Slim Span(Kruskal)
| Time Limit: 5000MS | Memory Limit: 65536K | |
| Total Submissions: 7227 | Accepted: 3831 |
Description
Given an undirected weighted graph G, you should find one of spanning trees specified as follows.
The graph G is an ordered pair (V, E), where V is a set of vertices {v1, v2, …, vn} and E is a set of undirected edges {e1, e2, …, em}. Each edge e ∈E has its weight w(e).
A spanning tree T is a tree (a connected subgraph without cycles) which connects all the n vertices with n − 1 edges. The slimness of a spanning tree Tis defined as the difference between the largest weight and the smallest weight among the n − 1 edges of T.
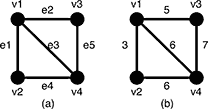
Figure 5: A graph G and the weights of the edges
For example, a graph G in Figure 5(a) has four vertices {v1, v2, v3, v4} and five undirected edges {e1, e2, e3, e4, e5}. The weights of the edges arew(e1) = 3, w(e2) = 5, w(e3) = 6, w(e4) = 6, w(e5) = 7 as shown in Figure 5(b).
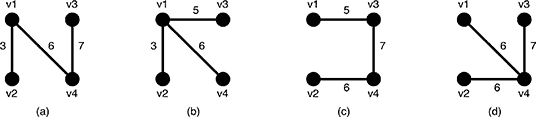
Figure 6: Examples of the spanning trees of G
There are several spanning trees for G. Four of them are depicted in Figure 6(a)~(d). The spanning tree Ta in Figure 6(a) has three edges whose weights are 3, 6 and 7. The largest weight is 7 and the smallest weight is 3 so that the slimness of the tree Ta is 4. The slimnesses of spanning trees Tb,Tc and Td shown in Figure 6(b), (c) and (d) are 3, 2 and 1, respectively. You can easily see the slimness of any other spanning tree is greater than or equal to 1, thus the spanning tree Td in Figure 6(d) is one of the slimmest spanning trees whose slimness is 1.
Your job is to write a program that computes the smallest slimness.
Input
The input consists of multiple datasets, followed by a line containing two zeros separated by a space. Each dataset has the following format.
| n | m | |
| a1 | b1 | w1 |
| ⋮ | ||
| am | bm | wm |
Every input item in a dataset is a non-negative integer. Items in a line are separated by a space. n is the number of the vertices and m the number of the edges. You can assume 2 ≤ n ≤ 100 and 0 ≤ m ≤ n(n − 1)/2. ak and bk (k = 1, …, m) are positive integers less than or equal to n, which represent the two vertices vak and vbk connected by the kth edge ek. wk is a positive integer less than or equal to 10000, which indicates the weight of ek. You can assume that the graph G = (V, E) is simple, that is, there are no self-loops (that connect the same vertex) nor parallel edges (that are two or more edges whose both ends are the same two vertices).
Output
For each dataset, if the graph has spanning trees, the smallest slimness among them should be printed. Otherwise, −1 should be printed. An output should not contain extra characters.
Sample Input
4 5
1 2 3
1 3 5
1 4 6
2 4 6
3 4 7
4 6
1 2 10
1 3 100
1 4 90
2 3 20
2 4 80
3 4 40
2 1
1 2 1
3 0
3 1
1 2 1
3 3
1 2 2
2 3 5
1 3 6
5 10
1 2 110
1 3 120
1 4 130
1 5 120
2 3 110
2 4 120
2 5 130
3 4 120
3 5 110
4 5 120
5 10
1 2 9384
1 3 887
1 4 2778
1 5 6916
2 3 7794
2 4 8336
2 5 5387
3 4 493
3 5 6650
4 5 1422
5 8
1 2 1
2 3 100
3 4 100
4 5 100
1 5 50
2 5 50
3 5 50
4 1 150
0 0
Sample Output
1
20
0
-1
-1
1
0
1686
50
介绍一下kruskal算法:
这个算法是基于并查集的,每次从图中未加入树种的边种找到边权最小的看,这两个点的祖先是否是一个,如果是一个说明两个点已经是一个树上的了,不做操作,如果两个点来自不同的树即有不同的祖先,那么就把这两个点所代表的两个树合并起来,最后当所有的点都在一棵树上的时候停止操作,一般用合并次数来控制,即n个点需要合并n-1次,所以最好合并操作写在kruskal函数内部,这样方便统计步数
下面是这个题的代码,一定要 注意点的编号是从1开始还是从0开始,wa了好多次
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
const int N = ;
const int INF = ;
struct Edge{
int from;
int to;
int w;
bool operator < (const Edge &a) const
{
return w<a.w;
}
}edge[N*N];
int fa[N];
int Getfa(int x){return (fa[x]==x)?x:fa[x] = Getfa(fa[x]); }
int fl;
int n,m;
bool solve(int x){
int cnt = ;//共合n-1次结束
for(int i = ; i <= n; i++) fa[i] = i;//注意点是从1开始编号的
for(int i = x; i < m; i++){
int X = Getfa(edge[i].from);
int Y = Getfa(edge[i].to);
if(X != Y){
fa[X] = Y;
cnt++;
if(cnt==n-){ fl = edge[i].w;return true;}
}
}
return false;
} int main()
{
while(~scanf("%d%d",&n,&m))
{
if(n==&&m==) return ;
for(int i = ; i < m; i++)
{
scanf("%d%d%d",&edge[i].from,&edge[i].to,&edge[i].w);
}
sort(edge,edge+m);
int ans = INF;
for(int i = ; i < m; i++){
if(solve(i)) ans = min(ans,fl-edge[i].w);
}
if(ans==INF) puts("-1");
else printf("%d\n",ans);
}
return ;
}
Slim Span(Kruskal)的更多相关文章
- UVA1395 Slim Span(kruskal)
题目:Slim Span UVA 1395 题意:给出一副无向有权图,求生成树中最小的苗条度(最大权值减最小权值),如果不能生成树,就输出-1: 思路:将所有的边按权值有小到大排序,然后枚举每一条边, ...
