Hadoop学习笔记:使用Mrjob框架编写MapReduce
1.mrjob介绍
一个通过mapreduce编程接口(streamming)扩展出来的Python编程框架。
2.安装方法
pip install mrjob,略。初学,叙述的可能不是很细致,可以加我扣扣:2690382987,一起学习和交流~
3.代码运行方式
下面简介mrjob提供的3种代码运行方式:
1)本地测试,就是直接在本地运行代码;
2)在本地模拟hadoop运行;
3)在hadoop集群上运行。
本地测试:
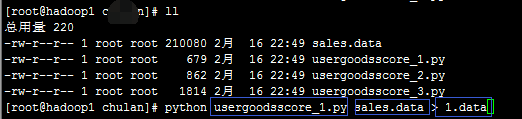
在脚本、数据所在的路径下(如果不在此路径下,就要把路径写完整):
- python usergoodsscore_1.py sales.data > 1.data
第一个蓝框:mr的python脚本所在位置
第二个蓝框:数据所在的位置
第三个蓝框:输出结果存放的位置
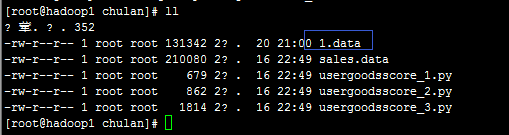
命令执行后在相应的路径下就多了1.data的文件:
在本地模拟hadoop运行:
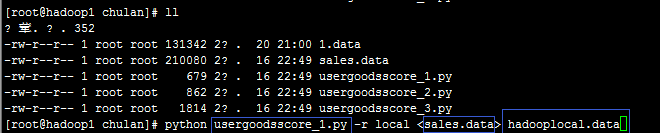
在脚本、数据所在的路径下(如果不在此路径下,就要把路径写完整):
- python usergoodsscore_1.py -r local <sales.data> hadooplocal.data
第一个蓝框:mr的python脚本所在位置
第二个蓝框:数据所在的位置
第三个蓝框:输出结果存放的位置
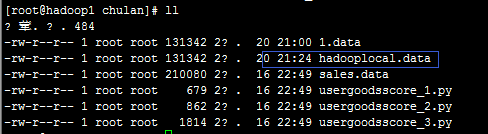
命令执行后在相应的路径下就多了hadooplocal.data的文件:
在hadoop集群上运行:
- python usergoodsscore_1.py sales.data -r hadoop > hadoop1.data

参考资料:
http://www.cnblogs.com/orchid/archive/2013/04/14/3021211.html
http://www.cnblogs.com/joyeecheung/p/3760386.html
http://blog.rainy.im/2016/03/13/python-on-hadoop-mapreduce/
Hadoop学习笔记:使用Mrjob框架编写MapReduce的更多相关文章
- Hadoop:使用Mrjob框架编写MapReduce
Mrjob简介 Mrjob是一个编写MapReduce任务的开源Python框架,它实际上对Hadoop Streaming的命令行进行了封装,因此接粗不到Hadoop的数据流命令行,使我们可以更轻松 ...
- Hadoop学习笔记—18.Sqoop框架学习
一.Sqoop基础:连接关系型数据库与Hadoop的桥梁 1.1 Sqoop的基本概念 Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数据移植过去并不容易.Apache Sqoop正在加 ...
- hadoop学习笔记(九):MapReduce程序的编写
一.MapReduce主要继承两个父类: Map protected void map(KEY key,VALUE value,Context context) throws IOException, ...
- Hadoop学习笔记—15.HBase框架学习(基础知识篇)
HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列的存储模型,它存储的是 ...
- Hadoop学习笔记—15.HBase框架学习(基础实践篇)
一.HBase的安装配置 1.1 伪分布模式安装 伪分布模式安装即在一台计算机上部署HBase的各个角色,HMaster.HRegionServer以及ZooKeeper都在一台计算机上来模拟. 首先 ...
- Hadoop学习笔记—16.Pig框架学习
一.关于Pig:别以为猪不能干活 1.1 Pig的简介 Pig是一个基于Hadoop的大规模数据分析平台,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换 ...
- Hadoop学习笔记—17.Hive框架学习
一.Hive:一个牛逼的数据仓库 1.1 神马是Hive? Hive 是建立在 Hadoop 基础上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储. ...
- hadoop学习笔记(八):MapReduce
一.MapReduce编程模型 一种分布式计算框架,解决海量数据的计算问题. MapReduce将整个并行计算过程抽象到两个函数: Map(映射):对一些独立元素组成的列表的每一个元素进行制定的操作, ...
- Hadoop学习笔记—19.Flume框架学习
START:Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. ...
随机推荐
- mongodb 导入数据库文件
吐槽一下: 这个导入现有数据文件弱爆了... 直接将要导入的数据文件放到mongodb下的db目录下就完事了...O(∩_∩)O哈哈~ 例如: 将shop_suning (shopdb_suning ...
- 编译Uboot时提示error while loading shared libraries: libz.so.1: cannot open shared object file: No such file or directory
在Ubuntu14.04 64位系统中已经安装了libc6:i386的库,编译Uboot时提示error while loading shared libraries: libz.so.1: cann ...
- ECshop中的session机制理解
ECshop中的session机制理解 在网上找了发现都是来之一人之手,也没有用自己的话去解释,这里我就抛砖引玉,发表一下自己的意见,还希望能得到各界人士的指导批评! 此session机制不需 ...
- 子窗口url调整导致父窗口刷新
2014年3月19日 10:22:38 如题: 在弹窗里搜索时,url发生改变,导致父窗口的div消失.为何? 之前的逻辑是隐藏div 现在修改为插入节点 .可是还是刷新字窗口后,父窗口里面的div节 ...
- struts2默认Action配置
在项目中,需要在输入错误的url的时候,弹出友好的错误提示页面 在struts2中可以通过配置默认的action达到这个目的 配置方法: <package name="default& ...
- OC纯代码全手工打造ScroolView实现翻页
OC纯代码全手工打造ScroolView实现翻页 1. 概述 分为三部分: 上部标题ScrollView 下部内容ScrollView 上部当前页 标示线 2. 效果 上下两部分都随着手势的滑动一块滑 ...
- WebStorm界面出现中文乱码(出现口口口)
不少刚刚使用WebStorm软件的童鞋,发现在新建一个项目时,如果输入中文,会显示成口口口.这个问题要怎么解决呢... 点一下界面上那个扳手图标(settings),快捷键Ctrl+Alt+S. 2 ...
- AFNetWorking 之 网络请求的基本知识
NSString *urlStr = @"http://api.openweathermap.org/data/2.5/forecast/daily"; AFHTTPRequest ...
- --@ui-router--登录页通过路由跳转到内页的demo
今天还是来说一下angular中的路由模块.我们实际项目中,各个页面的切换是经常会与Auth相关的.比如我网站的后台,是需要登录过的用户才能进去,那么我们用angularJS做前端路由的时候应该怎么完 ...
- #最小生成树# #kruskal# ----- OpenJudge丛林中的路
最小生成树 一个有 n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有 n 个结点,并且有保持图连通的最少的边.最小生成树可以用kruskal(克鲁斯卡尔)算法或prim(普里姆)算法 ...