hadoop_并行写操作思路_2
如果想实现将 Client端的 File并行写入到 各个Datanode中,
首先, 应该修改的是,DistributedFileSystem中的create方法,
在create 内部调用FSNamesystem中的方法的时候,
应该增加向NameNode发送,上传文件的大小所需要的blocks的数目。
然后,调用分配块的相关方法, 在NameNode中 所存放的系统树中添加相关的节点后( INodeFile)
还要为该INodeFile中的blocks 表分配block实体, 且 INodeFile.blocks.lenght = (File)/block
接下来,保留client 与 datanodes 之间的packet 数据传输单位的 方法,不对其进行修改。
文件总共分为 n 份, n份并发写入到 Datanode中的block中。
每一份开启一个线程 ( 线程通过 创建一个DataStreamer实例来创建 )
以DataStreamer 所谓线程的并发单位。
以pipeline中的向一个datanode的block 进行写操作为例,
其过程中有两个线程, 这两个线程分别对应这两个流: output input
input 是用来接收来自上游节点的数据流
output是用来将本节点接收到的写往block中的data 写入到下游 datanode的block中。
下图是实现 并发写的算法图示:
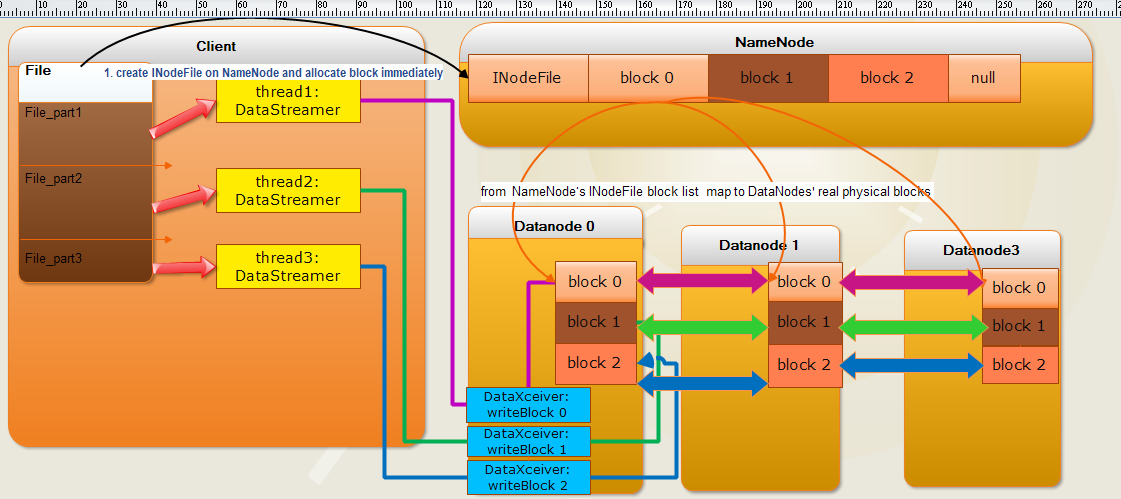
================实现并发写的算法伪代码如下=========================
------------create INodeFile at NameNode for File-------------------- create ( Path fileName, int blockSize ... )
{
INodeFile inodeFile = new INodeFile ( fileName ) ;
//在原始代码中, 在 create 阶段仅仅实例化 一个inodeFile (UnderConstruction)
//并将 该 fileName 对应的 inodeFile 加入到系统目录树中
//但却并未 给 inodeFile.blocks[] 数组中的 block 分配实体 //想要实现的算法是,根据client端发来的blockSize 为文件对应的inodeFile.blocks
//分配块实例 NameNode.FSDirectory.rootDir.addInode ( inodeFile ) ;
//rootDir is a INode list , stores file system's structure for i -> ( 0 , blockSize-1 )
inodeFile.Blocks[i] = FSNamesystem.allocateBlock () ;
} //allocates all the blocks for whole File
//at client we can get the map relationship
//by DistributedFileSystem.NameNode.FSNamesystem.FSDirectory.
//rootDir[rootDir.length-1]
//to get the INodeFile and by INodeFile we can get blocks table
//to write to which block in which datanode
--------------------write to block at client----------------------------
n = sizeof (File) / BlockSize File File_part[n] DataStreamer dataStreamers[n] for i-> ( 0 , n-1 )
{
File_part[i] = File [i*BlockSize, (i+1)*BlockSize-1 ]
} for i-> ( 0, n-1 )
{
dataStreamers[i] = new DataStreamer( File_part[i] , i..)
dataStreamers[i].run ()
} //add a new DataStreamer constructor into src DataStreamer ( File filePart , int number )
{
File f = new File ( filePart ) ;
this.number = number
// add a member variable to remember
//which block in block list should this thread write to
} DataStreamer.run ()
{
(File) f -> packetList [...]
//decompose file into packets //create connection to datanode by socket
//we are going to create a write outputstream //put packet into dataQueue
//get first packet from dataQueue //package the packet into outputstream //and do not forget add the ID (number ) which means which block
//should the packet stream write to //put the current packet to ackQueue
//receive reponse message from datanode
//receive success , remove the packet from ackQueue //shutdown connection } //send packets to datanode on by on
}
大体上的思路是这样的,其中还没有考虑清楚的地方就是,如何才能在并发写的时候,可以将一个文件的写向的多个块的状态
强制转换为 rbw (datanode上的 replica ) 在namenode 上是Underconstruction状态。
因为在前两篇文章中,我们可以知道,在对一个文件进行写操作的时候,只有文件对应的INodeFile的
blocks 的 最后一个block元素 才是可以可以写的,也是出于rbw状态的,那么在并发写的时候,如何保证并发写入的块同时都是出于这个状态
还有就是 提交单位从 最后一个块写完 标志着整个文件的 写完 实现 将会被 改变成 并发写的 所有块都写完才标志着 整个文件的成功提交 ?
