 #the location of the log file
dataLogDir=/usr/local/zk/logs_3 server.0=localhost:2287:3387
server.1=localhost:2288:3388
server.2=localhost:2289:3389
1.2.1.2、在/usr/local/zk创建三个data_{1/2/3}、logs_{1/2/3}
#创建
sudo mkdir -p /usr/local/zk/data_1
sudo mkdir -p /usr/local/zk/data_2
sudo mkdir -p /usr/local/zk/data_3
sudo mkdir -p /usr/local/zk/logs_1
sudo mkdir -p /usr/local/zk/logs_2
sudo mkdir -p /usr/local/zk/logs_3
#设置权限
sudo chmod -R 777 /usr/local/data_1
sudo chmod -R 777 /usr/local/data_2
sudo chmod -R 777 /usr/local/data_3
sudo chmod -R 777 /usr/local/logs_1
sudo chmod -R 777 /usr/local/logs_2
sudo chmod -R 777 /usr/local/logs_3
1.2.1.3、分别在data_{1/2/3}文件夹下创建myid文件,并写入0/1/2
echo "0">/usr/local/data_1/myid
echo "1">/usr/local/data_2/myid
echo "2">/usr/local/data_3/myid
1.2.2、启动
在集群为分布式下,我们只有一台机器,按时要运行三个ZooKeeper实例。此时,如果在使用单机模式的启动命令是行不通的。此时,只要通过下面三条命令就能运行前面所配置的ZooKeeper服务。如下所示:
zkServer.sh start zoo1.cfg
zkServer.sh start zoo2.cfg
zkServer.sh start zoo3.cfg
启动过程,如下图所示:
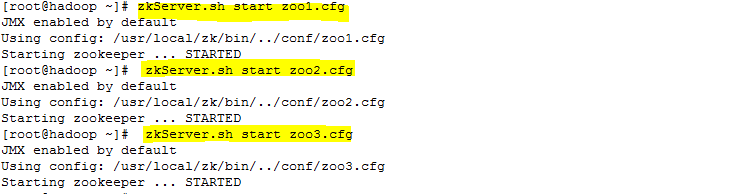
启动结果,如下图所示:

在运行完第一条指令之后,会出现一些错误异常,产生异常信息的原因是由于ZooKeeper服务的每个实例都拥有全局配置信息,他们在启动的时候会随时随地的进行Leader选举操作。此时,第一个启动的ZooKeeper需要和另外两个ZooKeeper实例进行通信。但是,另外两个ZooKeeper实例还没有启动起来,因此就产生了这的异样信息。我们直接将其忽略即可,待把图中“2号”和“3号”ZooKeeper实例启动起来之后,相应的异常信息自然会消失。此时,可以通过下面三条命令,来查询。
zkServer.sh status zoo1.cfg
zkServer.sh status zoo2.cfg
zkServer.sh status zoo3.cfg
ZooKeeper服务的运行状态,如下图所示:
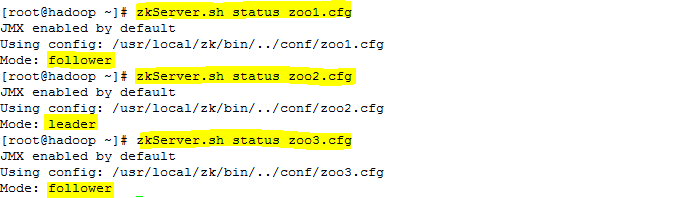
提示:如果以上配置复杂,那么可以直接拷贝三个ZooKeeper的运行目录分别命令为ZooKeeper_1/ZooKeeper_2/ZooKeeper_3
1.3、ZooKeeper的集群模式搭建
为了获得可靠地ZooKeeper服务,用户应该在一个机群上部署ZooKeeper。只要机群上大多数的ZooKeeper服务启动了,那么总的ZooKeeper服务将是可用的。集群的配置方式,和前两种类似,同样需要进行环境变量的配置。在每台机器上conf/zoo.cfg配置文件的参数设置相同
1.3.1、创建myid
在dataDir(/usr/local/zk/data)目录创建myid文件
Server0机器的内容为:0
Server1机器的内容为:1
Server2机器的内容为:2
echo "0">/usr/local/data/myid
echo "1">/usr/local/data/myid
echo "2">/usr/local/data/myid
1.3.2、编写配置文件
在conf目录下删除zoo_sample.cfg文件,创建一个配置文件zoo.cfg,如下所示,代码清单zoo.cfg中的参数设置
# The number of milliseconds of each tick
tickTime=2000 # The number of ticks that the initial
# synchronization phase can take
initLimit=10 # The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5 # the directory where the snapshot is stored.
dataDir=/usr/local/zk/data # the port at which the clients will connect
clientPort=2183 #the location of the log file
dataLogDir=/usr/local/zk/log server.0=hadoop:2288:3388
server.1=hadoop0:2288:3388
server.2=hadoop1:2288:3388
说明:hadoop为host指向的名称,当然也可以直接使用IP。
1.3.3、启动
分别在3台机器上启动ZooKeeper的Server:zkServer.sh start;
二、ZooKeeper的配置
ZooKeeper的功能特性是通过ZooKeeper配置文件来进行控制管理的(zoo.cfg),这样的设计其实有其自身的原因,通过前面对ZooKeeper的配置可以看出,在对ZooKeeper集群进行配置的时候,它的配置文档是完全相同的。集群伪分布模式中,有少部分是不同的。这样的配置方式使得在部署ZooKeeper服务的时候非常方便。如果服务器使用不同的配置文件,必须确保不同配置文件中的服务器列表相匹配。
在设置ZooKeeper配置文档时候,某些参数是可选的,某些是必须的。这些必须参数就构成了ZooKeeper配置文档的最低配置要求。另外,若要对ZooKeeper进行更详细的配置,可以参考下面的内容。
2.1 基本配置
下面是在最低配置要求中必须配置的参数:
①、client:监听客户端连接的端口。
②、tickTime:基本事件单元,这个时间是作为ZooKeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,每隔tickTime时间就会发送一个心跳;最小 的session过期时间为2倍tickTime
③、dataDir:存储内存中数据库快照的位置,如果不设置参数,更新食物的日志将被存储到默认位置。
应该谨慎的选择日志存放的位置,使用专用的日志存储设备能够大大提高系统的性能,如果将日志存储在比较繁忙的存储设备上,那么将会很大程度上影响系统性能。
2.2、高级配置
下面是高级配置参数中可选配置参数,用户可以使用下面的参数来更好的规定ZooKeeper的行为:
①、dataLogdDir
这个操作让管理机器把事务日志写入“dataLogDir”所指定的目录中,而不是“dataDir”所指定的目录。这将允许使用一个专用的日志设备,帮助我们避免日志和快照的竞争。配置如下:
# the directory where the snapshot is stored
dataDir=/usr/local/zk/data
②、maxClientCnxns
这个操作将限制连接到ZooKeeper的客户端数量,并限制并发连接的数量,通过IP来区分不同的客户端。此配置选项可以阻止某些类别的Dos攻击。将他设置为零或忽略不进行设置将会取消对并发连接的限制。
例如,此时我们将maxClientCnxns的值设为1,如下所示:
# set maxClientCnxns
maxClientCnxns=1
启动ZooKeeper之后,首先用一个客户端连接到ZooKeeper服务器上。之后如果有第二个客户端尝试对ZooKeeper进行连接,或者有某些隐式的对客户端的连接操作,将会触发ZooKeeper的上述配置。
③、minSessionTimeout和maxSessionTimeout
即最小的会话超时和最大的会话超时时间。在默认情况下,minSession=2*tickTime;maxSession=20*tickTime。
2.3 集群配置
①、initLimit
此配置表示,允许follower(相对于Leaderer言的“客户端”)连接并同步到Leader的初始化连接时间,以tickTime为单位。当初始化连接时间超过该值,则表示连接失败。
②、syncLimit
此配置项表示Leader与Follower之间发送消息时,请求和应答时间长度。如果Follower在设置时间内不能与Leader通信,那么此Follower将会被丢弃。
③、server.A=B:C:D
A:其中A是一个数字,表示这个是服务器的编号;
B:是这个服务器的IP地址;
C:Leader选举的端口;
D:ZooKeeper服务器之间的通信端口。
④、myid和zoo.cfg
除了修改zoo.cfg配置文件,集群模式下还要配置一个文件myid,这个文件在dataDir目录下,这个文件里面就有一个数据就是A的值,ZooKeeper启动时会读取这个文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是那个Server。
三、搭建ZooKeeper服务器集群(搭建实例)
说明:以下命令要注意权限,非root用户下要加sudo
搭建要求:
1、ZK服务器集群规模不小于3个节点,推荐2*N+1。
2、要求各服务器之间系统时间要保持一致。
3.1、安装配置ZK
①、使用WinScp将Zk传输到Hadoop主机上的/usr/local,我用的版本是ZooKeeper-3.4.5.tar.gz。
②、在hadoop的/usr/local目录下,解压缩zk....tar.gz,设置环境变量
解压缩:在/usr/local目录下,执行命令:tar -zxvf ZooKeeper-3.4.5.tar.gz,如下图所示:

重命名:解压后将文件夹,重命名为zk,执行命令: mv ZooKeeper-3.4.5 zk,如下图所示:

设置环境变量:执行命令: vi /etc/profile ,添加 :export ZOOKEEPER_HOME=/usr/local/zk,如图2.3所示的内容。执行命令:source /etc/profile 如下图所示:


2.2、修改ZK配置文件
①、重命名:将/usr/local/zk/conf目录下zoo_sample.cfg,重命名为zoo.cfg,执行命令:mv zoo_sample.cfg zoo.cfg。如如下图所示:

②、查看:在/usr/local/zk/conf目录下,修改文件vi zoo.cfg,文件内容如下图所示。在该文件中dataDir表示文件存放目录,它的默认设置为/tmp/ZooKeeper这是一个临时存放目录,每次重启后会丢失,在这我们自己设一个目录,/usr/local/zk/data。

③、创建文件夹:mkdir /usr/local/zk/data
④、创建myid:在data目录下,创建文件myid,值为0;vi myid ;内容为0。
⑤、编辑:编辑该文件,执行vi zoo.cfg ,修改dataDir=/usr/local/zk/data。
新增:
server.0=hadoop:2888:3888
server.1=hadoop0:2888:3888
server.2=hadoop1:2888:3888
tickTime :这个时间是作为ZooKeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime 时间就会发送一个心跳;
dataDir:顾名思义就是ZooKeeper保存数据的目录,默认情况下,ZooKeeper将写数据的日志文件也保存在这个目录里;
clientPort:这个端口就是客户端连接ZooKeeper服务器的端口,ZooKeeper会监听这个端口,接受客户端的访问请求。
当这些配置项配置好后,就可以启动ZooKeeper了,启动后使用命令echo ruok | nc localhost 2181检查ZooKeeper是否已经在服务。
2.3、配置其他节点
①、把haooop主机的zk目录和/etc/profile目录,复制到hadoop0和hadoop1中。执行命令:
scp -r /usr/local/zk/ hadoop0:/usr/local/
scp -r /usr/local/zk/ hadoop1:/usr/local/
scp /etc/profile hadoop0:/etc/
scp /etc/profile hadoop1:/etc/ ssh hadoop0
suorce /etc/profile
vi /usr/local/zk/data/myid
exit ssh hadoop1
suorce /etc/profile
vi /usr/local/zk/data/myid
exit
②、把hadoop1中相应的myid的值改为1,把hadoop2中相应的myid的值改为2。
四、启动检验
1、启动,在三个节点上分别执行命令zkServer.sh start
hadoop节点:

hadoop0节点:

hadoop1节点:

2、检验,在三个节点上分别执行命令zkServer.sh status,从下面的图中我们会发现hadoop和hadoop1为Follower,hadoop0为Leader。
hadoop节点:

hadoop0节点:

hadoop1节点:

参考:
http://www.cnblogs.com/sunddenly/p/4018459.html(以上内容大部分转自此篇文章)
http://www.cnblogs.com/qizhelongdeyang/p/6901560.html
http://blog.csdn.net/lemon_tree12138/article/details/51445689
http://blog.sina.com.cn/s/blog_790c59140102w5h1.html
http://blog.csdn.net/shirdrn/article/details/7183503/
http://blog.csdn.net/yinkgh/article/details/52301063
http://www.cnblogs.com/linuxprobe/p/5851699.html
http://www.linuxidc.com/Linux/2015-02/114230.htm
http://www.cnblogs.com/huangxincheng/p/5654170.html
http://www.linuxidc.com/Linux/2013-04/83562.htm
http://www.cnblogs.com/z-sm/p/5691752.html
http://nileader.blog.51cto.com/1381108/795230
http://data.qq.com/article?id=2863
http://blog.csdn.net/tanyujing/article/details/8504481
http://blog.csdn.net/poechant/article/details/6633923
ZooKeeper环境搭建(单机/集群)(转)的更多相关文章
- Redis.之.环境搭建(集群)
Redis.之.环境搭建(集群) 现有环境: /u01/app/ |- redis # 单机版 |- redis-3.2.12 # redis源件 所需软件:redis-3.0.0.gem -- ...
- Windows 环境搭建Redis集群(win 64位)
转: http://blog.csdn.net/zsg88/article/details/73715947 参考:https://www.cnblogs.com/tommy-huang/p/6240 ...
- Windows及Linux环境搭建Redis集群
一.Windows环境搭建Redis集群 参考资料:Windows 环境搭建Redis集群 二.Linux环境搭建Redis集群 参考资料:Redis Cluster的搭建与部署,实现redis的分布 ...
- 环境搭建-Hadoop集群搭建
环境搭建-Hadoop集群搭建 写在前面,前面我们快速搭建好了centos的集群环境,接下来,我们就来开始hadoop的集群的搭建工作 实验环境 Hadoop版本:CDH 5.7.0 这里,我想说一下 ...
- 环境搭建-CentOS集群搭建
环境搭建-CentOS集群搭建 写在前面 最近有许多小伙伴问我,大数据的hadoop分布式集群该如何去搭建.所以,想着,就写一篇博客,帮助到更多刚入门大数据的人.本博客会一步一步带你实现一个Hadoo ...
- kafka环境搭建2-broker集群+zookeeper集群(转)
原文地址:http://www.jianshu.com/p/dc4770fc34b6 zookeeper集群搭建 kafka是通过zookeeper来管理集群.kafka软件包内虽然包括了一个简版的z ...
- Windows 环境搭建Redis集群
环境以及引用资料 1.windows server 2008 r2 enterprise (木有办法,公司的服务器全是如此,就这种环境搭建吧) 2.redis官方资料下载: https://redi ...
- 基于zookeeper+leveldb搭建activemq集群--转载
原地址:http://www.open-open.com/lib/view/open1410569018211.html 自从activemq5.9.0开始,activemq的集群实现方式取消了传统的 ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- 10. ZooKeeper之搭建伪集群模式。
转自:https://blog.csdn.net/en_joker/article/details/78673456 在集群和单机两种模式下,我们基本完成了分别针对生产环境和开发环境ZooKeeper ...
随机推荐
- Ruby 离奇方法
send https://ref.xaio.jp/ruby/classes/object/send find https://ref.xaio.jp/ruby/classes/enumerable/f ...
- Rails5 Route Document
创建: 2017/06/29 完成: 2017/06/29 更新: 2017/06/30 最开头的有效路径展示补充网页版 更新: 2017/07/21 修正错别字 更新: 2017/09/02 增加m ...
- Factstone Benchmark(数学)
http://poj.org/problem?id=2661 题意:Amtel在1960年发行了4位计算机,并实行每十年位数翻一番的策略,将最大整数n作为改变的等级,其中n!表示计算机的无符号整数(n ...
- vue+nodejs+express解决跨域问题
nodejs+express解决跨域问题,发现网上的大部分都是误导人,花了不少时间,终于弄懂了, 我在vue+nodejs+express+mongodb的项目里面,发现本地用vue代理正常调用远程的 ...
- Unity Sprite Packer 问题集合
介绍 今天突发奇想用了下sprite packer 这个功能,基本用法网上教程一堆一堆的,这里就不赘述了. 在使用sprite packer过程中遇到一些问题,然后各种百度不到答案,最后和谐上网找到了 ...
- asp.net MVC 给Controler传一个JSon集合,后台通过List<Model>接收
需求情景 View层经常需要通过Ajax像后台发送一个json对象的集合,但是在后台通过List<Model>无法接收,最后只能通过妥协的方式,在后台获取一个json的字符串,然后通过Js ...
- 【转】Centos7 ftp 配置及报错处理
原文链接: https://www.cnblogs.com/GaZeon/p/5393853.html Centos7网络配置,vsftpd安装及530报错解决 今天在虚拟机安装CentOS7,准备全 ...
- python算数运算符
---恢复内容开始--- 加减乘除 >>> 1+1 2 >>> 4-2 2 >>> 2*5 10 >>> 8/2 4.0 > ...
- 关于用友 U8-UAP二开的一些事
这是关于一个刚刚接触用友U8的二次开发的一些小心得. 首先就是用友二开的论坛,http://u8dev.yonyou.com/ 当然这个论坛做得不怎么样,提出了好几个问题,都没有回复的. 以下是关于二 ...
- servlet-有参数的init和无参的init方法
package gz.itcast.d_init; import javax.servlet.ServletConfig; import javax.servlet.ServletException; ...