python网络数据采集(伴奏曲)
这里是前章,我们做一下预备。之前太多事情没能写博客~。。 (此博客只适合python3x,python2x请自行更改代码)
首先你要有bs4模块
windows下安装:pip3 install bs4,如果你电脑有python2x和python3x的话,在python3x中安装bs4请已管理员的身份运行cmd执行pip3 install bs4安装bs4。
linux下安装:sudo pip3 install bs4
还有urllib.request模块
windows下安装:pip3 install urllib.request,如果你电脑有python2x和python3x的话,在python3x中安装bs4请已管理员的身份运行cmd执行pip3 install urllib.request安装urllib.request模块
例子1:获取源码
from urllib.request import urlopen
from bs4 import BeautifulSoup
html=urlopen("http://wikipedia.org")
dgc=BeautifulSoup(html)
print(dgc)
输出图如下:
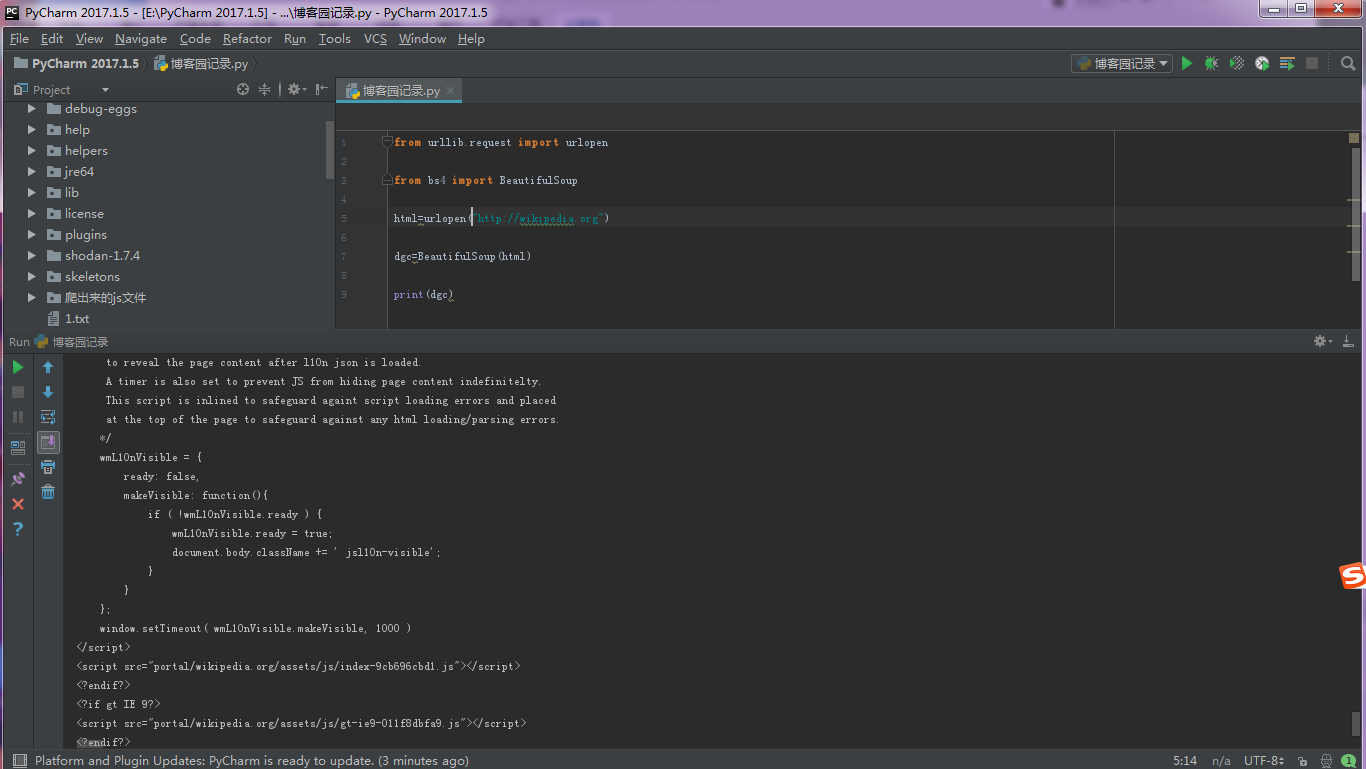
