Memcached 内存管理详解
Memcached是一个高效的分布式内存cache,了解memcached的内存管理机制,便于我们理解memcached,让我们可以针对我们数据特点进行调优,让其更好的为我所用。
首先需要我们先了解两个概念:Slab和chunk。
Slab和chunk在Memcached的内部结构中是非常两个重要的概念,先上一张图来感性认识下:
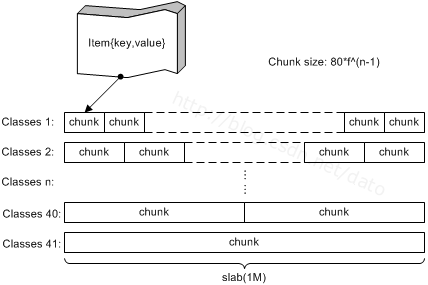
Slab是一个内存块,是Memcached一次申请内存的最小单位。在启动Memcached的时候一般会使用参数-m来指定其可用内存,但并不是在启动哪一刻时所有内存全被分配出去了,而是只有在需要的时候才去申请,每次申请的就是一个Slab。Slab的大小是固定为1M(1048576 Byte)的,而一个Slab是由若干个大小相等的chunk组成,每个chunk中都保存了一个item结构体。
虽然在同一个Slab中的chunk大小相等,但在不同的Slab中chunk的大小不一定相等。因此在Memcached中按照chunk的大小不同,把Slab分成了很多种类(class)。在启动Memcached的时候可以通过-vv来查看Slab的种类:
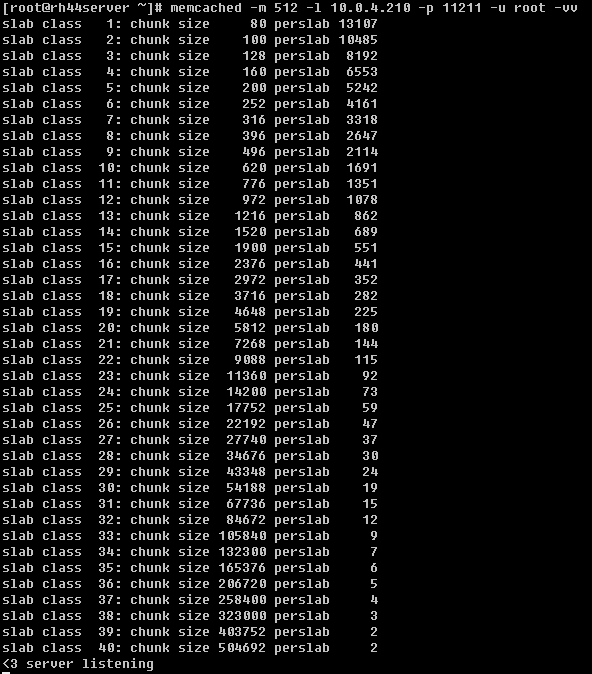
从上图可以看到,默认情况下memcached把slab分为40类(class1~class40):
- 第一列数据(slab class),为slab的编号;
- 第二列数据是chunk的大小,跟slab class是一一对应的关系,可以通俗的理解为slab就是存放一组相同大小chunk的集合,只不过这个集合是固定的(1M),
- 第三列数据,表示每种不同slab中的page可以存放的chunk个数,实际上等于1MB/ (chunk size),例如在class 1中,chunk的大小为80字节,因此在class1中最多可以有13107个chunk:
13107×80 + 16 = 1048576
很显然,slab的chunk size越大,其中的每个page包含的chunk数量就越少。
在class1中,剩余的16字节因为不够一个chunk的大小(80byte),因此会被浪费掉。每类chunk的大小有一定的计算公式的,假定i代表分类,class i的计算公式如下:
chunk size(class i) : (default_size+item_size)*f^(i-1)+ CHUNK_ALIGN_BYTES
- default_size: 默认大小为48字节,也就是memcached默认的key+value的大小为48字节,可以通过-n参数来调节其大小;
- item_size: item结构体的长度,固定为32字节。default_size大小为48字节,item_size为32,因此class1的chunk大小为48+32=80字节;
- f为factor,是chunk变化大小的因素,默认值为1.25,调节f可以影响chunk的步进大小,在启动时可以使用-f来指定;
- CHUNK_ALIGN_BYTES是一个修正值,用来保证chunk的大小是某个值的整数倍(在32位机器上要求chunk的大小是4的整数倍)。
从上面的分析可以看到,我们实际可以调节的参数有-f、-n,在memcached的实际运行中,我们还需要观察我们的数据特征,合理的调节f,n的值,使我们的内存得到充分的利用减少浪费。
内存申请分配
Memcached默认情况下采用了名为Slab Allocator的机制分配、管理内存,Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。
Memcached在重复利用分配的内存时,不会主动删除过期的,而是通过两种策略来实现的:
- Lazy Expiration:就是Memcached不会去监视服务器上的数据是否过期,而是等待get的时候检查时间戳是否过期,如果过期将不返回值,来减少Memcached在监控数据上所用到的时间。
- Least Recently Used(LRU):Memcached 不会去释放已经使用的内存空间,但是如果分配的内存空间已经满了,当此处内存空间数据最长时间没有使用,而且使用次数很少,在存储新的数据的同时就会覆盖此处内存块。
而LRU是针对Slab做的操作,而非全局哦。
下面解释一下memcached的内存预分配过程:
- 向memcached添加一个item时候,memcached首先会根据 item的大小,来选择最合适的slab class:例如item的大小为190字节,默认情况下class 4的chunk大小为160字节显然不合适,class 5的chunk大小为200字节,大于190字节,因此该item将放在class 5中(显然这里会有10字节的浪费是不可避免的)。
- 计算好所要放入的chunk之后,如果这个item对应的slab未出现过,则申请1个page(注意,这1M空间不论是否达到memcached使用内存都可以申请成功)并加该item存入slab中的chunk。
- 如果item对应的slab出现过,则在该slab中优先选择expired(free_chunks)和delete的chunk进行存储,其次将选择未使用过的chunk(free_chunks_end)进行存储。
- 如果item对应的slab出现过,但是对应的slab已经存储满了,那么会申请一个新的page,这个page被分为对应大小的chunk,继续存储。例如我们第一次向memcached中放入一个190字节的item 时,memcached会产生一个slab class 5(也叫一个page),并会用去一个chunk,剩余5241个chunk供下次有适合大小item时使用,当我们用完这所有的5242个chunk之后,下次再有一个在160~200字节之间的item添加进来时,memcached会再次产生一个class 5的slab(这样就存在了2个pages)。
- 如果item对应的slab出现过,但是对应的slab已经存储满了并且memcache也达到了最大内存使用。将使用lru算法,清除item(可能将未过期的item清除)此时会有eviction++。
Page其实就是分配给Slab的内存空间,默认是1MB,Slab是逻辑概念。
Memcached 内存管理详解的更多相关文章
- Apache Spark 内存管理详解(转载)
Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行性能调优.本文旨在梳理出 ...
