机器学习之三:logistic回归(最优化)
一般来说,回归不用在分类问题上,因为回归是连续型模型,而且受噪声影响比较大。如果非要应用进入,可以使用logistic回归。
logistic回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数g(z)将最为假设函数来预测。g(z)可以将连续值映射到0和1上。
logistic回归的假设函数如下,线性回归假设函数只是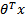 。
。
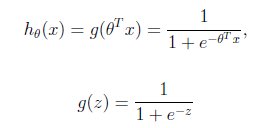
logistic回归用来分类0/1问题,也就是预测结果属于0或者1的二值分类问题。这里假设了二值满足伯努利分布,也就是
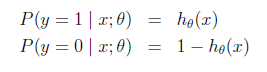
当然假设它满足泊松分布、指数分布等等也可以,只是比较复杂,后面会提到线性回归的一般形式。
求最大似然估计,然后求导,得到迭代公式结果为
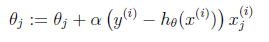
可以看到与线性回归类似,只是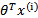 换成了
换成了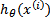 ,而
,而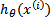 实际上就是
实际上就是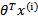 经过g(z)映射过来的。
经过g(z)映射过来的。
Logistic回归:实际上属于判别分析,因拥有很差的判别效率而不常用。
1. 应用范围:
① 适用于流行病学资料的危险因素分析
② 实验室中药物的剂量-反应关系
③ 临床试验评价
④ 疾病的预后因素分析
2. Logistic回归的分类:
① 按因变量的资料类型分:
二分类
多分类
其中二分较为常用
② 按研究方法分:
条 件Logistic回归
非条件Logistic回归
两者针对的资料类型不一样,后者针对成组研究,前者针对配对或配伍研究。
3.Logistic回归的应用条件是:
① 独立性。各观测对象间是相互独立的;
② LogitP与自变量是线性关系;
③ 样本量。经验值是病例对照各50例以上或为自变量的5-10倍(以10倍为宜),不过随着统计技术和软件的发展,样本量较小或不能进行似然估计的情况下可采用精确logistic回归分析,此时要求分析变量不能太多,且变量分类不能太多;
④ 当队列资料进行logistic回归分析时,观察时间应该相同,否则需考虑观察时间的影响(建议用Poisson回归)。
4. 拟和logistic回归方程的步骤:
① 对每一个变量进行量化,并进行单因素分析;
② 数据的离散化,对于连续性变量在分析过程中常常需要进行离散变成等级资料。可采用的方法有依据经验进行离散,或是按照四分、五分位数法来确定等级,也可采用聚类方法将计量资料聚为二类或多类,变为离散变量。
③ 对性质相近的一些自变量进行部分多因素分析,并探讨各自变量(等级变量,数值变量)纳入模型时的适宜尺度,及对自变量进行必要的变量变换;
④ 在单变量分析和相关自变量分析的基础上,对P≤α(常取0.2,0.15或0.3)的变量,以及专业上认为重要的变量进行多因素的逐步筛选;模型程序每拟合一个模型将给出多个指标值,供用户判断模型优劣和筛选变量。可以采用双向筛选技术:a进入变量的筛选用score统计量或G统计量或LRS(似然比统计量),用户确定P值临界值如:0.05、0.1或0.2,选择统计量显著且最大的变量进入模型;b剔除变量的选择用Z统计量(Wald统计量),用户确定其P值显著性水平,当变量不显者,从模型中予以剔除。这样,选入和剔除反复循环,直至无变量选入,也无变量删除为止,选入或剔除的显著界值的确定要依具体的问题和变量的多寡而定,一般地,当纳入模型的变量偏多,可提高选入界值或降低剔除标准,反之,则降低选入界值、提高删除标准。但筛选标准的不同会影响分析结果,这在与他人结果比较时应当注意。
⑤ 在多因素筛选模型的基础上,考虑有无必要纳入变量的交互作用项;两变量间的交互作用为一级交互作用,可推广到二级或多级交互作用,但在实际应用中,各变量最好相互独立(也是模型本身的要求),不必研究交互作用,最多是研究少量的一级交互作用。
⑥ 对专业上认为重要但未选入回归方程的要查明原因。
5. 回归方程拟合优劣的判断(为线性回归方程判断依据,可用于logistic回归分析)
① 决定系数(R2)和校正决定系数(  ),可以用来评价回归方程的优劣。R2随着自变量个数的增加而增加,所以需要校正;校正决定系数( )越大,方程越优。但亦有研究指出R2是多元线性回归中经常用到的一个指标,表示的是因变量的变动中由模型中自变量所解释的百分比,并不涉及预测值与观测值之间差别的问题,因此在logistic回归中不适合。
),可以用来评价回归方程的优劣。R2随着自变量个数的增加而增加,所以需要校正;校正决定系数( )越大,方程越优。但亦有研究指出R2是多元线性回归中经常用到的一个指标,表示的是因变量的变动中由模型中自变量所解释的百分比,并不涉及预测值与观测值之间差别的问题,因此在logistic回归中不适合。
② Cp选择法:选择Cp最接近p或p+1的方程(不同学者解释不同)。Cp无法用SPSS直接计算,可能需要手工。1964年CL Mallows提出:

Cp接近(p+1)的模型为最佳,其中p为方程中自变量的个数,m为自变量总个数。
