Spark算子总结及案例
spark算子大致上可分三大类算子:
1、Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Value型的数据。
2、Key-Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Key-Value型的数据。
3、Action算子,这类算子会触发SparkContext提交作业。
一、Value型Transformation算子
1)map
val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), )
val b = a.map(_.length)
val c = a.zip(b)
c.collect
res0: Array[(String, Int)] = Array((dog,), (salmon,), (salmon,), (rat,), (elephant,))
2)flatMap
val a = sc.parallelize( to , )
a.flatMap( to _).collect
res47: Array[Int] = Array(, , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , ) sc.parallelize(List(, , ), ).flatMap(x => List(x, x, x)).collect
res85: Array[Int] = Array(, , , , , , , , )

3)mapPartiions
val x = sc.parallelize( to , )
x.flatMap(List.fill(scala.util.Random.nextInt())(_)).collect res1: Array[Int] = Array(, , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , )
4)glom(形成一个Array数组)
val a = sc.parallelize( to , )
a.glom.collect
res8: Array[Array[Int]] = Array(Array(, , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , ), Array(, , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , ), Array(, , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , ))
5)union
val a = sc.parallelize( to , )
val b = sc.parallelize( to , )
(a ++ b).collect
res0: Array[Int] = Array(, , , , , )
6)cartesian(笛卡尔操作)
val x = sc.parallelize(List(,,,,))
val y = sc.parallelize(List(,,,,))
x.cartesian(y).collect
res0: Array[(Int, Int)] = Array((,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,), (,))
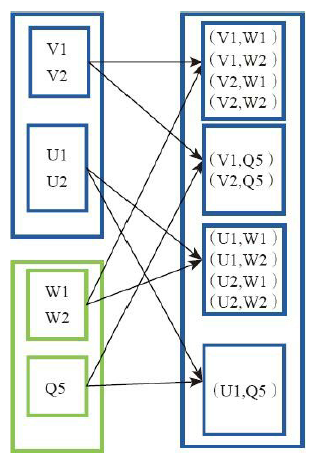
7)groupBy(生成相应的key,相同的放在一起)
val a = sc.parallelize( to , )
a.groupBy(x => { if (x % == ) "even" else "odd" }).collect
res42: Array[(String, Seq[Int])] = Array((even,ArrayBuffer(, , , )), (odd,ArrayBuffer(, , , , )))
