ELK 快速指南
Elastic 技术栈之快速入门
概念
ELK 是什么
ELK 是 elastic 公司旗下三款产品 ElasticSearch 、Logstash 、Kibana 的首字母组合。
ElasticSearch 是一个基于 Lucene 构建的开源,分布式,RESTful 搜索引擎。
Logstash 传输和处理你的日志、事务或其他数据。
Kibana 将 Elasticsearch 的数据分析并渲染为可视化的报表。
为什么使用 ELK ?
对于有一定规模的公司来说,通常会很多个应用,并部署在大量的服务器上。运维和开发人员常常需要通过查看日志来定位问题。如果应用是集群化部署,试想如果登录一台台服务器去查看日志,是多么费时费力。
而通过 ELK 这套解决方案,可以同时实现日志收集、日志搜索和日志分析的功能。
ELK 架构
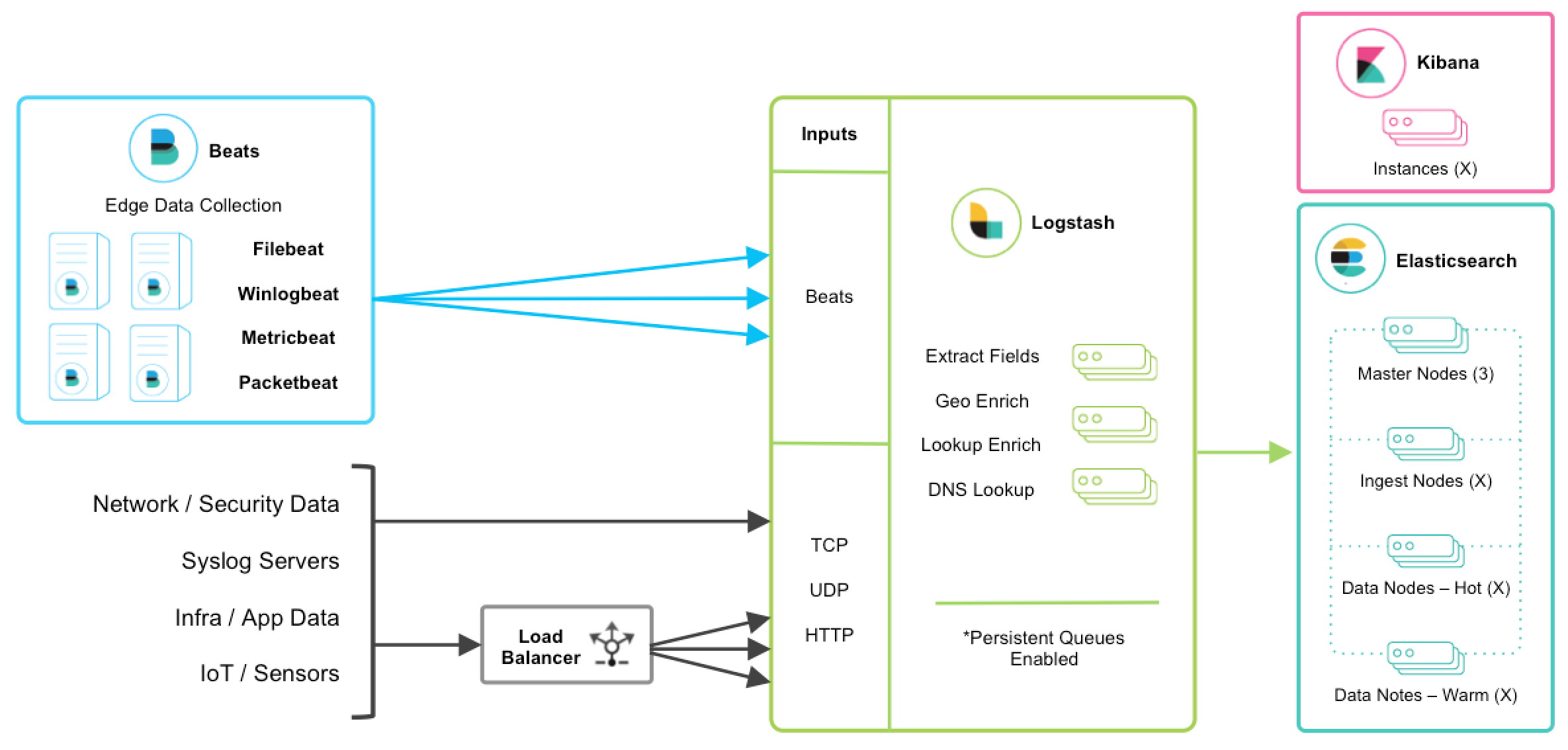
说明
以上是 ELK 技术栈的一个架构图。从图中可以清楚的看到数据流向。
Beats 是单一用途的数据传输平台,它可以将多台机器的数据发送到 Logstash 或 ElasticSearch。但 Beats 并不是不可或缺的一环,所以本文中暂不介绍。
Logstash 是一个动态数据收集管道。支持以 TCP/UDP/HTTP 多种方式收集数据(也可以接受 Beats 传输来的数据),并对数据做进一步丰富或提取字段处理。
ElasticSearch 是一个基于 JSON 的分布式的搜索和分析引擎。作为 ELK 的核心,它集中存储数据。
Kibana 是 ELK 的用户界面。它将收集的数据进行可视化展示(各种报表、图形化数据),并提供配置、管理 ELK 的界面。
安装
准备
ELK 要求本地环境中安装了 JDK 。如果不确定是否已安装,可使用下面的命令检查:
java -version
注意
本文使用的 ELK 是 6.0.0,要求 jdk 版本不低于 JDK8。
友情提示:安装 ELK 时,三个应用请选择统一的版本,避免出现一些莫名其妙的问题。例如:由于版本不统一,导致三个应用间的通讯异常。
Elasticsearch
安装步骤如下:
- elasticsearch 官方下载地址下载所需版本包并解压到本地。
- 运行
bin/elasticsearch(Windows 上运行bin\elasticsearch.bat) - 验证运行成功:linux 上可以执行
curl http://localhost:9200/;windows 上可以用访问 REST 接口的方式来访问 http://localhost:9200/
说明
Linux 上可以执行下面的命令来下载压缩包:
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.0.0.tar.gz
Mac 上可以执行以下命令来进行安装:
brew install elasticsearch
Windows 上可以选择 MSI 可执行安装程序,将应用安装到本地。
Logstash
安装步骤如下:
在 logstash 官方下载地址下载所需版本包并解压到本地。
添加一个
logstash.conf文件,指定要使用的插件以及每个插件的设置。举个简单的例子:input { stdin { } }
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
运行
bin/logstash -f logstash.conf(Windows 上运行bin/logstash.bat -f logstash.conf)
Kibana
安装步骤如下:
- 在 kibana 官方下载地址下载所需版本包并解压到本地。
- 修改
config/kibana.yml配置文件,设置elasticsearch.url指向 Elasticsearch 实例。 - 运行
