ElasticSearch 学习记录之ES如何操作Lucene段
近实时搜索
- 提交(Commiting)一个新的段到磁盘需要一个 fsync 来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据。但是每次提交的一个新的段都fsync 这样操作代价过大。可以使用下面这种更轻量的方式
- 在内存缓冲区中包含了新文档的 Lucene 索引
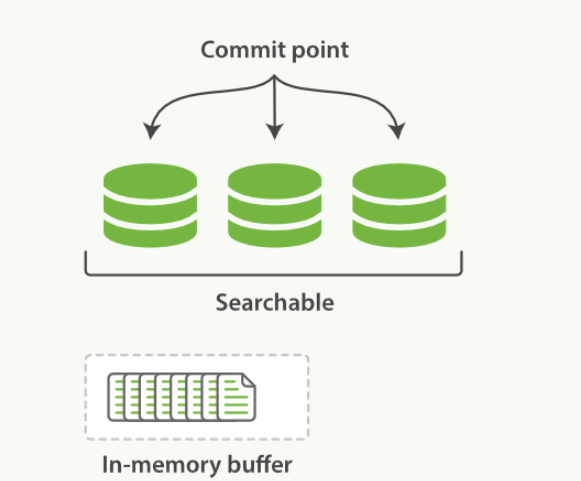
- Lucene 允许新段被写入和打开--使其包含的文档在未进行一次完整提交时便对搜索可见
- 缓冲区的内容已经被写入一个可被搜索的段中,但还没有进行提交
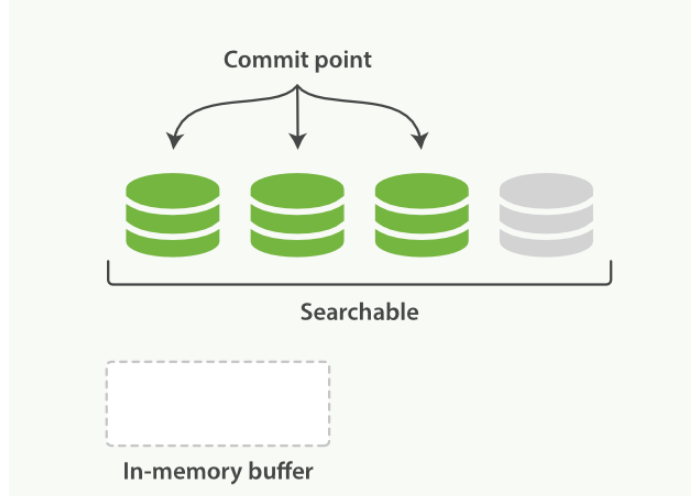
- 这里新段会被先写入到文件系统缓存--这一步代价会比较低,稍后再被刷新到磁盘--这一步代价比较高
- 默认情况下每个分片会每秒自动刷新一次
- 近 实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见
- POST /_refresh // 刷新Refresh 所有的索引
- POST /blogs/_refresh // 只刷新Refresh blogs 索引
可以在settings 设置对定时刷新频率的大小
PUT /my_logs
{
"settings": {
"refresh_interval": "30s" //30秒刷新一次
"refresh_interval": "-1" //关闭自动刷新
"refresh_interval": "1s"//每秒自动刷新
}
}持久化变更
在没有 fsync 把数据从内存刷新到硬盘中,我们不能保证数据在断电或程序退出时之后依然存在