- 动态内存管理详解:malloc/free/new/delete/brk/mmap
c++ 内存获取和释放 new/delete,new[]/delete[] c 内存获取和释放 malloc/free, calloc/realloc 上述8个函数/操作符是c/c++语言里常用来做动 ...
- spark内存管理详解
Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行性能调优.本文旨在梳理出 ...
- MemCache中的内存管理详解
MC的内存管理机制 1.内存的碎片化 当我们使用C语言或者其他语言进行malloc(申请内存),free(释放内存)等类似的命令操作内存的时候, 在不断的申请和释放的过程中,形成了一些很小的内存片段, ...
- 转:C/C++内存管理详解 堆 栈
http://chenqx.github.io/2014/09/25/Cpp-Memory-Management/ 内存管理是C++最令人切齿痛恨的问题,也是C++最有争议的问题,C++高手从中获得了 ...
- QF——OC内存管理详解
堆的内存管理: 我们所说的内存管理,其实就是堆的内存管理.因为栈的内存会自动回收,堆的内存需要我们手动回收. 栈中一般存储的是基本数据类型变量和指向对象的指针(对象的引用),而真实的对象存储在堆中.因 ...
- Swift 内存管理详解
Swift内存管理: Swift 和 OC 用的都是ARC的内存管理机制,它们通过 ARC 可以很好的管理对象的回收,大部分的时候,程序猿无需关心 Swift 对象的回收. 注意: 只有引用类型变量所 ...
- IOS内存管理详解
一. 基本原理 1. 什么是内存管理 移动设备的内存极其有限,每个app所能占用的内存是有限制的 当app所占用的内存较多时,系统会发出内存警告,这时得回收一些不需要再使用的内存空 ...
- Apache Spark 内存管理详解
在spark里面,内存管理有两块组成,一部分是JVM的堆内内存(on-heap memory),这部分内存是通过spark dirver参数executor-memory以及spark.executo ...
随机推荐
- 如何使用php session
学会php session可以在很多地方使用,比如做一个后台登录的功能,要让程序记住用户的session,其实很简单,看了下面的文章你就明白了. PHP session用法其实很简单它可以把用户提 ...
- Memo 的当前行、当前列与当前字符
procedure TForm1.Memo1Click(Sender: TObject); begin Text := Format('当前列:%d, 当前行:%d', [Memo1.CaretP ...
- phpcms推荐位数据库字段详解
- QT第五天学习
回顾: QFile QTextSream QDataSream QFileInfo QDir Dir entryList 返回目录下所有文件和目录的名字 entryInfoList 返回目录下所有文件 ...
- CentOS7 部署 tomcat
1. 准备tomcat账号 本着最小权限原则,新建账号来安装tomcat. 命令:useradd , passwd 2. 配置防火墙 2.1. tomcat.xml 在/etc/firewalld/s ...
- 在iOS微信浏览器中自动播放HTML5 audio(音乐)的2种正确方式
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Spring util-namespace下标签相关操作
java代码 package com.stono.sprtest; import java.util.List; import java.util.Map; import java.util.Set; ...
- sqlcmd命令导入大容量的SQL本地文件至SQL server 2008
由于开发工作在测试环境,需要构造测试数据,经常遇到100+M大小的*.sql文件需要导入到测试库的情况,由于SSMS里对导入文件的大小有限制: 会出现上图的报错!上网查了下,超过80M的文件是不能在S ...
- viewpager翻页的窗帘效果动画
前端时间比较忙,好长时间没有更新微博,就工作中出现的部分问题,与大家分享一下. 大家都知道viewpager在android开发中是运用率比较高的控件,现在就其窗帘下过的动画分享. 文章出处:http ...
- 性能优化之数据存储&DOM编程
多读书多看报 数据存储 ·在javascript中,数据存储的位置会对代码整体性能产生重大的影响. ·数据存储共有4种方式:字面量.变量.数组.对象成员. ·要理解变量的访问速度,就要理解作用域. ...