爬虫新手学习2-爬虫进阶(urllib和urllib2 的区别、url转码、爬虫GET提交实例、批量爬取贴吧数据、fidder软件安装、有道翻译POST实例、豆瓣ajax数据获取)
1、urllib和urllib2区别实例
urllib和urllib2都是接受URL请求相关模块,但是提供了不同的功能,两个最显著的不同如下:
urllib可以接受URL,不能创建设置headers的Request类实例,urlib2可以。
url转码
https://www.baidu.com/s?wd=%E5%AD%A6%E7%A5%9E
python字符集解码加码过程:
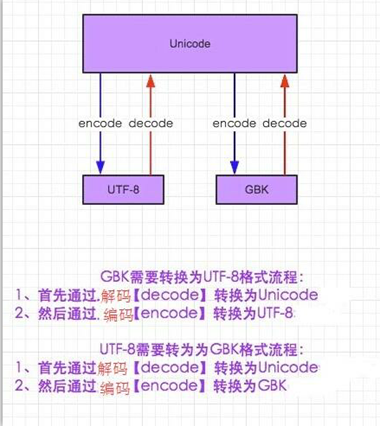
2.爬虫GET提交实例
#coding:utf-8 import urllib #负责url编码处理
import urllib2 url = "https://www.baidu.com/s"
word = {"wd": "繁华"}
word = urllib.urlencode(word) #转换成url编码格式(字符串)
newurl = url + "?" + word headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} request = urllib2.Request(newurl, headers=headers) response = urllib2.urlopen(request) print response.read()
#coding:utf-8 import urllib #负责url编码处理
import urllib2 url = "https://www.baidu.com/s"
word = {"wd": "咖菲猫"}
word = urllib.urlencode(word) #转换成url编码格式(字符串)
newurl = url + "?" + word headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} request = urllib2.Request(newurl, headers=headers) response = urllib2.urlopen(request) print response.read()
自定义爬虫GET提交实例
#coding:utf-8 import urllib #负责url编码处理
import urllib2 url = "https://www.baidu.com/s"
keyword = raw_input("请输入要查询的关键字:")
word = {"wd": keyword}
word = urllib.urlencode(word) #转换成url编码格式(字符串)
newurl = url + "?" + word headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} request = urllib2.Request(newurl, headers=headers) response = urllib2.urlopen(request) print response.read()
3.批量爬取贴吧页面数据
分析贴吧URL
http://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F
pn递增50为一页
0为第一页
http://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&pn=0
50为第二页
http://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&pn=50
100为第三页
http://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&pn=100
批量爬贴吧实例
#coding:utf-8 import urllib
import urllib2 def loadPage(url, filename):
'''
作用:根据url发送请求, 获取服务器响应文件
url:需要爬取的url地址
filename:文件名
''' print "正在下载" + filename headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} request = urllib2.Request(url, headers = headers)
response = urllib2.urlopen(request)
return response.read() def writeFile(html, filename):
'''
作用:保存服务器相应文件到本地硬盘文件里
html:服务器相应文件
filename:本地磁盘文件名
''' print "正在存储" + filename
with open(unicode(filename, 'utf-8'), 'w') as f:
f.write(html)
print "-" * 20 def tiebaSpider(url, beginPage, endPage, name):
'''
作用:负责处理url,分配每个url去发送请求
url:需要处理的第一个url
beginPage:爬虫执行的起始页面
endPage:爬虫执行的截止页面
'''
for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50 filename = "第" + name + "-" + str(page) + "页.html"
#组合为完整的url,并且pn值每次增加50
fullurl = url + "&pn=" + str(pn)
#print fullurl #调用loadPage()发送请求获取HTML页面
html = loadPage(fullurl, filename)
#将获取到的HTML页面写入本地磁盘文件
writeFile(html, filename) #模拟main函数"
if __name__ == "__main__":
kw = raw_input("请输入需要爬取的贴吧:")
beginPage = int(raw_input("请输入起始页:"))
endPage = int(raw_input("请输入终止页:")) url = "http://tieba.baidu.com/f?"