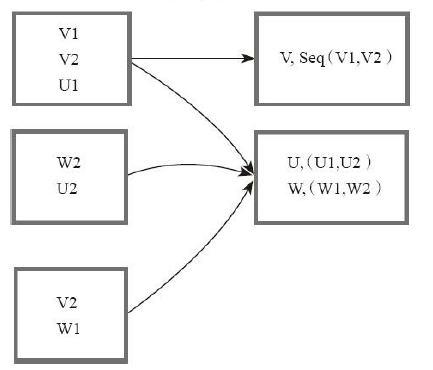
8)filter
val a = sc.parallelize( to , )
val b = a.filter(_ % == )
b.collect
res3: Array[Int] = Array(, , , , )
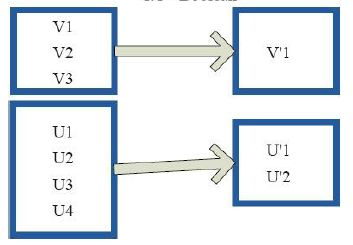
9)distinct(去重)
val c = sc.parallelize(List("Gnu", "Cat", "Rat", "Dog", "Gnu", "Rat"), )
c.distinct.collect
res6: Array[String] = Array(Dog, Gnu, Cat, Rat)
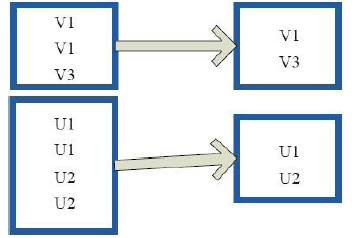
10)subtract(去掉含有重复的项)
val a = sc.parallelize( to , )
val b = sc.parallelize( to , )
val c = a.subtract(b)
c.collect
res3: Array[Int] = Array(, , , , , )
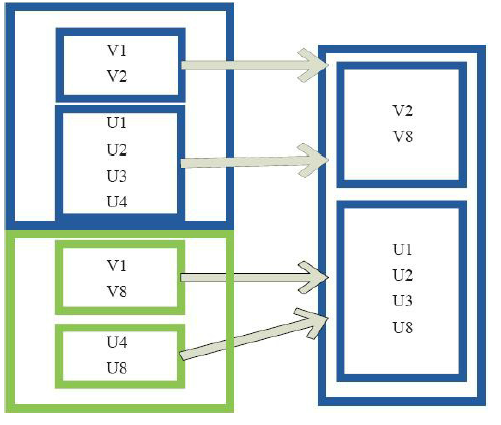
11)sample
val a = sc.parallelize( to , )
a.sample(false, 0.1, ).count
res24: Long =

12)takesample
val x = sc.parallelize( to , )
x.takeSample(true, , )
res3: Array[Int] = Array(, , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , )
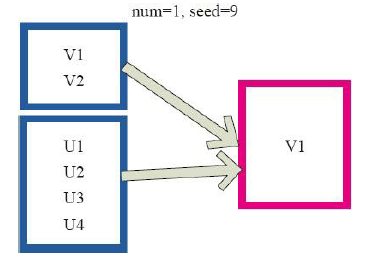
13)cache、persist
val c = sc.parallelize(List("Gnu", "Cat", "Rat", "Dog", "Gnu", "Rat"), )
c.getStorageLevel
res0: org.apache.spark.storage.StorageLevel = StorageLevel(false, false, false, false, )
c.cache
c.getStorageLevel
res2: org.apache.spark.storage.StorageLevel = StorageLevel(false, true, false, true, )
二、Key-Value型Transformation算子
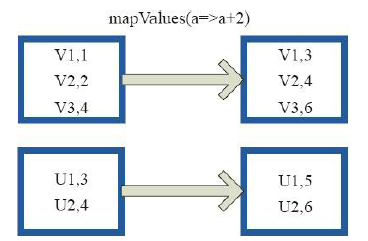
1)mapValues
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), )
val b = a.map(x => (x.length, x))
b.mapValues("x" + _ + "x").collect
res5: Array[(Int, String)] = Array((,xdogx), (,xtigerx), (,xlionx), (,xcatx), (,xpantherx), (,xeaglex))
2)combineByKey
val a = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), )
val b = sc.parallelize(List(,,,,,,,,), )
val c = b.zip(a)
val d = c.combineByKey(List(_), (x:List[String], y:String) => y :: x, (x:List[String], y:List[String]) => x ::: y)
d.collect