③ AIC准则:1973年由日本学者赤池提出AIC计算准则,AIC越小拟合的方程越好。

在logistic回归中,评价模型拟合优度的指标主要有Pearson χ2、偏差(deviance)、Hosmer- Lemeshow (HL)指标、Akaike信息准则(AIC)、SC指标等。Pearson χ2、偏差(deviance)主要用于自变量不多且为分类变量的情况,当自变量增多且含有连续型变量时,用HL指标则更为恰当。Pearson χ2、偏差(deviance)、Hosmer- Lemeshow (HL)指标值均服从χ2分布,χ2检验无统计学意义(P>0.05)表示模型拟合的较好,χ2检验有统计学意义(P≤0.05)则表示模型拟合的较差。AIC和SC指标还可用于比较模型的优劣,当拟合多个模型时,可以将不同模型按其AIC和SC指标值排序,AIC和SC值较小者一般认为拟合得更好。
6. 拟合方程的注意事项:
① 进行方程拟合对自变量筛选采用逐步选择法[前进法(forward)、后退法(backward)、逐步回归法(stepwise)]时,引入变量的检验水准要小于或等于剔除变量的检验水准;
② 小样本检验水准α定为0.10或0.15,大样本把α定为0.05。值越小说明自变量选取的标准越严;
③ 在逐步回归的时可根据需要放宽或限制进入方程的标准,或硬性将最感兴趣的研究变量选入方程;
④ 强影响点记录的选择:从理论上讲,每一个样本点对回归模型的影响应该是同等的,实际并非如此。有些样本点(记录)对回归模型影响很大。对由过失或错误造成的点应删去,没有错误的强影响点可能和自变量与应变量的相关有关,不可轻易删除。
⑤ 多重共线性的诊断(SPSS中的指标):a容许度:越近似于0,共线性越强;b特征根:越近似于0,共线性越强;c条件指数:越大,共线性越强;
⑥ 异常点的检查:主要包括特异点(outher)、高杠杆点(high leverage points)以及强影响点(influential points)。特异点是指残差较其他各点大得多的点;高杠杆点是指距离其他样品较远的点;强影响点是指对模型有较大影响的点,模型中包含该点与不包含该点会使求得的回归系数相差很大。单独的特异点或高杠杆点不一定会影响回归系数的估计,但如果既是特异点又是高杠杆点则很可能是一个影响回归方程的“有害”点。对特异点、高杠杆点、强影响点诊断的指标有Pearson残差、Deviance残差、杠杆度统计量H(hat matrix diagnosis)、Cook 距离、DFBETA、Score检验统计量等。这五个指标中,Pearson残差、Deviance残差可用来检查特异点,如果某观测值的残差值>2,则可认为是一个特异点。杠杆度统计量H可用来发现高杠杆点, H值大的样品说明距离其他样品较远,可认为是一个高杠杆点。Cook 距离、DFBETA指标可用来度量特异点或高杠杆点对回归模型的影响程度。Cook距离是标准化残差和杠杆度两者的合成指标,其值越大,表明所对应的观测值的影响越大。DFBETA指标值反映了某个样品被删除后logistic回归系数的变化,变化越大(即DFBETA指标值越大),表明该观测值的影响越大。如果模型中检查出有特异点、高杠杆点或强影响点,首先应根据专业知识、数据收集的情况,分析其产生原因后酌情处理。如来自测量或记录错误,应剔除或校正,否则处置就必须持慎重态度,考虑是否采用新的模型,而不能只是简单地删除就算完事。因为在许多场合,异常点的出现恰好是我们探测某些事先不清楚的或许更为重要因素的线索。
7. 回归系数符号反常与主要变量选不进方程的原因:
① 存在多元共线性;
② 有重要影响的因素未包括在内;
③ 某些变量个体间的差异很大;
④ 样本内突出点上数据误差大;
⑤ 变量的变化范围较小;
⑥ 样本数太少。
8. 参数意义
① Logistic回归中的常数项(b0)表示,在不接触任何潜在危险/保护因素条件下,效应指标发生与不发生事件的概率之比的对数值。
② Logistic回归中的回归系数(bi)表示,其它所有自变量固定不变,某一因素改变一个单位时,效应指标发生与不发生事件的概率之比的对数变化值,即OR或RR的对数值。需要指出的是,回归系数β的大小并不反映变量对疾病发生的重要性,那么哪种因素对模型贡献最大即与疾病联系最强呢? (InL(t-1)-InL(t))三种方法结果基本一致。
③ 存在因素间交互作用时,Logistic回归系数的解释变得更为复杂,应特别小心。
④ 模型估计出OR,当发病率较低时,OR≈RR,因此发病率高的疾病资料不适合使用该模型。另外,Logistic模型不能利用随访研究中的时间信息,不考虑发病时间上的差异,因而只适于随访期较短的资料,否则随着随访期的延长,回归系数变得不稳定,标准误增加。
9. 统计软件
能够进行logistic回归分析的软件非常多,常用的有SPSS、SAS、Stata、EGRET (Epidemiological Graphics Estimation and Testing Package)等。
参考:
http://blog.163.com/ping_zhg/blog/static/6797537220113581247320/
http://blog.csdn.net/statdm/article/details/7585153
机器学习之三:logistic回归(最优化)的更多相关文章
- [机器学习实战-Logistic回归]使用Logistic回归预测各种实例
目录 本实验代码已经传到gitee上,请点击查收! 一.实验目的 二.实验内容与设计思想 实验内容 设计思想 三.实验使用环境 四.实验步骤和调试过程 4.1 基于Logistic回归和Sigmoid ...