key = urllib.urlencode({"kw": kw}) #组合后的url示例:http://tieba.baidu.com/f?kw=绝地求生
newurl = url + key
tiebaSpider(newurl, beginPage, endPage, kw)
4.Fidder使用安装
下载fidder
安装后,照下图设置

5.有道翻译POST分析
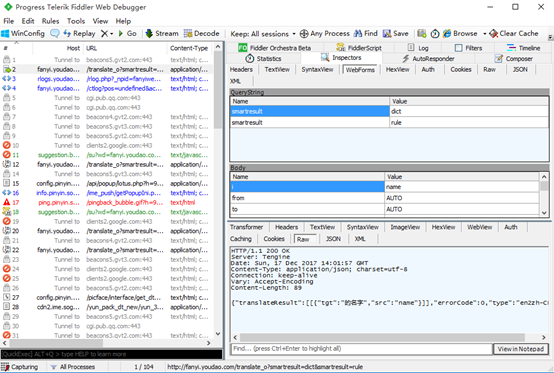
调用有道翻译POST API实例
#coding:utf-8 import urllib
import urllib2 #通过抓包的方式获取的url,并不是浏览器上显示的url
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null" #完整的headers
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Origin": "http://fanyi.youdao.com",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8"
} #用户接口输入
key = raw_input("请输入需要翻译的英文单词:") #发送到web服务器的表单数据
formdata = {
"i": key,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": "",
"sign": "29e3219b8c4e75f76f6e6aba0bb3c4b5",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTIME",
"typoResult": "false"
} #经过urlencode转码
data = urllib.urlencode(formdata) #如果Request()方法里的data参数有值,那么这个请求就是POST
#如果没有,就是Get
request = urllib2.Request(url, data= data, headers= headers) print urllib2.urlopen(request).read()
6.Ajax加载方式的数据获取
豆瓣分析Ajax
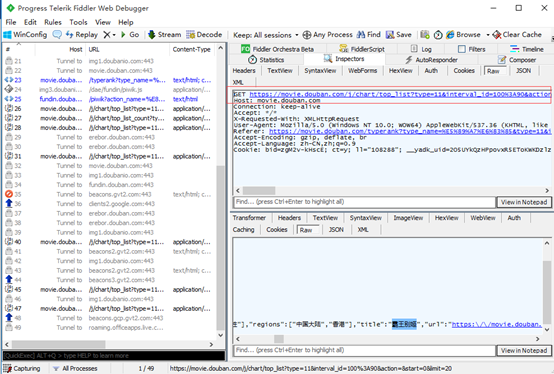
爬取豆瓣电影排行信息实例
#coding:utf-8 import urllib2
import urllib url = "https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=" headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} formdata = {
"start": "",
"limit": ""
} data = urllib.urlencode(formdata) request = urllib2.Request(url, data = data, headers = headers) print urllib2.urlopen(request).read()
爬虫新手学习2-爬虫进阶(urllib和urllib2 的区别、url转码、爬虫GET提交实例、批量爬取贴吧数据、fidder软件安装、有道翻译POST实例、豆瓣ajax数据获取)的更多相关文章
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- python爬虫25 | 爬取下来的数据怎么保存? CSV 了解一下
大家好 我是小帅b 是一个练习时长两年半的练习生 喜欢 唱! 跳! rap! 篮球! 敲代码! 装逼! 不好意思 我又走错片场了 接下来的几篇文章 小帅b将告诉你 如何将你爬取到的数据保存下来 有文本 ...
- Python爬虫:爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫——request实例:爬取网易云音乐华语男歌手top10歌曲
requests是python的一个HTTP客户端库,跟urllib,urllib2类似,但比那两个要简洁的多,至于request库的用法, 推荐一篇不错的博文:https://cuiqingcai. ...
- Python爬取招聘网站数据,给学习、求职一点参考
1.项目背景 随着科技的飞速发展,数据呈现爆发式的增长,任何人都摆脱不了与数据打交道,社会对于“数据”方面的人才需求也在不断增大.因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于 ...
- 4 urllib和urllib2的区别
4 urllib和urllib2的区别 这个面试官确实问过,当时答的urllib2可以Post而urllib不可以. urllib提供urlencode方法用来GET查询字符串的产生,而urllib2 ...
随机推荐
- RobotFramework自动化测试环境配置
现在工作是做自动化测试平台维护的,平台用的C#做的,主要是用来测试CMBRun项目,它是c/s结构的项目,而b/s结构的项目主要使用RF+Python来做.做这块之前听过自动化测试,身边的朋友也有做这 ...
- Spring面试题目
问题清单: 1. 什么是Spring框架?Spring框架有哪些主要模块? 2. 使用Spring框架有什么好处? 3. 什么是控制反转(IOC)?什么是依赖注入? 4. 请解释下Spring中的IO ...
- 【原创】使用workstation安装Xenserver 6.5+cloudstack 4.10----本地存储模式
1. 背景: 近期由于项目和个人学习得需求,开始接触到Cloudstack,虽然云计算概念在大学刚毕业的时候就已经略有耳闻,但是由于工作原因,也一直没有了解,下班后想自己折腾下cloudstack,便 ...
- git如何忽略文件
偶尔有一些文件你不想让git提交到代码配置库上,这里有一些方法可以告诉git,有哪些文件可以忽略. 创建一个本地的.gitignore 如果你在你的git库(repository)中创建了一个名为.g ...
- [转]Oracle 索引质量分析
http://blog.csdn.net/leshami/article/details/23687137 索引质量的高低对数据库整体性能有着直接的影响.良好高质量的索引使得数据库性能得以数量级别的提 ...
- 基础拾遗-----mongoDB操作
基础拾遗 基础拾遗------特性详解 基础拾遗------webservice详解 基础拾遗------redis详解 基础拾遗------反射详解 基础拾遗------委托详解 基础拾遗----- ...
- 在windows上搭建镜像yum站的方法(附bat脚本)
方法一:支持rsync的网站 对于常用的centos.Ubuntu.等使用官方yum源在 http://mirrors.ustc.edu.cn 都存在镜像. 同时 http://mirrors.ust ...
- iOS 远程推送消息解析及逻辑处理
关于远程推送的相关配置网上已经有足够多的教程,这里就不复述了.这里讲述当客户端收到推送消息后,应怎样对其进行相应的逻辑处理. 工程的AppDelegate.m文件里提供了如下方法: //当应用程序启动 ...
- iOS11、iPhone X、Xcode9 适配
更新iOS11后,发现有些地方需要做适配,整理后按照优先级分为以下三类: 1.单纯升级iOS11后造成的变化: 2.Xcode9 打包后造成的变化: 3.iPhoneX的适配 一.单纯升级iOS11后 ...
- 状态压缩 - LeetCode #464 Can I Win
动态规划是一种top-down求解模式,关键在于分解和求解子问题,然后根据子问题的解不断向上递推,得出最终解 因此dp涉及到保存每个计算过的子问题的解,这样当遇到同样的子问题时就不用继续向下求解而直接 ...