- UVALive-3887 Slim Span (kruskal)
题目大意:定义无向图生成树的最大边与最小边的差为苗条度,找出苗条度最小的生成树的苗条度. 题目分析:先将所有边按权值从小到大排序,在连续区间[L,R]中的边如果能构成一棵生成树,那么这棵树一定有最小的 ...
- POJ-3522 Slim Span(最小生成树)
Slim Span Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 8633 Accepted: 4608 Descrip ...
- Uva1395 POJ3522 Slim Span (最小生成树)
Description Given an undirected weighted graph G, you should find one of spanning trees specified as ...
- UVa 1395 Slim Span (最小生成树)
题意:给定n个结点的图,求最大边的权值减去最小边的权值最小的生成树. 析:这个和最小生成树差不多,从小到大枚举左端点,对于每一个左端点,再枚举右端点,不断更新最小值.挺简单的一个题. #include ...
- 最小生成树练习2(Kruskal)
两个BUG鸣翠柳,一行代码上西天... hdu4786 Fibonacci Tree(生成树)问能否用白边和黑边构成一棵生成树,并且白边数量是斐波那契数. 题解:分别优先加入白边和黑边,求出生成树能包 ...
- c/c++ 用克鲁斯卡尔(kruskal)算法构造最小生成树
c/c++ 用克鲁斯卡尔(kruskal)算法构造最小生成树 最小生成树(Minimum Cost Spanning Tree)的概念: 假设要在n个城市之间建立公路,则连通n个城市只需要n-1条线路 ...
- 最小生成树之克鲁斯卡尔(Kruskal)算法
学习最小生成树算法之前我们先来了解下 下面这些概念: 树(Tree):如果一个无向连通图中不存在回路,则这种图称为树. 生成树 (Spanning Tree):无向连通图G的一个子图如果是一颗包含G的 ...
- 克鲁斯卡尔(Kruskal)算法
概览 相比于普里姆算法(Prim算法),克鲁斯卡尔算法直接以边为目标去构建最小生成树.从按权值由小到大排好序的边集合{E}中逐个寻找权值最小的边来构建最小生成树,只要构建时,不会形成环路即可保证当边集 ...
随机推荐
- 排查程序死循环,死锁的方法 ——pstack
pstack命令可显示每个进程的栈跟踪,pstack $pid即可,pstack命令须由$pid进程的属主或者root运行. 这次出现cpu占比100%的情况,但看memory占比,并无异常,怀疑是某 ...
- rpm 命令详解
参考:http://www.cnblogs.com/xiaochaohuashengmi/archive/2011/10/08/2203153.html rpm是由红帽公司开发的软件包管理方式,使用r ...
- rabbitmq 启动报错
=============================================== 2017/10/24_第1次修改 ccb_warlock = ...
- python 算法学习部分代码记录篇章1
# -*- coding: utf-8 -*- # @Date : 2017-08-19 20:19:56 # @Author : lileilei '''那么算法和数据结构是什么呢,答曰兵法''' ...
- 6、投资的一些思考 - CEO之公司管理经验谈
对于投资,前面笔者写过一个文:IT人经济思维之投资 - 创业与投资系列文章 ,里面列举了笔者自己做过的投资方面的内容.今天就说说公司投资的一些思考问题. 公司投资的问题,笔者还是那句话:关键是找出适合 ...
- SqlServer Lock_Escalation
在今天的文章里,我想谈下SQL Server里锁升级(Lock Escalations).锁升级是SQL Server使用的优化技术,用来控制在SQL Server锁管理里把持锁的数量.我们首先用SQ ...
- pagelatch等待在tempdb的gsm页面上
Each data file has a gam page, sql will update it when allocate space in the file. Will see contenti ...
- kotlin的方言(语法糖)
概述 之前介绍了kotlin的快速入门,http://www.cnblogs.com/lizo/p/7231167.html 大多数还是参照java.kotlin中提供了更多更方便的语言特性 这个方言 ...
- ORM框架 EF - code first 的封装 优化一
上一节我们讲到对EF(EntityFramework)的初步封装,任何事情都不可能一蹴而就,通过大量的实际项目的实战,也发现了其中的各种问题.在这一章中,我们对上一章的EF_Helper_DG进行优化 ...
- python3之xml&ConfigParser&hashlib&Subprocess&logging模块
1.xml模块 XML 指可扩展标记语言(eXtensible Markup Language),标准通用标记语言的子集,是一种用于标记电子文件使其具有结构性的标记语言. XML 被设计用来传输和存储 ...