这里我忘记加自定义错误了,当然你也可以不加。保险起见还是加
例子二:匹配对应的标签
from urllib.request import urlopen from bs4 import BeautifulSoup
try:
html=urlopen("http://dlszx.dgjy.net/")
except EOFError as a:
print("404 ")
except:
print("404")
dgc=BeautifulSoup(html)
fbc=dgc.findAll("img",{"src":"uploadfile/201762105219962.jpg"})
print(fbc)
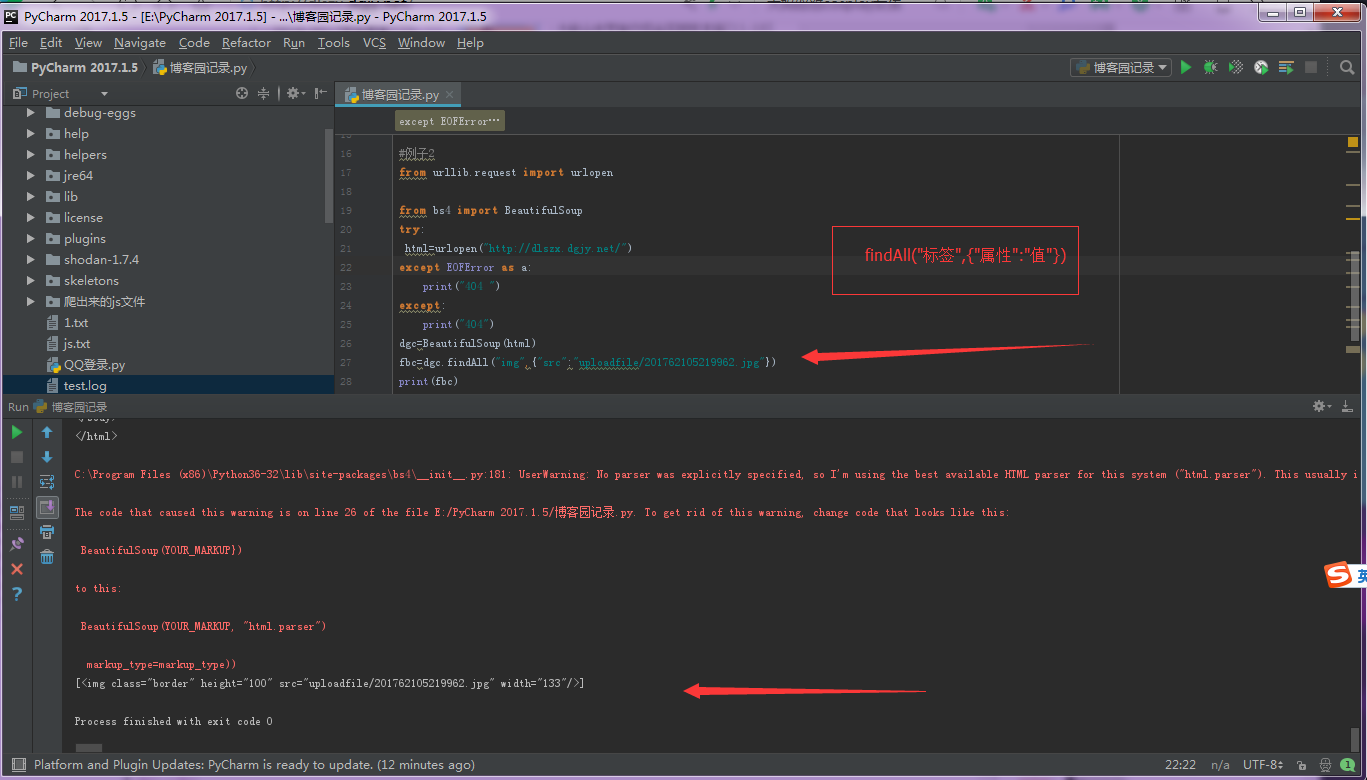
例子3:正则匹配所有对应的标签
不会正则的请去学习
from urllib.request import urlopen
import re
from bs4 import BeautifulSoup
try:
html=urlopen("http://dlszx.dgjy.net/")
except EOFError as a:
print("404 ")
except:
print("404")