bin/kibana(Windows 上运行bin\kibana.bat) - 在浏览器上访问 http://localhost:5601
安装 FAQ
elasticsearch 不允许以 root 权限来运行
问题:在 Linux 环境中,elasticsearch 不允许以 root 权限来运行。
如果以 root 身份运行 elasticsearch,会提示这样的错误:
can not run elasticsearch as root
解决方法:使用非 root 权限账号运行 elasticsearch
# 创建用户组
groupadd elk
# 创建新用户,-g elk 设置其用户组为 elk,-p elk 设置其密码为 elk
useradd elk -g elk -p elk
# 更改 /opt 文件夹及内部文件的所属用户及组为 elk:elk
chown -R elk:elk /opt # 假设你的 elasticsearch 安装在 opt 目录下
# 切换账号
su elk
vm.max_map_count 不低于 262144
问题:vm.max_map_count 表示虚拟内存大小,它是一个内核参数。elasticsearch 默认要求 vm.max_map_count 不低于 262144。
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决方法:
你可以执行以下命令,设置 vm.max_map_count ,但是重启后又会恢复为原值。
sysctl -w vm.max_map_count=262144
持久性的做法是在 /etc/sysctl.conf 文件中修改 vm.max_map_count 参数:
echo "vm.max_map_count=262144" > /etc/sysctl.conf
sysctl -p
注意
如果运行环境为 docker 容器,可能会限制执行 sysctl 来修改内核参数。
这种情况下,你只能选择直接修改宿主机上的参数了。
nofile 不低于 65536
问题: nofile 表示进程允许打开的最大文件数。elasticsearch 进程要求可以打开的最大文件数不低于 65536。
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
解决方法:
在 /etc/security/limits.conf 文件中修改 nofile 参数:
echo "* soft nofile 65536" > /etc/security/limits.conf
echo "* hard nofile 131072" > /etc/security/limits.conf
nproc 不低于 2048
问题: nproc 表示最大线程数。elasticsearch 要求最大线程数不低于 2048。
max number of threads [1024] for user [user] is too low, increase to at least [2048]
解决方法:
在 /etc/security/limits.conf 文件中修改 nproc 参数:
echo "* soft nproc 2048" > /etc/security/limits.conf
echo "* hard nproc 4096" > /etc/security/limits.conf
Kibana No Default Index Pattern Warning
问题:安装 ELK 后,访问 kibana 页面时,提示以下错误信息:
Warning No default index pattern. You must select or create one to continue.
...
Unable to fetch mapping. Do you have indices matching the pattern?
