MeayunDB-高性能分布式内存数据库
MeayunDB(www.meayun.com)是一款分布式的NoSQL列式内存数据库,由C#编写,主要为高性能,高并发,高可伸缩及大数据系统提供技术解决方案。基于MeayunDB,可以简单,快速的构建应用,并可根据访问量和数据存储需要的增长轻松扩展。
- 列式存储
- 分布式,弹性扩展
- Map/Reduce并行计算
- 嵌入式开发(C#,Python)
- 移动计算
- JSON数据交互
- 无缝集成RDBMS
- 网站数据―社交网站,电子商务,生活服务,旅游订票等
- 缓存系统―由于性能很高,MeayunDB也适合作为信息基础设施的缓存层。
- 高可伸缩,高并发系统―交易软件,电信计费,铁路购票等
- 高性能,低延迟系统―实时行情,报表系统等
- 大数据实时分析统计―高频交易,日志分析,数据挖掘等

MeayunDB部署
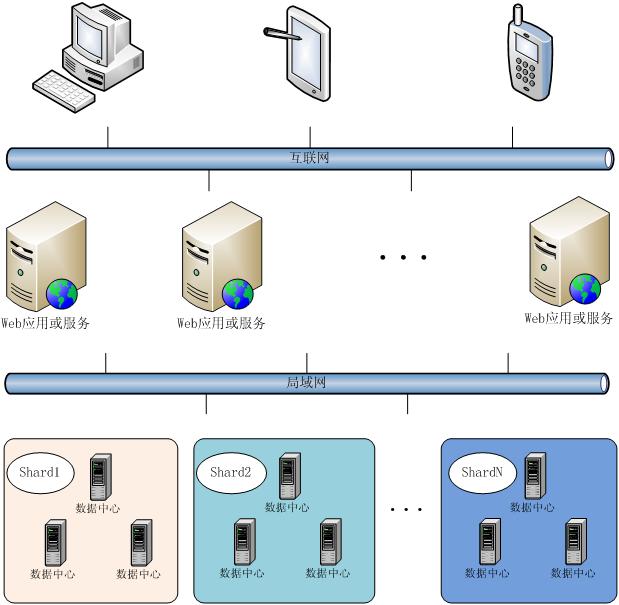
MeayunDB分布式集群由N>=1个MeayunDB子集群构成,每个子集群上的应用是完全相同的,唯一不相同的是每个MeayunDB子集群存储的数据是不相同的。您的所有数据是分布存储到每个子集群中的,每个子集群仅存储了您的数据的一部分。
MeayunDB子集群中MeayunDB实例数需要>=1(具体实例数由用户确定),同一个子集群中的MeayunDB实例数据是完全相同的,对外提供相同的业务应用,同一个子集群中的MeayunDB实例是互为对方的数据备份,可以以增加MeayunDB实例的方式,增加数据备份数。
MeayunDB没有采用主从架构,不存在单点故障问题,随着业务的扩展,可以线性增加子集群数,提高吞吐量,轻松应对上亿行级数据的存储和实时分析处理。
MapReduce流程

用户向MeayunDB集群提交任务后,集群会分解用户任务,并调度集群内MeayunDB实例,并行处理用户任务,最终合并任务结果,合并后的结果可作为下一轮并行计算的输入。
MeayunDB移动计算,而不移动数据,减少客户端/服务器进程间通信开销,并且在内存中进行数据计算,尽可能地提高了系统性能。
MeayunDB性能
本次测试使用的软硬件环境:
硬件配置:Intel(R) Xeon(R) CPUE5-2609 @ 2.40GHz,8核8线程,内存32GB
操作系统:Windows Server 2008 R2 Enterprise
数据表结构:

