用 HAproxy 搭建 RabbitMQ 集群
构建参考: [ Rabbitmq cluster setup with HAproxy ] [ python demo ]
RabbitMQ Cluster 遇到的问题
python pika 作为consumer 连接 rabbitmq cluster 的时候, 事实上连接的是 cluster 的一个 node, 当连接数过多的时候, 这个节点的处理性能会成为一个瓶颈, 可能会遇到这样的报错 [ connection reset by peer ].
对于 [ connection reset by peer ] 这个问题的处理, [ 这里 ] 提供了一个方案:
Client --> Load Balancer --> RabbitMQ Cluster Instances
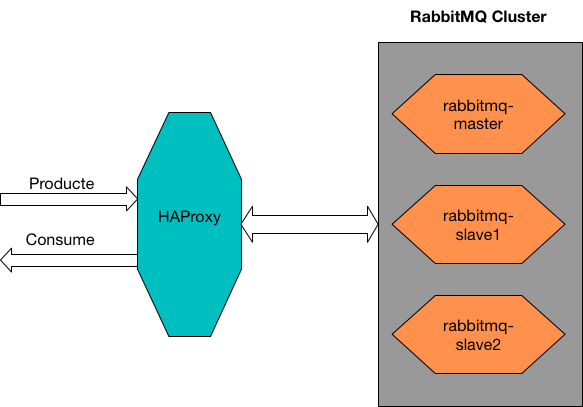
RabbitMQ 集群构建
集群环境
系统: CentOS 7.x x64
haproxy-server : 172.16.0.100
rabbitmq-master : 172.16.0.10
rabbitmq-slave1 : 172.16.0.11
rabbitmq-slave2 : 172.16.0.12
配置 /etc/hosts
172.16.0.10 rabbitmq-master
172.16.0.11 rabbitmq-slave1
172.16.0.12 rabbitmq-slave2
安装 RabbitMQ
在三台 rabbitmq 服务器上面分别执行:
yum install rabbitmq-server
配置 Cookie
RabbitMQ 集群通过 /var/lib/rabbitmq/.erlang.cookie 内的 cookie 值来确认各节点是否在同一个集群.
在 rabbitmq-master:
rabbitmq-server -detached
在 rabbitmq-master上查看 /var/lib/rabbitmq/.erlang.cookie 值:
cat /var/lib/rabbitmq/.erlang.cookie
比如获取的值为: GBNXRROLXDWMMIFZQWHD
在 rabbitmq-slave1 & rabbitmq-slave2 :
echo GBNXRROLXDWMMIFZQWHD > /var/lib/rabbitmq/.erlang.cookie
添加 Slave 节点到 master
在 rabbitmq-slave1 & rabbitmq-slave2 上面启动服务:
rabbitmq-server -detached
在rabbitmq-slave1 & rabbitmq-slave2 上分别执行:
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbitmq@rabbitmq-master
rabbitmqctl start_app
查看集群状态
在 RabbitMQ Cluster 任意一个节点:
rabbitmctl cluster_status
启用集群高可用
在 RabbitMQ Cluster 每个节点执行:
rabbitmqctl set_policy ha-all "" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
启用 RabbitMQ 组件
在 RabbitMQ Cluster 每个节点执行:
rabbitmq-plugins enable rabbitmq_management
添加用户
在 RabbitMQ Cluster 每个节点:
rabbitmqctl add_user <username> <password>
rabbitmqctl set_user_tags <username> <tag>
rabbitmqctl set_permissions -p / <username> ".*" ".*" ".*"
备注: 在 rabbitmqctl set_user_tags <username> <tag>中, <tag> 可以是任何标记用户的字符, 比如 admin, normal, guest, developer 等标记用户身份的 tag.
这样, RabbitMQ 集群配置完成.
Web 访问
web 访问的前提是我们启用了 RabbitMQ 的组件: rabbitmq-plugins enable rabbitmq_management
可以在浏览器访问: http://ip_address:15672
登录用户和密码是 : rabbitmqctl add_user username password 设定的.
也可以使用默认添加的用户和密码: guest / guest.
HAProxy
以下所有的配置均在 haproxy-server 上面执行
安装 haproxy
yum install haproxy
配置 haproxy
vim /etc/haproxy/haproxy.cfg
global
daemon
defaults
mode tcp
maxconn 10000
timeout connect 5s
timeout client 100s
timeout server 100s
listen rabbitmq 172.16.0.100:5672
mode tcp
balance roundrobin
server rabbit-master 172.16.0.10:5672 check inter 5s rise 2 fall 3
server rabbit-node1 172.16.0.11:5672 check inter 5s rise 2 fall 3
server rabbit-node2 172.16.0.12:5672 check inter 5s rise 2 fall 3
启动 haproxy
systemctl start haproxy
至此, 用 HAproxy 做RabbitMQ 的 LB 的集群已经配置完成, 在连接 MQ 的时候, 只要将地址配置为 haproxy-server 的 IP 和对应 Port 即可. 接下来会用 python 程序做测试
RabbitMQ Cluster Product & Consume Test
生产者: send.py
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='172.16.0.100',port=5672))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
消费者: receive.py
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='172.16.0.100',port=5672))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(callback,
queue='hello',
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
生产
在同一网络中的机器 CLI 执行:
for i in {1..10};do python send.py;done
这可以写10条数据到 RabbitMQ 的队列中.
