浏览器缓存机制<转>
浏览器缓存机制,其实主要就是HTTP协议定义的缓存机制(如: Expires; Cache-control等)。但是也有非HTTP协议定义的缓存机制,如使用HTML Meta 标签,Web开发者可以在HTML页面的<head>节点中加入<meta>标签,代码如下:
|
html code |
|
<META HTTP-EQUIV="Pragma" CONTENT="no-cache"> |
上述代码的作用是告诉浏览器当前页面不被缓存,每次访问都需要去服务器拉取。使用上很简单,但只有部分浏览器可以支持,而且所有缓存代理服务器都不支持,因为代理不解析HTML内容本身。
下面我主要介绍HTTP协议定义的缓存机制。
Expires策略
Expires是Web服务器响应消息头字段,在响应http请求时告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据,而无需再次请求。
下面是宝宝PK项目中,浏览器拉取jquery.js web服务器的响应头:

注:Date头域表示消息发送的时间,时间的描述格式由rfc822定义。例如,Date: Mon,31 Dec 2001 04:25:57GMT。
分钟。
不过Expires 是HTTP 1.0的东西,现在默认浏览器均默认使用HTTP 1.1,所以它的作用基本忽略。
Cache-control策略(重点关注)
Cache-Control与Expires的作用一致,都是指明当前资源的有效期,控制浏览器是否直接从浏览器缓存取数据还是重新发请求到服务器取数据。只不过Cache-Control的选择更多,设置更细致,如果同时设置的话,其优先级高于Expires。
|
http协议头Cache-Control : |
|
值可以是public、private、no-cache、no- store、no-transform、must-revalidate、proxy-revalidate、max-age 各个消息中的指令含义如下:
|
分钟(和上面的Expires时间一致,这个不是必须的)。

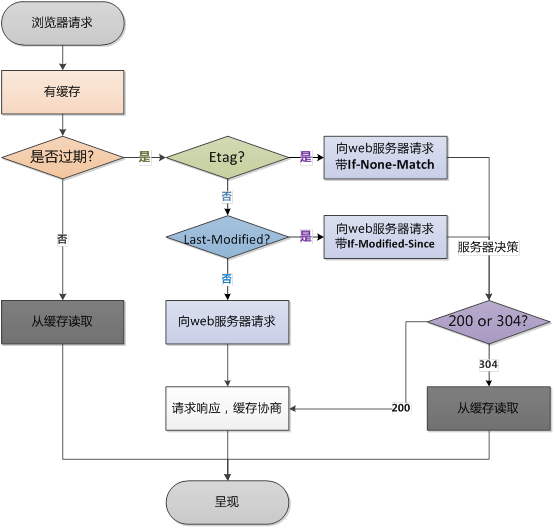
Last-Modified/If-Modified-Since
Last-Modified/If-Modified-Since要配合Cache-Control使用。
l Last-Modified:标示这个响应资源的最后修改时间。web服务器在响应请求时,告诉浏览器资源的最后修改时间。
l If-Modified-Since:当资源过期时(使用Cache-Control标识的max-age),发现资源具有Last-Modified声明,则再次向web服务器请求时带上头 If-Modified-Since,表示请求时间。web服务器收到请求后发现有头If-Modified-Since 则与被请求资源的最后修改时间进行比对。若最后修改时间较新,说明资源又被改动过,则响应整片资源内容(写在响应消息包体内),HTTP 200;若最后修改时间较旧,说明资源无新修改,则响应HTTP 304 (无需包体,节省浏览),告知浏览器继续使用所保存的cache。
Etag/If-None-Match
Etag/If-None-Match也要配合Cache-Control使用。
l Etag:web服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器觉得)。Apache中,ETag的值,默认是对文件的索引节(INode),大小(Size)和最后修改时间(MTime)进行Hash后得到的。
或304。
既生Last-Modified何生Etag?
你可能会觉得使用Last-Modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要Etag(实体标识)呢?HTTP1.1中Etag的出现主要是为了解决几个Last-Modified比较难解决的问题:
秒钟以内,被修改多次的话,它将不能准确标注文件的修改时间
l 如果某些文件会被定期生成,当有时内容并没有任何变化,但Last-Modified却改变了,导致文件没法使用缓存
l 有可能存在服务器没有准确获取文件修改时间,或者与代理服务器时间不一致等情形
。
用户行为与缓存
浏览器缓存行为还有用户的行为有关!!!
|
用户操作 |
Expires/Cache-Control |
Last-Modified/Etag |
|
地址栏回车 |
有效 |
有效 |
|
页面链接跳转 |
有效 |
有效 |
|
新开窗口 |
有效 |
有效 |
|
前进、后退 |
有效 |
有效 |
|
F5刷新 |
无效 |
有效 |
|
Ctrl+F5刷新 |
无效 |
无效 |
总结
浏览器第一次请求:

浏览器再次请求时:
浏览器缓存机制<转>的更多相关文章
- Java缓存学习之二:浏览器缓存机制
浏览器端的九种缓存机制介绍 浏览器缓存是浏览器端保存数据用于快速读取或避免重复资源请求的优化机制,有效的缓存使用可以避免重复的网络请求和浏览器快速地读取本地数据,整体上加速网页展示给用户.浏览器端缓存 ...
- 详解浏览器缓存机制与Apache设置缓存
一.详解浏览器缓存机制 对于,如何说明缓存机制,在网络上找到了两张图,个人认为思路是比较清晰的.总结时,上图. 这里需要注意的有两点: 1.Last-Modified.Etag是响应头里的数据 2.I ...
- atitit。浏览器缓存机制 and 微信浏览器防止缓存的设计 attilax 总结
atitit.浏览器缓存机制 and 微信浏览器防止缓存的设计 attilax 总结 1. 缓存的一些机制 1 1.1. http 304 1 1.2. 浏览器刷新的处理机制 1 1.3. Expir ...
- WEB请求过程(http解析,浏览器缓存机制,域名解析,cdn分发)
概述 发起一个http请求的过程就是建立一个socket通信的过程. 我们可以模仿浏览器发起http请求,譬如用httpclient工具包,curl命令等方式. curl "http://w ...
- HTTP浏览器缓存机制
来自:http://kb.cnblogs.com/page/165307/ 浏览器缓存机制 浏览器缓存机制,其实主要就是HTTP协议定义的缓存机制(如: Expires: Cache-control等 ...
- HTTP 协议 -- 浏览器缓存机制
浏览器缓存机制 浏览器缓存机制主要是 HTTP 协议定义的缓存机制. HTTP 协议中有关缓存的缓存信息头的关键字有 Cache-Control,Pragma,Expires,Last-Modifie ...
- <转>浏览器缓存机制
本篇博客转载自github,原文地址:浏览器缓存篇 前言 在前端开发中,缓存有利于加快网页的加载速度,同时缓存能够被反复利用,所以可以减少流量和带宽的开销. 缓存的分类有很多种,CDN缓存.数据库缓存 ...
- 浏览器缓存机制介绍 + 常用 http 状态码
浏览器缓存分为两种, 强制缓存 与 协商缓存, https://www.pass4lead.com/300-209.htmlhttps://www.pass4lead.com/300-320.ht ...
- http报文和浏览器缓存机制
目录 1. 请求报文 1.1请求行 1.2 请求头 一些常用的请求头信息 2. 响应报文 2.1 状态行 1> 响应状态码 2> 常见的响应状态码 2.2 响应头 3. 浏览器缓存 3.1 ...
随机推荐
- LAMP环境的搭建(四)----Apache下部署项目
根据前文完成了LAMP基本环境的安装,那么接下来就是部署线上的环境了. yum 安装的apache 目录存在于 /etc/httpd apache最重要的文件就是 httpd.conf. 目录再 ...
- Vue-上拉加载与下拉刷新(mint-ui:loadmore)一个页面使用多个上拉加载后冲突问题
所遇问题: 该页面为双选项卡联动,四个部分都需要上拉加载和下拉刷新功能,使用的mint-ui的loadmore插件,分别加上上拉加载后,只有最后一个的this.$refs.loadmore.onTop ...
- 一个页面多个iframe赋值
先在页面上设置一个元素: <input type="hidden" id="content" value={$content}> 使用前端技术获取父 ...
- jQuery遍历-祖先
祖先是父.祖父或曾祖父等等. 通过 jQuery,您能够向上遍历 DOM 树,以查找元素的祖先. 向上遍历 DOM 树 这些 jQuery 方法很有用,它们用于向上遍历 DOM 树: parent() ...
- 【详细资料】ICN6211:MIPI DSI转RGB芯片简介
ICN6211功能MIPI DSI转RGB,分辨率1920*1200,封装QFN48
- django文件上传
-------------------上传图片-------------------1.model中定义属性类型为models.ImageField类型 pic=models.ImageField(u ...
- sed修炼系列(三):sed高级应用之实现窗口滑动技术
html { font-family: sans-serif } body { margin: 0 } article,aside,details,figcaption,figure,footer,h ...
- java锁机制
2.4 锁机制 临界区是指,使用同一个锁控制的同一段代码区或多段代码区之间,在同一时间内最多只能有一个线程在执行操作.这个概念与传统的临界区有略微的差别,这里不想强调这些概念上的差别,临 ...
- [C#] 分布式ID自增算法 Snowflake
最近在尝试EF的多数据库移植,但是原始项目中主键用的Sqlserver的GUID.MySQL没法移植了. 其实发现GUID也没法保证数据的递增性,又不太想使用int递增主键,就开始探索别的ID形式. ...
- 正则语言引擎:一个简单LEX和YACC结合运用的实例
本文先描述了LEX与YACC的书写方法.然后利用LEX与YACC编写了一个简单正则语言的引擎(暂时不支持闭包与或运算),生成的中间语言为C语言. 正则引擎应直接生成NFA或DFA模拟器的输入文件,但在 ...