1. 查询测试:
|
MeayunDB实例 |
记录数(行) |
耗时(毫秒) |
|
单线程查询实例1 |
10000000 |
1641 |
|
单线程查询实例2 |
10000000 |
1590 |
|
单线程查询实例3 |
10000000 |
1246 |
|
单线程查询实例4 |
10000000 |
1593 |
|
单线程查询实例5 |
10000000 |
1484 |
|
单线程查询实例6 |
10000000 |
1694 |
|
单线程查询实例7 |
10000000 |
1376 |
|
单线程查询实例8 |
10000000 |
1581 |
|
8000万数据对double数据列F5求和的耗时 |
2307 |
|
|
查询每条记录的耗时 |
0.0288375微秒 |
|
|
每秒吞吐率(行/s) |
34677070行 |
|
2. 插入测试:
|
MeayunDB实例 |
记录数(行) |
耗时(毫秒) |
|
单线程插入实例1 |
10000000 |
59814 |
|
插入每条记录的耗时 |
5.9814微秒 |
|
|
每秒吞吐率(行/s) |
167184.93行 |
|
MeayunDB价值分析
- 开发简单,快捷,技术要求低,对开发人员友好
- 高可伸缩性,按需弹性扩展
- 降低人的因素影响,降低项目风险,易于项目管理
- 低延迟,高并发,微秒级数据存取效率。
- 大数据存储和实时并行计算
- 管理,开发,维护成本降低50-80%
- 工作效率2-4倍的提升
- 性能10-100倍的提升
QQ交流群:301165454
MeayunDB-高性能分布式内存数据库的更多相关文章
- 基于netty轻量的高性能分布式RPC服务框架forest<下篇>
基于netty轻量的高性能分布式RPC服务框架forest<上篇> 文章已经简单介绍了forest的快速入门,本文旨在介绍forest用户指南. 基本介绍 Forest是一套基于java开 ...
- 基于netty轻量的高性能分布式RPC服务框架forest<上篇>
工作几年,用过不不少RPC框架,也算是读过一些RPC源码.之前也撸过几次RPC框架,但是不断的被自己否定,最近终于又撸了一个,希望能够不断迭代出自己喜欢的样子. 顺便也记录一下撸RPC的过程,一来作为 ...
- 高性能分布式执行框架——Ray
Ray是UC Berkeley AMP实验室新推出的高性能分布式执行框架,它使用了和传统分布式计算系统不一样的架构和对分布式计算的抽象方式,具有比Spark更优异的计算性能. Ray目前还处于实验室阶 ...
- 高可用高性能分布式文件系统FastDFS实践Java程序
在前篇 高可用高性能分布式文件系统FastDFS进阶keepalived+nginx对多tracker进行高可用热备 中已介绍搭建高可用的分布式文件系统架构. 那怎么在程序中调用,其实网上有很多栗子, ...
- 高性能分布式哈希表FastDHT
高性能分布式哈希表FastDHT介绍及安装配置 FastDHT-高效分布式Hash系统 FastDHT(分布式hash系统)安装和与FastDFS整合实现自定义文件ID Centos6.3 停安装 F ...
- 高性能分布式锁-redisson
RedLock算法-使用redis实现分布式锁服务 译自Redis官方文档 在多线程共享临界资源的场景下,分布式锁是一种非常重要的组件. 许多库使用不同的方式使用redis实现一个分布式锁管理. 其中 ...
- FastDFS是使用c语言编写的开源高性能分布式文件系统
FastDFS是什么 FastDFS是使用c语言编写的开源高性能分布式文件系统 是由淘宝开发平台部资深架构师余庆开发,FastDFS孵化平台板块 他对文件进行管理,功能包括文件存储,文件同步,文件访问 ...
- Beanstalkd一个高性能分布式内存队列系统
高性能离不开异步,异步离不开队列,内部是Producer-Consumer模型的原理. 设计中的核心概念: job:一个需要异步处理的任务,是beanstalkd中得基本单元,需要放在一个tube中: ...
- 高性能分布式内存队列系统beanstalkd(转)
beanstalkd一个高性能.轻量级的分布式内存队列系统,最初设计的目的是想通过后台异步执行耗时的任务来降低高容量Web应用系统的页面访问延迟,支持过有9.5 million用户的Facebook ...
随机推荐
- bootstrap初用新得1
## 基本准备 1. 首先把相关软件窗口规划好,对于我的喜好,我喜欢把除了浏览器外的其他软件分为左右两个半屏.左边和右边很多软件之间是需要配合使用的: * 左边: scss文件,ps的guid ...
- [Shell] echo/输出 中引用命令
# 这样是错误的,是引用变量 echo "/Users/${whoami}/Desktop" >>> /Users//Desktop # 正确的写法应该是使用`` ...
- poj 3669 bfs(这道题隐藏着一个大坑)
题意 在x,y坐标系,有流星会落下来,给出每颗流星落下来的坐标和时间,问你能否从(0,0)这个点到一个安全的位置.所谓的安全位置就是不会有流星落下的位置. 题解: 广搜,但是这里有一个深坑,就是搜索的 ...
- 快速搭建一个本地的FTP服务器 win10及win7
快速搭建一个本地的FTP服务器 如果需要开发FTP文件上传下载功能,那么需要在本机上搭建一个本地FTP服务器,方便调试. (win10) 第一步:配置IIS Web服务器 1.1 控制面板中找到“ ...
- Nginx+Keepalived(双机热备)搭建高可用负载均衡环境(HA)-转帖篇
原文:https://my.oschina.net/xshuai/blog/917097 摘要: Nginx+Keepalived搭建高可用负载均衡环境(HA) http://blog.csdn.ne ...
- Django:URL,Views,Template,Models
准备工作:熟悉Django命令行工具 django-admin.py 是Django的一个用于管理任务的命令行工具,常用的命令整理如下: <1> 创建一个django工程 : django ...
- Docker:分布式系统的软件工程革命(上)
转自:http://cxwangyi.github.io/story/docker_revolution_1.md.html Docker:分布式系统的软件工程革命(上) 作者:王益 最后更新:201 ...
- 原生node实现简易留言板
原生node实现简易留言板 学习node,实现一个简单的留言板小demo 1. 使用模块 http模块 创建服务 fs模块 操作读取文件 url模块 便于path操作并读取表单提交数据 art-tem ...
- Django安装部署
MVC模式说明 Model:是应用程序中用于处理应用程序数据逻辑的部分,通常模型对象负责在数据库中存取数据 View: 是应用程序中处理数据显示的部分,通常视图是依据模型数据创建的 Controlle ...
- Centos6下创建Centos6基础镜像
在centos6下可以使用官方仓库拉取一个指定系统类型跟tag的镜像到本地 [root@localhost ~]# docker pull centos:6.8 6.8: Pulling from c ...