dgc=BeautifulSoup(html)
fbc=dgc.findAll("img",{"src":re.compile("img/.*?\.jpg")})
for inks in fbc:
print(inks)
注意事项!!!:不要拿findAll去搜索引擎匹配,乱的你想死
搜索引擎正则匹配要求很高:http:\/\/[a-zA-z].*?\[a-z]
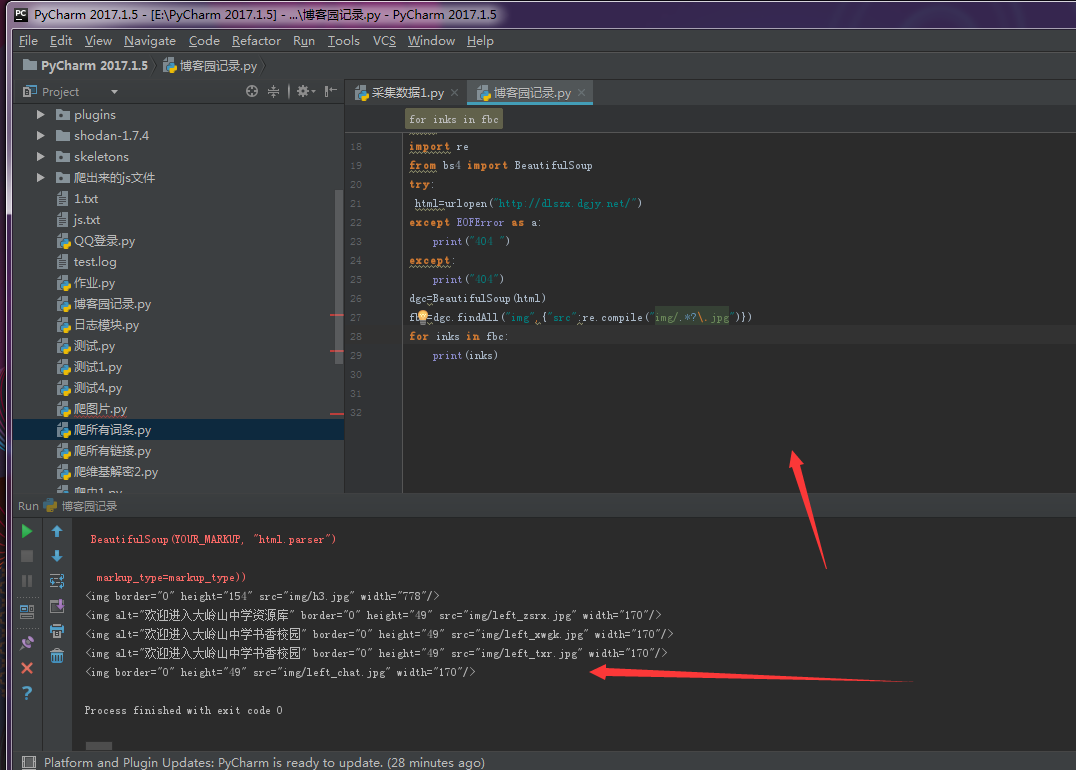
例子4:
匹配网站所有的链接
from urllib.request import urlopen
import re
from bs4 import BeautifulSoup
try:
html=urlopen("http://wikipeda.org")
except EOFError as a:
print("EOFError")
except:
print("I dont EOFError")
gfc=BeautifulSoup(html)
for inks in gfc.findAll("a")
if 'href' in inks.attrs:
print("inks.attrs["href"]")
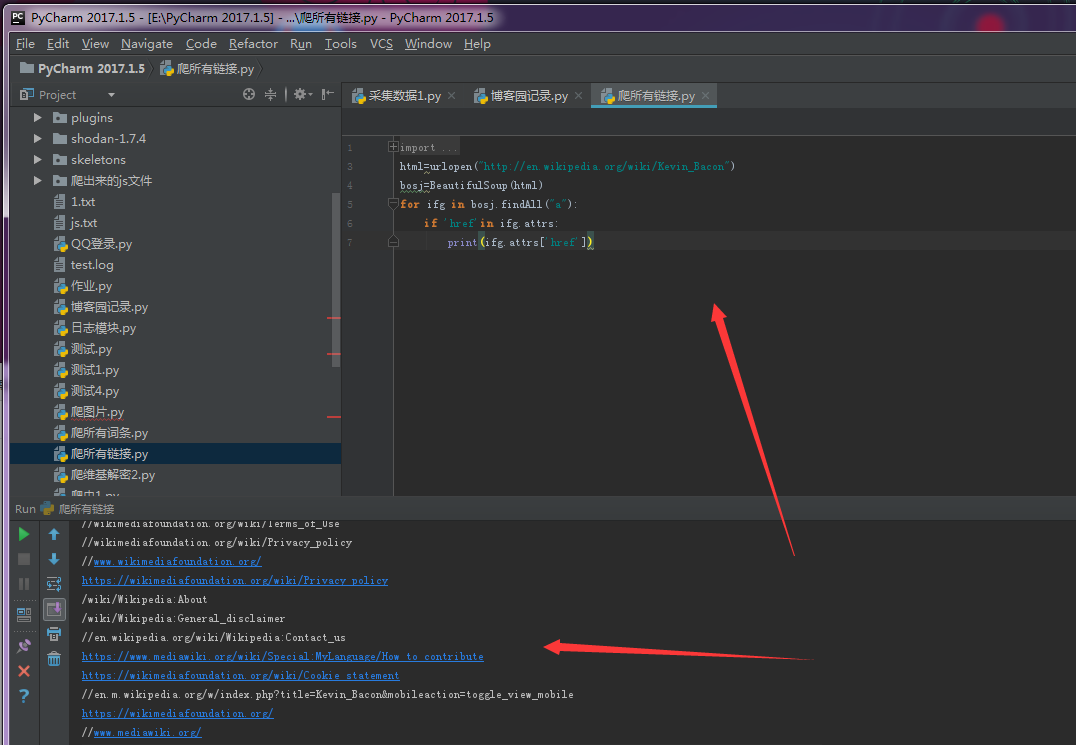
现在的时间是
2017-8-13-13:38
python网络数据采集(伴奏曲)的更多相关文章
- 笔记之Python网络数据采集
笔记之Python网络数据采集 非原创即采集 一念清净, 烈焰成池, 一念觉醒, 方登彼岸 网络数据采集, 无非就是写一个自动化程序向网络服务器请求数据, 再对数据进行解析, 提取需要的信息 通常, ...
- Python网络数据采集7-单元测试与Selenium自动化测试
Python网络数据采集7-单元测试与Selenium自动化测试 单元测试 Python中使用内置库unittest可完成单元测试.只要继承unittest.TestCase类,就可以实现下面的功能. ...
- Python网络数据采集6-隐含输入字段
Python网络数据采集6-隐含输入字段 selenium的get_cookies可以轻松获取所有cookie. from pprint import pprint from selenium imp ...
- Python网络数据采集4-POST提交与Cookie的处理
Python网络数据采集4-POST提交与Cookie的处理 POST提交 之前访问页面都是用的get提交方式,有些网页需要登录才能访问,此时需要提交参数.虽然在一些网页,get方式也能提交参.比如h ...