这些问题暂时还需要考虑。╮(╯_╰)╭
===========1_8========================
1. 通过FileSystem 创建的实例 create 一个 新的File
2.通过创建一个 FSImage 获得 FSNamesystem , FSDirectory
3.通过 FSNamesystem.dir.rootDir 获得 存放 最新创建 文件的inode, 然后 将INode强制转换为 INodeFile,
通过INodeFile类中的 appendBlocks 一次性 为其分配 指定个数的 blocks。
4.每一个 block 开启一个 对应的OutputStream 的流,通过多线程的调用 向流中写入将 大文件分割好的小文件 。//IOUtils
hadoop_并行写操作思路_2的更多相关文章
- hadoop_并行写操作思路
这篇文章是关于,如何修改hadoop的src以实现在client端上传大文件到HDFS的时候, 为了提高上传的效率实现将文件划分成多个块,将块并行的写入到datanode的各个block中 的初步的想 ...
- HBase并行写机制(mvcc)
HBase在保证高性能的同时,为用户提供了便于理解的一致性数据模型MVCC (Multiversion Concurrency Control),即多版本并发控制技术,把数据库的行锁与行的多个版本结合 ...
- hadoop_集群安装_2
由于上一篇文章http://www.cnblogs.com/inuyasha1027/p/hadoop_cluster_install_1.html 截图太多,占用了太多的地方,所以将VMTools ...
- NAND Flash的基本操作——读、写、擦除
基本操作 这里将会简要介绍一下NAND Flash的基本操作在NAND Flash内部是如何进行的,基本操作包括:读.写和擦除. 读: 当我们读取一个存储单元中的数据时(如图2.4),是使 ...
- 【CPU微架构设计】分布式多端口(4写2读)寄存器堆设计
寄存器堆(Register File)是微处理的关键部件之一.寄存器堆往往具有多个读写端口,其中写端口往往与多个处理单元相对应.传统的方法是使用集中式寄存器堆,即一个集中式寄存器堆匹配N个处理单元.随 ...
- HDFS namenode 写edit log原理以及源码分析
这篇分析一下namenode 写edit log的过程. 关于namenode日志,集群做了如下配置 <property> <name>dfs.nameservices< ...
- 整合Kafka到Spark Streaming——代码示例和挑战
作者Michael G. Noll是瑞士的一位工程师和研究员,效力于Verisign,是Verisign实验室的大规模数据分析基础设施(基础Hadoop)的技术主管.本文,Michael详细的演示了如 ...
- 关于Raid0,Raid1,Raid5,Raid10的总结
RAID0 定义: RAID 0又称为Stripe或Striping,它代表了所有RAID级别中最高的存储性能.RAID 0提高存储性能的原理是把连续的数据分散到多个磁盘上存取,这样,系统有数据请求就 ...
- 从零开始山寨Caffe·柒:KV数据库
你说你会关系数据库?你说你会Hadoop? 忘掉它们吧,我们既不需要网络支持,也不需要复杂关系模式,只要读写够快就行. ——论数据存储的本质 浅析数据库技术 内存数据库——STL的map容器 关 ...
随机推荐
- 【log4js】
手动创建日志目录 定时清理 nodejs之日志管理 玩转Nodejs日志管理log4js access.log-2015-11-20
- nohup.out
nohup.out 文件的产生 linux的nohup命令的用法 不输出nohup.out nohup node app.js > /dev/null 2>&1 &
- Android调试时, "adb devices"命令提示 adb server is out of date. killing...
C:\Users\xxxx>adb devicesadb server is out of date. killing... 查看端口, 发现被占用 C:\Users\xxxx>adb n ...
- Count Color POJ--2777
Count Color Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 32217 Accepted: 9681 Desc ...
- 去掉有序数组中重复数字 原地 leetcode java (最简单的方法)
1.利用荷兰国旗的思路,每次记住最后一个位置,遇到一个不重复的数,放在它后面,代码很简单. Given a sorted array, remove the duplicates in place s ...
- ubuntu12.04编译rtems doc目录
我的rtem的版本是rtems-4.10.2:首先安装textinfo:sudo apt-get install texinfo 然后: cd rtems-4.10.2/doc../bootstrap ...
- 【转】谁说Vim不是IDE?(三)
谁说Vim不是IDE?(三) 常用插件 之所以说Vim形成了自己的生态环境,就是因为Vim具备开放的插件体系,开发者为了提升开发效率,为Vim编写了数以万计的插件,我们可以根据需要任意选择,也可以 ...
- [C#] 常用工具类——文件操作类
/// <para> FilesUpload:工具方法:ASP.NET上传文件的方法</para> /// <para> FileExists:返回文件是否存在&l ...
- JSP http头消息
头 描述 Accept 指定MIME类型 Accept-Charset 编码,例如utf-8 Accept-Encoding 编码方式,例如使用gzip压缩 Accept-Language 语言,例如 ...
- Android-Unable to resolve target 'android-8'