res16: Array[(Int, List[String])] = Array((,List(cat, dog, turkey)), (,List(gnu, rabbit, salmon, bee, bear, wolf)))
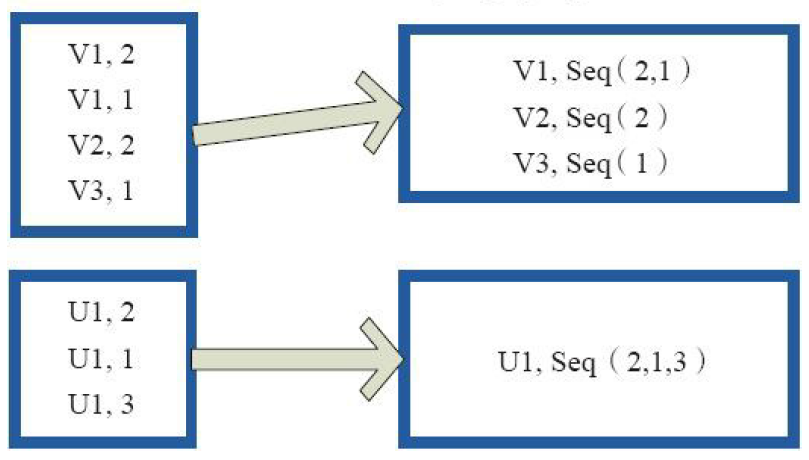
3)reduceByKey
val a = sc.parallelize(List("dog", "cat", "owl", "gnu", "ant"), )
val b = a.map(x => (x.length, x))
b.reduceByKey(_ + _).collect
res86: Array[(Int, String)] = Array((,dogcatowlgnuant))
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), )
val b = a.map(x => (x.length, x))
b.reduceByKey(_ + _).collect
res87: Array[(Int, String)] = Array((,lion), (,dogcat), (,panther), (,tigereagle))
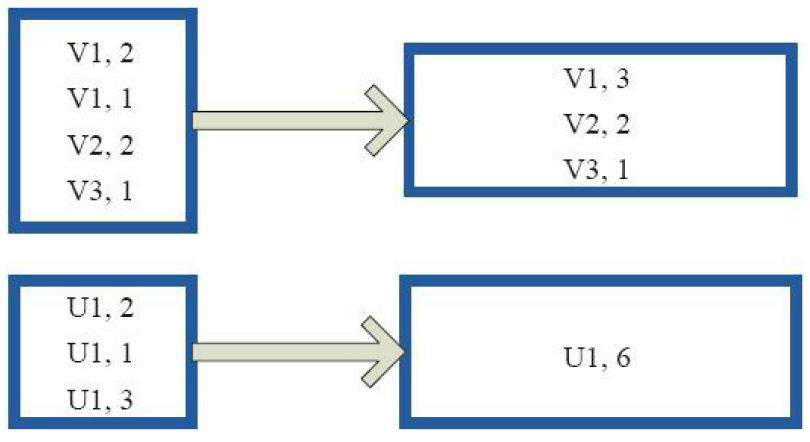
4)partitionBy
(对RDD进行分区操作)
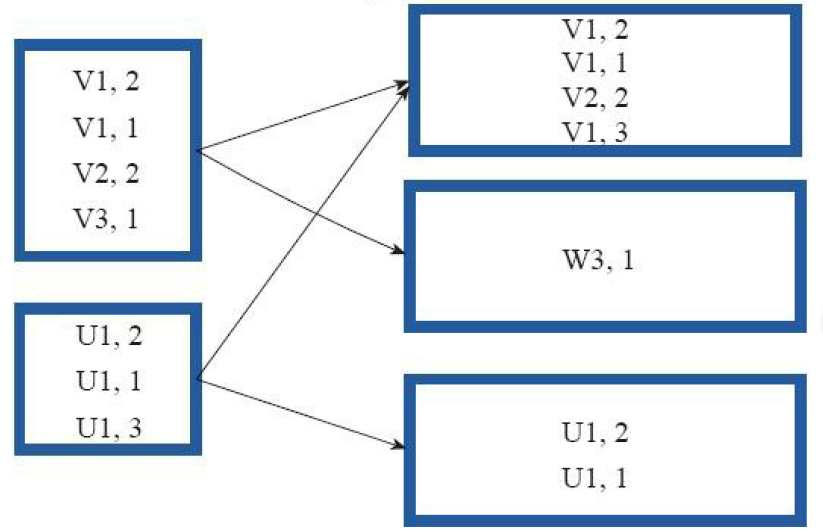
5)cogroup
val a = sc.parallelize(List(, , , ), )
val b = a.map((_, "b"))
val c = a.map((_, "c"))
b.cogroup(c).collect
res7: Array[(Int, (Iterable[String], Iterable[String]))] = Array(
(,(ArrayBuffer(b),ArrayBuffer(c))),
(,(ArrayBuffer(b),ArrayBuffer(c))),
(,(ArrayBuffer(b, b),ArrayBuffer(c, c)))
)
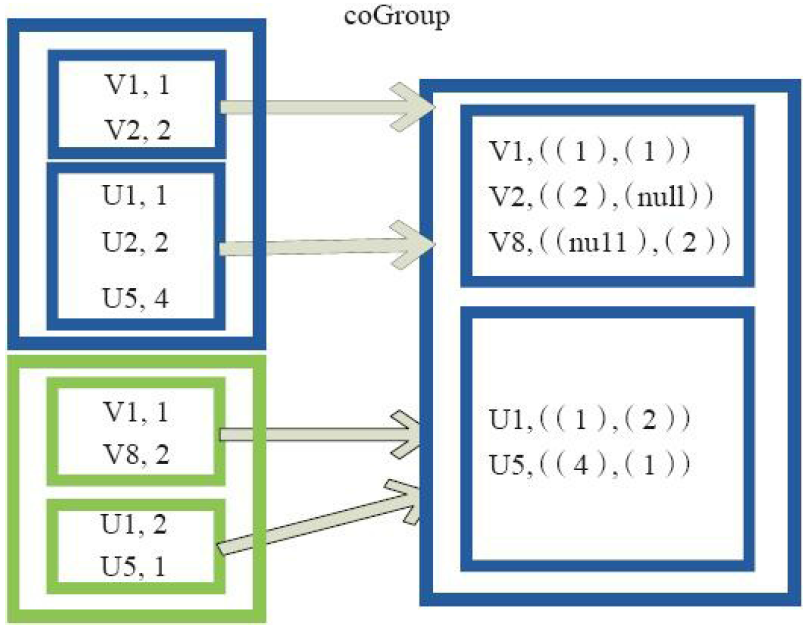
6)join
val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), )
val b = a.keyBy(_.length)
val c = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), )
val d = c.keyBy(_.length)
b.join(d).collect
res0: Array[(Int, (String, String))] = Array((,(salmon,salmon)), (,(salmon,rabbit)), (,(salmon,turkey)), (,(salmon,salmon)), (,(salmon,rabbit)), (,(salmon,turkey)), (,(dog,dog)), (,(dog,cat)), (,(dog,gnu)), (,(dog,bee)), (,(rat,dog)), (,(rat,cat)), (,(rat,gnu)), (,(rat,bee)))
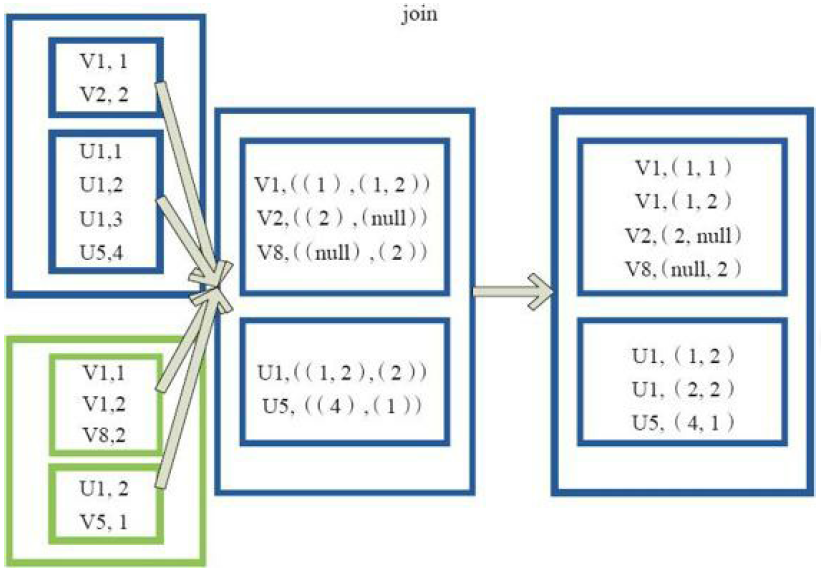
7)leftOutJoin
val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), )
val b = a.keyBy(_.length)
val c = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), )
val d = c.keyBy(_.length)
b.leftOuterJoin(d).collect