- 即时每秒刷新,也不能实现近实时搜索。我们任然有另外的方法确保从失败中回复数据
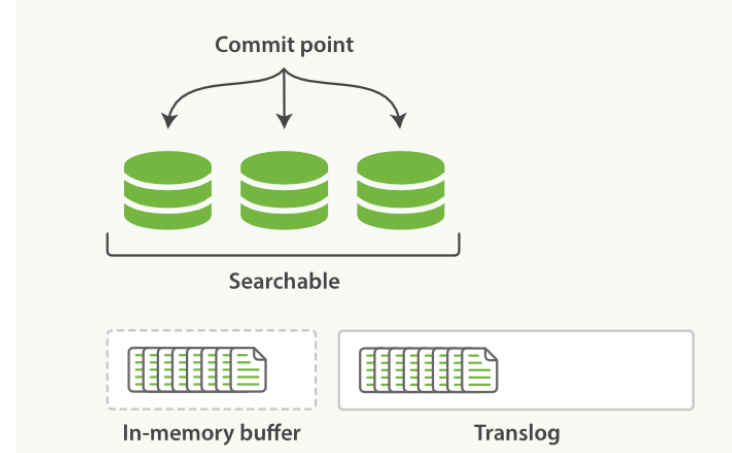
- ES 增加一个translog,或者叫做事务日志。在每次操作是均进行日志记录
- 整个流程是如下的操作
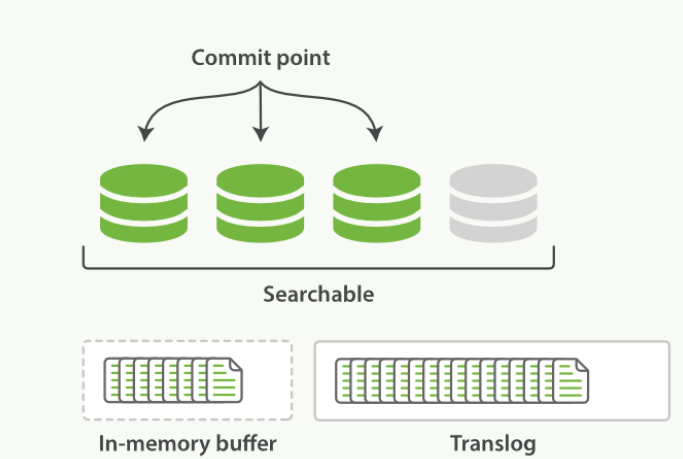
一个文档被索引之后,就会被添加到内存缓冲区,并且 追加到了 translog
-
- 刷新(refresh)使分片处于缓存被清空,但是事务日志不会的状态
- 内存缓冲区的文档被写入新的段中,但是没有进行fsync
- 段被打开,且可被搜索到
- 内存缓冲区被清空
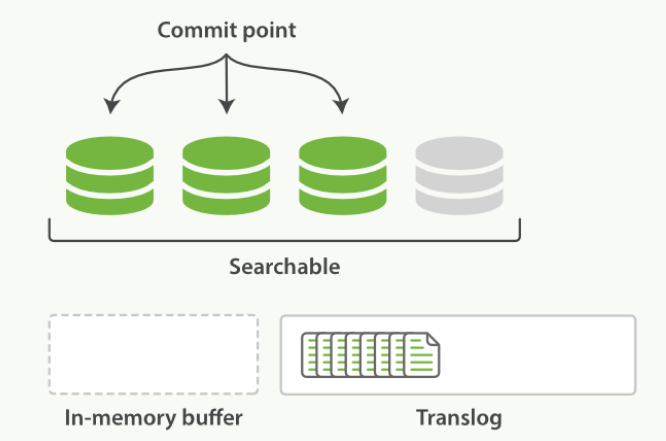
- 进程继续进行,更多的文档被添加到内存缓冲区和追加的事务日志中
每隔一段时间,translog太大 或 索引被刷新。一个新的translog被创建,并且被全量提交
-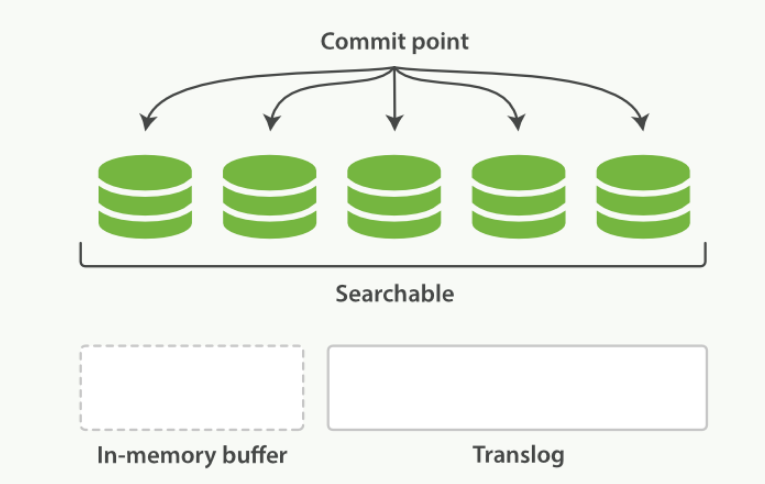
- 所有内存缓冲区的文档都被写入一个新的段中
- 缓冲区内清空
- 一个提交点被写入硬盘
- 文件系统缓存通过fsync被刷新
- 老的translog 被删除
- translog 提供所有没有被刷新到磁盘操作的一个持久化记录。当ES启动时,会根据最后一个提交点去恢复已知的段
- translog 也可供用来提供实时的CRUD。但我们进行一些CRUD操作时,它会首先检查translog任何最近的变更。
- flush API 执行一次提交,并截断translog的操作
- 分片默认每30M自动flush一次。translog太大也会自动flush