- Python网络数据采集3-数据存到CSV以及MySql
Python网络数据采集3-数据存到CSV以及MySql 先热热身,下载某个页面的所有图片. import requests from bs4 import BeautifulSoup headers ...
- Python网络数据采集2-wikipedia
Python网络数据采集2-wikipedia 随机链接跳转 获取维基百科的词条超链接,并随机跳转.可能侧边栏和低栏会有其他链接.这不是我们想要的,所以定位到正文.正文在id为bodyContent的 ...
- Python网络数据采集1-Beautifulsoup的使用
Python网络数据采集1-Beautifulsoup的使用 来自此书: [美]Ryan Mitchell <Python网络数据采集>,例子是照搬的,觉得跟着敲一遍还是有作用的,所以记录 ...
- Python网络数据采集PDF
Python网络数据采集(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/16c4GjoAL_uKzdGPjG47S4Q 提取码:febb 复制这段内容后打开百度网盘手 ...
- python网络数据采集的代码
python网络数据采集的代码 https://github.com/REMitchell/python-scraping
- [python] 网络数据采集 操作清单 BeautifulSoup、Selenium、Tesseract、CSV等
Python网络数据采集操作清单 BeautifulSoup.Selenium.Tesseract.CSV等 Python网络数据采集操作清单 BeautifulSoup.Selenium.Tesse ...
随机推荐
- 58、js扩展
作用域是JavaScript最重要的概念之一,想要学好JavaScript就需要理解JavaScript作用域和作用域链的工作原理. 一.js的作用域 任何程序设计语言都有作用域的概念,简单的说,作用 ...
- 排序sort,统计wc
[root@localhost ~]# sort /etc/passwd 注释:默认按字母升序排 abrt:x::::/etc/abrt:/sbin/nologin adm:x:::adm:/var/ ...
- 历史命令~/.bash_history,查看所有别名alias,命令执行顺序,命令行常用快捷键,输入输出重定向,wc统计字节单词行数
历史命令大小:/etc/profile中字段HISTSIZE=1000 历史命令保存文件:~/.bash_history history -c 清空历史命令 history -w 把历史命令写入~/. ...
- 【java】java.lang.Math:public static long round(double a)和public static int round(float a)
package math; public class TestMath_round { public static void main(String[] args) { System.out.prin ...
- APP安全--网络传输安全 AES/RSA/ECC/MD5/SHA
移动端App安全如果按CS结构来划分的话,主要涉及客户端本身数据安全,Client到Server网络传输的安全,客户端本身安全又包括代码安全和数据存储安全.所以当我们谈论App安全问题的时候一般来说在 ...
- iOS开发--SQLite重要框架FMDB的使用
什么是FMDB: FMDB是一个和iOS的SQLite数据库操作相关的第三方框架.主要把C语言操作数据库的代码用OC进行了封装.使用者只需调用该框架的API就能用来创建并连接数据库,创建表,查询等. ...
- JavaWeb之数据源连接池(2)---C3P0
我们接着<JavaWeb之数据源连接池(1)---DBCP>继续介绍数据源连接池. 首先,在Web项目的WebContent--->WEB-INF--->lib文件夹中添加C3 ...
- ubuntu16.04 查询ip,网关,dns信息
用ifconfig命令只能查询ip,子网掩码信息,不能获取dns和网关信息 用下面命令即可查询 nmcli dev show
- @Data 注解引出的 lombok 小辣椒
今天在看代码的时候, 看到了这个注解, 之前都没有见过, 所以就查了下, 发现还是个不错的注解, 可以让代码更加简洁. 这个注解来自于 lombok,lombok 能够减少大量的模板代码,减少了在使用 ...
- BZOJ4817 SDOI2017 相关分析
4821: [Sdoi2017]相关分析 Time Limit: 10 Sec Memory Limit: 128 MBSec Special Judge Description Frank对天文 ...