res1: Array[(Int, (String, Option[String]))] = Array((,(salmon,Some(salmon))), (,(salmon,Some(rabbit))), (,(salmon,Some(turkey))), (,(salmon,Some(salmon))), (,(salmon,Some(rabbit))), (,(salmon,Some(turkey))), (,(dog,Some(dog))), (,(dog,Some(cat))), (,(dog,Some(gnu))), (,(dog,Some(bee))), (,(rat,Some(dog))), (,(rat,Some(cat))), (,(rat,Some(gnu))), (,(rat,Some(bee))), (,(elephant,None)))
8)rightOutJoin
val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), )
val b = a.keyBy(_.length)
val c = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), )
val d = c.keyBy(_.length)
b.rightOuterJoin(d).collect
res2: Array[(Int, (Option[String], String))] = Array((,(Some(salmon),salmon)), (,(Some(salmon),rabbit)), (,(Some(salmon),turkey)), (,(Some(salmon),salmon)), (,(Some(salmon),rabbit)), (,(Some(salmon),turkey)), (,(Some(dog),dog)), (,(Some(dog),cat)), (,(Some(dog),gnu)), (,(Some(dog),bee)), (,(Some(rat),dog)), (,(Some(rat),cat)), (,(Some(rat),gnu)), (,(Some(rat),bee)), (,(None,wolf)), (,(None,bear)))
三、Actions算子
1)foreach
val c = sc.parallelize(List("cat", "dog", "tiger", "lion", "gnu", "crocodile", "ant", "whale", "dolphin", "spider"), )
c.foreach(x => println(x + "s are yummy"))
lions are yummy
gnus are yummy
crocodiles are yummy
ants are yummy
whales are yummy
dolphins are yummy
spiders are yummy

2)saveAsTextFile
val a = sc.parallelize( to , )
a.saveAsTextFile("mydata_a")
// :: INFO FileOutputCommitter: Saved output of task 'attempt_201404032111_0000_m_000002_71' to file:/home/cloudera/Documents/spark-0.9.-incubating-bin-cdh4/bin/mydata_a
3)saveAsObjectFile
val x = sc.parallelize( to , )
x.saveAsObjectFile("objFile")
val y = sc.objectFile[Int]("objFile")
y.collect
res52: Array[Int] = Array[Int] = Array(, , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , )

4)collect