可通过自己执行flush API操作
POST /blogs/_flush //刷新索引
POST /_flush?wait_for_ongoing //刷新索引并等待所有的刷新结果返回
段合并
- 段合并的时候会将那些旧的已删除的文档从文件系统中删除,被删除或者被更新的文档不会被复制到新的大段中
段合并的流程
-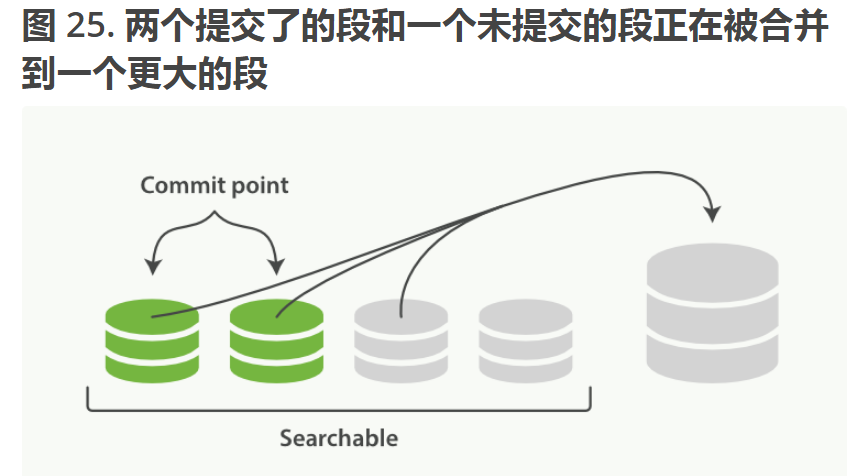
- 当索引的时候,刷新(refresh)操作会创建新的段
- 合并的时候会选择一部分大小相似的段,并且将其合并到更大的段中
- 段的合并结束,老的段就要被删除
- optimized API 的作用
- optimize API大可看做是 强制合并 API 。
ElasticSearch 学习记录之ES如何操作Lucene段的更多相关文章
- ElasticSearch 学习记录之ES几种常见的聚合操作
ES几种常见的聚合操作 普通聚合 POST /product/_search { "size": 0, "aggs": { "agg_city&quo ...
- ElasticSearch 学习记录之ES短语匹配基本用法
短语匹配 短语匹配故名思意就是对分词后的短语就是匹配,而不是仅仅对单独的单词进行匹配 下面就是根据下面的脚本例子来看整个短语匹配的有哪些作用和优点 GET /my_index/my_type/_sea ...
- ElasticSearch 学习记录之ES高亮搜索
高亮搜索 ES 通过在查询的时候可以在查询之后的字段数据加上html 标签字段,使文档在在web 界面上显示的时候是由颜色或者字体格式的 GET /product/_search { "si ...