- 机器学习之logistic回归算法与代码实现原理
Logistic回归算法原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10033567.html ...
- 机器学习之Logistic 回归算法
1 Logistic 回归算法的原理 1.1 需要的数学基础 我在看机器学习实战时对其中的代码非常费解,说好的利用偏导数求最值怎么代码中没有体现啊,就一个简单的式子:θ= θ - α Σ [( hθ( ...
- 机器学习5—logistic回归学习笔记
机器学习实战之logistic回归 test5.py #-*- coding:utf-8 import sys sys.path.append("logRegres.py") fr ...
- 机器学习基础-Logistic回归1
利用Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类. 训练分类器时的做法就是寻找最佳拟合参数,使用的时最优化算法. 优点:计算代价不高,利于理解和实现. ...
- 吴裕雄--天生自然python机器学习:Logistic回归
假设现在有一些数据点,我们用 一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作回归.利用Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类 ...
- 机器学习笔记—Logistic回归
本文申明:本系列笔记全部为原创内容,如有转载请申明原地址出处.谢谢 序言:what is logistic regression? Logistics 一词表示adj.逻辑的;[军]后勤学的n.[逻] ...
- 机器学习笔记—Logistic 回归
前面我们介绍了线性回归,为捕获训练集中隐藏的线性模型,提高预测准确率,我们寻找最佳参数 θ,使得预测值与真实值误差尽量小,也就是使均方误差最小.而经过验证,最小均方误差是符合最大似然估计理论的. 在 ...
- 机器学习算法-logistic回归算法
Logistic回归算法调试 一.算法原理 Logistic回归算法是一种优化算法,主要用用于只有两种标签的分类问题.其原理为对一些数据点用一条直线去拟合,对数据集进行划分.从广义上来讲这也是一种多元 ...
随机推荐
- Maven搭建SpringMVC+MyBatis+Json项目(多模块项目)
一.开发环境 Eclipse:eclipse-jee-luna-SR1a-win32; JDK:jdk-8u121-windows-i586.exe; MySql:MySQL Server 5.5; ...
- Linux Ubuntu从零开始部署web环境及项目 -----部署项目 (三)
上一篇讲了如何在linux搭建web环境,这边将如何部署项目. 1,打包项目包 2,上传项目包 将.war项目包通过xftp上传到tomcat目录wabapps目录下 3,启动项目 通过xshell命 ...
- Django查询数据库性能优化
现在有一张记录用户信息的UserInfo数据表,表中记录了10个用户的姓名,呢称,年龄,工作等信息. models文件 from django.db import models class Job(m ...
- 利用原生js制做数据管理平台,适合初学者学习
摘要:数据管理平台在当今社会中运用十分广泛,我们在应用过程中,要对数据进行存储,管理,以及删除查询等操作,而我们在实际设计的时候,大牛们大多用到的是JQuery,而小白对jq理解也较困难,为了让大家回 ...
- javascript插入before(),after()新DOM方法
随着web的技术突飞猛进的发展.HTML5 ES6等新技术的发展,与此同时DOM等标准也在悄悄的进步,各大浏览器也在悄悄的发展适配新的属性和方法,今天我们来看看Javascript新的DOM的方法 二 ...
- 01.python基础知识_01
一.编译型语言和解释型语言的区别是什么? 1.编译型语言将源程序全部编译成机器码,并把结果保存为二进制文件.运行时,直接使用编译好的文件即可 2.解释型语言只在执行程序时,才一条一条的解释成机器语言给 ...
- win32多线程编程
关于多线程多进程的学习,有没有好的书籍我接触的书里头关于多线程多进程部分,一是<操作系统原理>里面讲的相关概念 一个是<linux基础教程>里面讲的很简单的多线程多进程编程 ...
- (转)深度学习word2vec笔记之基础篇
深度学习word2vec笔记之基础篇 声明: 1)该博文是多位博主以及多位文档资料的主人所无私奉献的论文资料整理的.具体引用的资料请看参考文献.具体的版本声明也参考原文献 2)本文仅供学术交流,非商用 ...
- 平稳切换nginx版本
html { font-family: sans-serif } body { margin: 0 } article,aside,details,figcaption,figure,footer,h ...
- 学习PID
最近在想自己的文章有些是不是写的太难以理解了呢.........竟然好多人看了还是会直接问我很多问题....... 其实PID哈靠自己想像就能自己写出来自己的代码,也许是网上的讲的太过的高深什么积分微 ...