val c = sc.parallelize(List("Gnu", "Cat", "Rat", "Dog", "Gnu", "Rat"), )
c.collect
res29: Array[String] = Array(Gnu, Cat, Rat, Dog, Gnu, Rat)
5)collectAsMap
val a = sc.parallelize(List(, , , ), )
val b = a.zip(a)
b.collectAsMap
res1: scala.collection.Map[Int,Int] = Map( -> , -> , -> )
6)reduceByKeyLocally
val a = sc.parallelize(List("dog", "cat", "owl", "gnu", "ant"), )
val b = a.map(x => (x.length, x))
b.reduceByKey(_ + _).collect
res86: Array[(Int, String)] = Array((,dogcatowlgnuant))
7)lookup
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), )
val b = a.map(x => (x.length, x))
b.lookup()
res0: Seq[String] = WrappedArray(tiger, eagle)
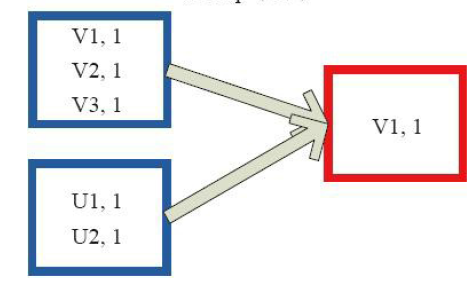
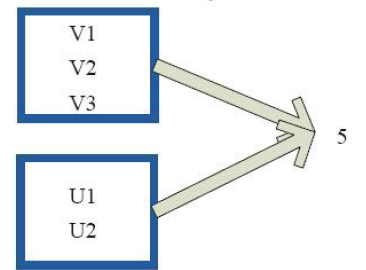
8)count
val c = sc.parallelize(List("Gnu", "Cat", "Rat", "Dog"), )
c.count
res2: Long =
9)top
val c = sc.parallelize(Array(, , , , , ), )
c.top()
res28: Array[Int] = Array(, )
10)reduce
val a = sc.parallelize( to , )
a.reduce(_ + _)
res41: Int =
11)fold
val a = sc.parallelize(List(,,), )
a.fold()(_ + _)
res59: Int =
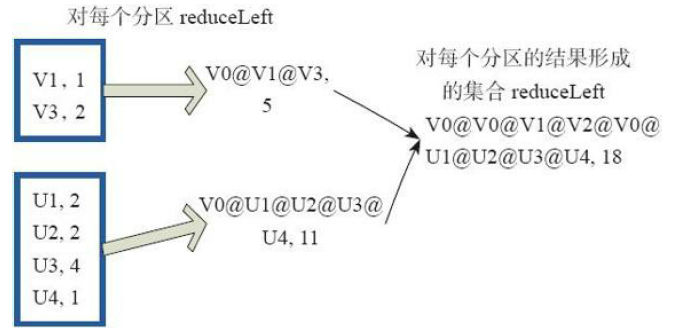
12)aggregate
val z = sc.parallelize(List(,,,,,), ) // lets first print out the contents of the RDD with partition labels
def myfunc(index: Int, iter: Iterator[(Int)]) : Iterator[String] = {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
} z.mapPartitionsWithIndex(myfunc).collect
res28: Array[String] = Array([partID:, val: ], [partID:, val: ], [partID:, val: ], [partID:, val: ], [partID:, val: ], [partID:, val: ]) z.aggregate()(math.max(_, _), _ + _)
res40: Int =
参考:http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html
Spark算子总结及案例的更多相关文章
- Spark算子总结(带案例)
Spark算子总结(带案例) spark算子大致上可分三大类算子: 1.Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Value型的数据. 2.Key ...