这就说明 logstash 没有把日志写入到 elasticsearch。
解决方法:
检查 logstash 与 elasticsearch 之间的通讯是否有问题,一般问题就出在这。
使用
本人使用的 Java 日志方案为 slf4j + logback,所以这里以 logback 来讲解。
Java 应用输出日志到 ELK
修改 logstash.conf 配置
首先,我们需要修改一下 logstash 服务端 logstash.conf 中的配置
input {
# stdin { }
tcp {
# host:port就是上面appender中的 destination,
# 这里其实把logstash作为服务,开启9250端口接收logback发出的消息
host => "127.0.0.1" port => 9250 mode => "server" tags => ["tags"] codec => json_lines
}
}
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
说明
这个 input 中的配置其实是 logstash 服务端监听 9250 端口,接收传递来的日志数据。
然后,在 Java 应用的 pom.xml 中引入 jar 包:
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>4.11</version>
</dependency>
接着,在 logback.xml 中添加 appender
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!--
destination 是 logstash 服务的 host:port,
相当于和 logstash 建立了管道,将日志数据定向传输到 logstash
-->
<destination>127.0.0.1:9250</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<logger name="io.github.dunwu.spring" level="TRACE" additivity="false">
<appender-ref ref="LOGSTASH" />
</logger>
大功告成,此后,io.github.dunwu.spring 包中的 TRACE 及以上级别的日志信息都会被定向输出到 logstash 服务。

资料
ELK 快速指南的更多相关文章
- [译] MongoDB Java异步驱动快速指南
导读 mongodb-java-driver是mongodb的Java驱动项目. 本文是对MongoDB-java-driver官方文档 MongoDB Async Driver Quick Tour ...
- 转:C++ Boost/tr1 Regex(正则表达式)快速指南
C++ Boost/tr1 Regex(正则表达式)快速指南 正则表达式自Boost 1.18推出,目前已经成为C++11(tr1)的标准部分. 本文以Boost 1.39正则表达式为基础,应该广泛适 ...
- Docker环境 ELK 快速部署
Docker环境 ELK快速部署 环境 Centos 7.4 , Docker version 17.12 Docker至少3GB内存: #内核配置 echo ' vm.max_map_count = ...
- (译)快速指南:用UIViewPropertyAnimator做动画
翻译自:QUICK GUIDE: ANIMATIONS WITH UIVIEWPROPERTYANIMATOR 译者:Haley_Wong iOS 10 带来了一大票有意思的新特性,像 UIViewP ...