- ElasticSearch 学习记录之ES查询添加排序字段和使用missing或existing字段查询
ES添加排序 在默认的情况下,ES 是根据文档的得分score来进行文档额排序的.但是自己可以根据自己的针对一些字段进行排序.就像下面的查询脚本一样.下面的这个查询是根据productid这个值进行排 ...
- ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
分布式文档存储 ES分布式特性 屏蔽了分布式系统的复杂性 集群内的原理 垂直扩容和水平扩容 真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中 ES集群特点 ...
- ElasticSearch 学习记录之如任何设计可扩容的索引结构
扩容设计 扩容的单元 一个分片即一个 Lucene 索引 ,一个 Elasticsearch 索引即一系列分片的集合 一个分片即为 扩容的单元 . 一个最小的索引拥有一个分片. 一个只有一个分片的索引 ...
- ElasticSearch 学习记录之父子结构的查询
父子结构 父亲type属性查询子type 的类型 父子结构的查询,可以通过父亲类型的字段,查询出子类型的索引信息 POST /product/_search { "query": ...
- ElasticSearch 学习记录之Text keyword 两种基本类型区别
ElasticSearch 系列文章 1 ES 入门之一 安装ElasticSearcha 2 ES 记录之如何创建一个索引映射 3 ElasticSearch 学习记录之Text keyword 两 ...
- Elasticsearch学习记录(分布式的特性)
Elasticsearch学习记录(分布式的特性) 分布式的特性 我们提到Elasticsearch可以扩展到上百(甚至上千)的服务器来处理PB级的数据.然而我们的例子只给出了一些使用Elastics ...
随机推荐
- springboot学习(二)——springmvc配置使用
以下内容,如有问题,烦请指出,谢谢 上一篇讲解了springboot的helloworld部分,这一篇开始讲解如何使用springboot进行实际的应用开发,基本上寻着spring应用的路子来讲,从s ...
- 基于Flink秒级计算时CPU监控图表数据中断问题
基于Flink进行秒级计算时,发现监控图表中CPU有数据中断现象,通过一段时间的跟踪定位,该问题目前已得到有效解决,以下是解决思路: 一.问题现象 以SQL02为例,发现本来10秒一 ...
- PHP使用api的两种方法
1.用file_get_contents()函数 $params = array('key' => '8d284859d04cfeeea6b0771f754adb49', 'location' ...
- 基于 HTML5 Canvas 的 3D 模型列表贴图
少量图片对于我们赋值是没有什么难度,但是如果图片的量大的话,我们肯定希望能很直接地显示在界面上供我们使用,再就是排放的位置等等,这些都需要比较直观的操作,在实际应用中会让我们省很多力以及时间.下面这个 ...
- 40.Linux应用调试-使用gdb和gdbserver
1.gdb和gdbserver调试原理 通过linux虚拟机里的gdb,来向开发板里的gdbserver发送命令,比如设置断点,运行setp等,然后开发板上的gdbserver收到命令后,便会执行应用 ...
- ssm开发使用redis作为缓存,使用步骤
1.关于spring配置文件中对于redis的配置 <!-- redis配置 --> <bean id="jedisPoolConfig" class=" ...
- QGIS2.18.0的精简编译
1.下代码,下依赖库 - expat - fcgi - gdal - gsl-devel - iconv - openssl-devel - openssl-libs - pyqt4 - qca-de ...
- C++ IO操作API及注意事项(包含一个日志类的实现)
C++是一个抽象程度比C高很多的语言,在使用C++时,编译器做了很多工作,如果我们不对C++的某些特性的实现机制进行了解,那么编程时也许会有很多疑惑,我们也许知道怎样做才是正确的,但不知道为什么要这样 ...
- 对datatable进行简单的操作
筛选出datatable中c_level=1的数据 dataRow[] rows = dt.Select("c_level=0"); 克隆表dt的结构到表dt,并将dt的数据复制到 ...
- C++中指向类的指针
事情缘起是因为上班途中刷到了有个微博,那人说答对这个问题的请发简历. 看了就是关于指向C++类的指针的知识,原代码类似下面这样: class NullPointCall { public: void ...