- Spark Streaming 进阶与案例实战
Spark Streaming 进阶与案例实战 1.带状态的算子: UpdateStateByKey 2.实战:计算到目前位置累积出现的单词个数写入到MySql中 1.create table CRE ...
- (转)Spark 算子系列文章
http://lxw1234.com/archives/2015/07/363.htm Spark算子:RDD基本转换操作(1)–map.flagMap.distinct Spark算子:RDD创建操 ...
- 《图解Spark:核心技术与案例实战》作者经验谈
1,看您有维护博客,还利用业余时间著书,在技术输出.自我提升以及本职工作的时间利用上您有没有什么心得和大家分享?(也可以包含一些您写书的小故事.)回答:在工作之余能够写博客.著书主要对技术的坚持和热爱 ...
- UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现
UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import ...
- UserView--第一种方式set去重,基于Spark算子的java代码实现
UserView--第一种方式set去重,基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import java.util.Ha ...
- 【原创 Hadoop&Spark 动手实践 6】Spark 编程实例与案例演示
[原创 Hadoop&Spark 动手实践 6]Spark 编程实例与案例演示 Spark 编程实例和简易电影分析系统的编写 目标: 1. 掌握理论:了解Spark编程的理论基础 2. 搭建 ...
- Scala进阶之路-Spark底层通信小案例
Scala进阶之路-Spark底层通信小案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark Master和worker通信过程简介 1>.Worker会向ma ...
- spark算子之DataFrame和DataSet
前言 传统的RDD相对于mapreduce和storm提供了丰富强大的算子.在spark慢慢步入DataFrame到DataSet的今天,在算子的类型基本不变的情况下,这两个数据集提供了更为强大的的功 ...
随机推荐
- Android--->activity界面跳转,以及查看生命周期过程
main.xml界面布局 <?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns ...
- 基于css3的环形动态进度条(原创)
基于css3实现的环形动态加载条,也用到了jquery.当时的想法是通过两个半圆的转动,来实现相应的效果,其实用css3的animation也可以实现这种效果.之所以用jquery是因为通过jquer ...
- h2database. 官方文档
http://www.h2database.com/html/advanced.html http://www.h2database.com/html/tutorial.html#csv http:/ ...
- UWSGI配置文件---ini和xml示例
一 conf.ini文件: [uwsgi] http = $(HOSTNAME):9033 http-keepalive = 1 pythonpath = ../ module = service ...
- hibernate--联合主键--XML
xml:composite-id 要重写equals,hashCode方法, 还要序列化 1. 新建一个主键类: StudentPK.java, 注意需要序列化.还要重写equals和hashCode ...
- ubuntu 系统 opencv3.1.0 安装
opencv编译安装 编译环境安装: sudo apt-get install build-essential 必需包安装: sudo apt-get install cmake git libgtk ...
- Hadoop MapReduce开发最佳实践(上篇)
body{ font-family: "Microsoft YaHei UI","Microsoft YaHei",SimSun,"Segoe UI& ...
- 手机访问pc网站,自动跳转到手机网站
<script type='text/javascript'> var browser = { versions: function () { var u = navigator.user ...
- (中等) POJ 2948 Martian Mining,DP。
Description The NASA Space Center, Houston, is less than 200 miles from San Antonio, Texas (the site ...
- Section 1.1
Your Ride Is Here /* PROG:ride LANG:C++ */ #include <iostream> #include <cstdio> #includ ...