Storm与Hadoop的角色和组件比较
Storm与Hadoop的角色和组件比较
Storm 集群和 Hadoop 集群表面上看很类似。但是 Hadoop 上运行的是 MapReduce 作业,而在 Storm 上运行的是拓扑 Topology,这两者之间是非常不同的。一个关键的区别是:一个MapReduce 作业最终会结束,而一个 Topology 拓扑会永远运行(除非手动杀掉)。表 1-1 列出了 Hadoop 与 Storm 的不同之处。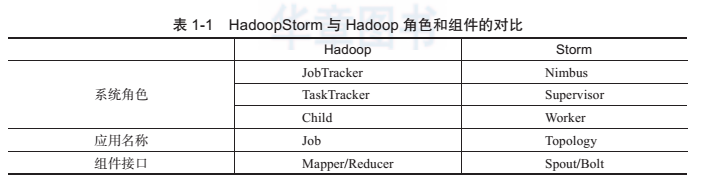
如果只用一个短语来描述 Storm,可能会是这样:分布式实时计算系统。按照 Storm 作者的说法, Storm 对于实时计算的意义类似于 Hadoop 对于批处理的意义。众所周知,根据Google MapReduce 来实现的 Hadoop 提供了 Map 和 Reduce 原语,使批处理程序变得非常简单和优美。那么 Storm 则是在批处理之前,及时处理了数据。
Storm 与其他大数据解决方案的不同之处在处理方式上。Hadoop 在本质上是一个批处理系统。数据被引入 HDFS 并分发到各个节点进行处理。当处理完成时,结果数据返回到HDFS 供始发者使用。 Storm 支持创建拓扑结构来转换没有终点的数据流。不同于 Hadoop 作业,这些转换从不停止,它们会持续处理到达的数据。
Hadoop 专注于批处理。这种模型对许多情形(如为网页建立索引)已经足够,但还存在其他一些使用模型,它们需要来自高度动态来源的实时信息。为了解决该问题,就得借助 Twitter 推出的 Storm。 Storm 不处理静态数据,但它处理预计会连续的流数据。考虑到Twitter 用户每天生成 1.4 亿条推文,很容易看到此技术的巨大用途。
Storm 不只是一个传统的大数据分析系统:它是复杂事件处理(CEP)系统的一个示例。CEP 系统通常分为计算和面向检测两类,其中每个系统都可通过用户定义的算法在 Storm 中实现。例如, CEP 可用于识别事件洪流中有意义的事件,然后实时处理这些事件。
Storm 作者 Nathan Marz 提供了在 Twitter 中使用 Storm 的大量示例。一个最有趣的示例是生成趋势信息。 Twitter 从海量的推文中提取所浮现的趋势,并在本地和国家级别维护这些趋势信息。这意味着当一个案例开始浮现时, Twitter 的趋势主题算法就会实时识别该主题。这种实时算法是使用 Storm 实现的基于 Twitter 数据的一种连续分析。
Storm与Hadoop的角色和组件比较的更多相关文章
- Storm概念学习系列之Storm与Hadoop的角色和组件比较
不多说,直接上干货! Storm与Hadoop的角色和组件比较 Storm 集群和 Hadoop 集群表面上看很类似.但是 Hadoop 上运行的是 MapReduce 作业,而在 Storm 上运行 ...
- 大数据框架hadoop服务角色介绍
翻了一下最近一段时间写的分享,DKHadoop发行版本下载.安装.运行环境部署等相关内容几乎都已经写了一遍了.虽然有的地方可能写的不是很详细,个人理解水平有限还请见谅吧!我记得在写DKHadoop运行 ...
- Storm和Hadoop 区别
Storm - 大数据Big Data实时处理架构 什么是Storm? Storm是:• 快速且可扩展伸缩• 容错• 确保消息能够被处理• 易于设置和操作• 开源的分布式实时计算系统- 最初由Na ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hadoop生态圈-Flume的组件之自定义拦截器(interceptor)
Hadoop生态圈-Flume的组件之自定义拦截器(interceptor) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是举例了一个自定义拦截器的方法,测试字节传输速 ...
- Hadoop生态圈-Flume的组件之自定义Sink
Hadoop生态圈-Flume的组件之自定义Sink 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客主要介绍sink相关的API使用两个小案例,想要了解更多关于API的小技 ...
- Hadoop生态圈-Flume的组件之sink处理器
Hadoop生态圈-Flume的组件之sink处理器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一. 二.
- Hadoop生态圈-Flume的组件之拦截器与选择器
Hadoop生态圈-Flume的组件之拦截器与选择器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Interceptors,想要了解更详细 ...
- Hadoop YARN学习之组件功能简述(3)
Hadoop YARN学习之组件功能简述(3) 1. YARN的三大组件功能简述: ResourceManager(RM)是集群的资源的仲裁者, 它有两部分:一个可插拔的调度器和一个Applicati ...
随机推荐
- Memcached(四)Memcached的CAS协议
1. 什么是CAS协议很多中文的资料都不会告诉大家CAS的全称是什么,不过一定不要把CAS当作中国科学院(China Academy of Sciences)的缩写.Google.com一下,CAS是 ...
- C# 启动进程和杀死进程
/// <summary> /// 杀死进程 /// </summary> private void KillProcesses() { var cfn = GetAppset ...
- 转:Java Annotation详解
转载自:http://william750214.javaeye.com/blog/298104 元数据的作用 如果要对于元数据的作用进行分类,目前还没有明确的定义,不过我们可以根据它所起的作用,大致 ...
- Portlet 通信过程详解
Portlet 通信过程详解 在 Portal 的开发过程中,Theme 与 portlet 之间的通信,以及 portlet 之间的通信是开发人员常常遇到的问题.通常 Portlet 之间需要能够互 ...
- 【转】spring3 MVC实战,手工搭建Spring3项目demo
更新:这几天对spring3的理解又进了一步,今天抽空把这篇文章中的错误和不当之处做了修改. 最近的项目在用Spring3,涉及到了基于注解的MVC,事务管理,与hibernate的整合开发等内容,我 ...
- 什么是 DevSecOps?系列(一)
什么是 DevSecOps? 「DevSecOps」 的作用和意义建立在「每个人都对安全负责」的理念之上,其目标是在不影响安全需求的情况下快速的执行安全决策,将决策传递至拥有最高级别环境信息的人员. ...
- 服务器部署_centos 安装jdk手记
1. 下载jdk略. 2. 将jdk相关文件目录放到指定目录 (1) 创建jdk目录 /usr/java/jdk7 mkdir -p /usr/java/jdk7 (2) 解压缩jdk压缩包,并移动至 ...
- 【HDOJ】1508 Alphacode
简单DP.考虑10.20(出现0只能唯一组合).01(不成立). /* 1508 */ #include <iostream> #include <string> #inclu ...
- WCF - Consuming WCF Service
WCF services allow other applications to access or consume them. A WCF service can be consumed by ma ...
- Error building results for action sayHello in namespace /inteceptor -
原因:不知道如何编译此 struts.xml ,解决方法:导入struts-default文件: <package name="test" namespace=" ...