- JUnit5 快速指南
JUnit5 快速指南 version: junit5 1. 安装 2. JUnit 注解 3. 编写单元测试 3.1. 基本的单元测试类和方法 3.2. 定制测试类和方法的显示名称 3.3. 断言( ...
- 【SFA官方翻译】使用 Kubernetes、Spring Boot 2.0 和 Docker 的微服务快速指南
[SFA官方翻译]使用 Kubernetes.Spring Boot 2.0 和 Docker 的微服务快速指南 原创: Darren Luo SpringForAll社区 今天 原文链接:https ...
- Emacs 快速指南(中文翻译)
Emacs 快速指南 目录 1. 小结(SUMMARY) 2. 基本的光标控制(BASIC CURSOR CONTROL) 3. 如果 EMACS 失去响应(IF EMACS STOPS RESP ...
- 29 A Quick Guide to Go's Assembler 快速指南汇编程序:使用go语言的汇编器简介
A Quick Guide to Go's Assembler 快速指南汇编程序:使用go语言的汇编器简介 A Quick Guide to Go's Assembler Constants Symb ...
- Emacs 快速指南 - 原生中文手册
Emacs 快速指南 -折叠目录 1. 小结(SUMMARY) 2. 基本的光标控制(BASIC CURSOR CONTROL) 3. 如果 EMACS 失去响应(IF EMACS STOPS RES ...
随机推荐
- Linux系列教程(一)——Linux系统简介
本系列教程将完整的讲解整个Linux相关的知识,这是楼主学完之后重新对Linux知识体系的整理.从最基础的知识开始,对于一个完全不懂Linux系统的人,相信在看完整个系列教程之后,都能对Linux有一 ...
- C# 6.0 $"Hello {csdn}"
"hello $world"的格式化字符串是指把字符串中一个单词,以一个标示开头.可以代换为单词所指的变量. 这个在jq有,而C#string的格式只能用格式的字符占位符,格式的字 ...
- Gradle sync failed 异常
今天开发过程中出现如下异常 Gradle sync failed: Connection timed out: connect. If you are behind an HTTP proxy, pl ...
- Redis 学习笔记-5种数据类型的基本操作
1.string类型 基本操作列表: GET 获取指定键对应的值 SET 设定键值 DEL 删除指定键对应的值(对所有数据类型都有效) > set hello world OK > get ...
- zookeeper 笔记-ACL
zookeeper中,znode的ACL是没有继承关系的,是独立控制的,zookeeper的acl可以从3个维度理解,一是scheme,二是user,三是permission,通常表示为scheme: ...
- Hadoop Streaming详解
一: Hadoop Streaming详解 1.Streaming的作用 Hadoop Streaming框架,最大的好处是,让任何语言编写的map, reduce程序能够在hadoop集群上运行:m ...
- Keras学习环境配置-GPU加速版(Ubuntu 16.04 + CUDA8.0 + cuDNN6.0 + Tensorflow)
本文是个人对Keras深度学习框架配置的总结,不周之处请指出,谢谢! 1. 首先,我们需要安装Ubuntu操作系统(Windows下也行),这里使用Ubuntu16.04版本: 2. 安装好Ubunt ...
- ssm框架的整合
首先创建一个web工程,我这里使用的IDE为eclipse. 结果目录如下: 添加相关的jar包: 接下来是完成配置文件 首先我们先配置web.xml: <?xml version=" ...
- Fastify 系列教程三 (验证、序列化和生命周期)
Fastify 系列教程: Fastify 系列教程一 (路由和日志) Fastify 系列教程二 (中间件.钩子函数和装饰器) Fastify 系列教程三 (验证.序列化和生命周期) 验证 Fast ...
- sql的基本知识
一.什么是sql? 全称:"结构化查询语言(Structured Query Language)",是1974年由Boyce和Chamberlin提出来的,现已经成为关系数据库的 ...