在 RabbitMQ Cluster 的任意一个节点执行:
rabbitmqctl list_queues
可以查看到队列以及队列内消息的数量.
消费
在同一网络中的机器 CLI 执行:
python receive.py
即可读取队列中的数据.
btw, 我爱死博客园的 markdown 了!
用 HAproxy 搭建 RabbitMQ 集群的更多相关文章
- 使用Haproxy代理rabbitmq集群,用keepalive保证haproxy高可用
原文地址:https://www.jianshu.com/p/440b8e1d5339 使用Haproxy代理rabbitmq集群 上一篇文章教了rabbitmq集群搭建.但是这样搭建出来的集群是3个 ...
- Docker:搭建RabbitMQ集群
RabbitMQ原理介绍(一) RabbitMQ安装使用(二) RabbitMQ添加新用户并支持远程访问(三) RabbitMQ管理命令rabbitmqctl详解(四) RabbitMQ两种集群模式配 ...
- 搭建RabbitMQ集群(Docker)
前一篇搭建RabbitMQ集群(通用)只是把笔记直接移动过来了,因为我的机器硬盘已经满了,实在是开不了那么虚拟机. 还好,我的Linux中安装了Docker,这篇文章就简单介绍一下Docker中搭建R ...
- Docker搭建RabbitMQ集群
Docker搭建RabbitMQ集群 Docker安装 见官网 RabbitMQ镜像下载及配置 见此博文 集群搭建 首先,我们需要启动运行RabbitMQ docker run -d --hostna ...
- 搭建rabbitmq集群
查看rabbitmq日志文件 开启web管理工具 [root@controller rabbitmq]# rabbitmq-plugins list [root@controller rabbitmq ...
- CentOS7 搭建RabbitMQ集群 后台管理 历史消费记录查看
简介 通过 Erlang 的分布式特性(通过 magic cookie 认证节点)进行 RabbitMQ 集群,各 RabbitMQ 服务为对等节点,即每个节点都提供服务给客户端连接,进行消息发送与接 ...
- docker+phantomjs+haproxy 搭建phantomjs集群
目标: 搭建一个远程的phantomjs服务器,提供高可用服务,支持并发. 原料: 1.docker环境.docker-compose环境 2.phantomjs镜像: docker.io/werni ...
- 搭建RabbitMQ集群(通用)
RabbitMQ在Erlang node(节点)上 Erlang天生具有集群特性,非常好搭建集群,每一个节点(node)上具有一个叫erlang.Cookie的东西,也是一个标识符,可以互认. 1). ...
- Haproxy搭建web集群
目录: 一.常见的web集群调度器 二.Haproxy应用分析 三.Haproxy调度算法原理 四.Haproxy特性 五.Haproxy搭建 Web 群集 一.常见的web集群调度器 目前常见的we ...
随机推荐
- Ajax异步交互 [异步对象连接服务器]
<!DOCTYPE html><html> <head> <meta charset="utf-8"> <title>X ...
- MATLAB中最基本函数plot()的用法
1二维平面图形 1.1基本图形函数 画出一条正弦曲线和一条余弦曲线 1.1.1绘图参数表 y 黄- 实线. 点< 小于号 m 紫: 点线o 圆s 正方形 c 青-. 点划线x 叉号d 菱形 r ...
- Effective Java 第三版——1. 考虑使用静态工厂方法替代构造方法
Tips <Effective Java, Third Edition>一书英文版已经出版,这本书的第二版想必很多人都读过,号称Java四大名著之一,不过第二版2009年出版,到现在已经将 ...
- RobotFramework自动化测试框架-移动手机自动化测试Element Attribute Should Match关键字的使用
Element Attribute Should Match 关键字用来判断元素的属性值是否和预期值匹配,该关键字接收四个参数[ locator | attr_name | match_pattern ...
- Java---Ajax在Struts2框架的应用实例
Ajax 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术. 很久没有动过ajax了,趁此机会复习一下,写一个简单的例子 一.项目结构: 二.需要的jar包 三.具体代码: 1.web.x ...
- svn文件回滚到某个历史版本号
转载请注明出处:http://blog.csdn.net/dongdong9223/article/details/50819642 本文出自[我是干勾鱼的博客] 有时候想要将svn中的某个文件回滚到 ...
- hdu4893 Wow! Such Sequence!
线段树结点上保存一个一般的sum值,再同一时候保存一个fbsum,表示这个结点表示的一段数字若为斐波那契数时的和 当进行3操作时,仅仅用将sum = fbsum就可以 其它操作照常进行,仅仅是单点更新 ...
- RxJava开发精要6 - 组合Observables
原文出自<RxJava Essentials> 原文作者 : Ivan Morgillo 译文出自 : 开发技术前线 www.devtf.cn 转载声明: 本译文已授权开发人员头条享有独家 ...
- NHibernate之旅(13):初探马上载入机制
本节内容 引入 马上载入 实例分析 1.一对多关系实例 2.多对多关系实例 结语 引入 通过上一篇的介绍,我们知道了NHibernate中默认的载入机制--延迟载入.其本质就是使用GoF23中代理模式 ...
- MySQL 删除数据库中反复数据(以部分数据为准)
delete from zqzrdp where tel in (select min(dpxx_id) from zqzrdp group by tel having count(tel)& ...