MySQL慢日志优化
慢日志的性能问题
- 造成 I/O 和 CPU 资源消耗:慢日志通常会扫描大量非目的的数据,自然就会造成 I/O 和 CPU 的资源消耗,影响到其他业务的正常使用,有可能因为单个慢 SQL 就能拖慢整个数据库的性能,而且这种慢 SQL,在实际业务场景下,通常都是程序发起数个 SQL 请求,通过 SHOW PROCESSLIST 命令可以捕捉到同时有 N 个类似的 SQL 请求在执行。
- 锁等待消耗:由于慢 SQL(select 查询)会阻塞 MDL 锁的获取,所以针对 XtraBackup 全量备份和针对表的 DDL 操作都有可能被阻塞,一旦 DDL 被阻塞,针对表的请求就会变成串行阻塞,后续业务也就无法执行。
- 锁申请消耗:对于非 select 查询的慢事务, SQL 还会把持锁不释放,让后续事务无法申请到锁,造成等待失败,对业务本身来讲是不可以接受的。
怎么收集慢日志?
ELK 体系分析慢日志
- MySQL 开启慢日志——>文件记录慢日志
- ELK 环境搭建
- MySQL 服务器安装 Filebeat 并进行 mysql-slow.log 过滤处理配置
- ELK-WEB 进行维度查看
Percona 分析慢日志
Percona 的 pt-query-digest 是一款可以针对 MySQL 慢日志进行定制化分析的工具
- MySQL 开启慢日志——>文件记录慢日志
- Percona 组件安装并编写 pt-query-digest 定时脚本
- 远程数据库进行定期删除保留
- 远程数据库提供 Web API 接口查询展示
你需要了解的优化基础
优化慢日志的思路是“收集——分析——优化——预防”
优化 SQL 的基础手段是 EXPLAIN,我们要在此基础上,针对 SQL 语句定点优化消除。
EXPLAIN 基本语法是 EXPLAIN + SQL,我们需要针对 EXPLAIN 进行解读:
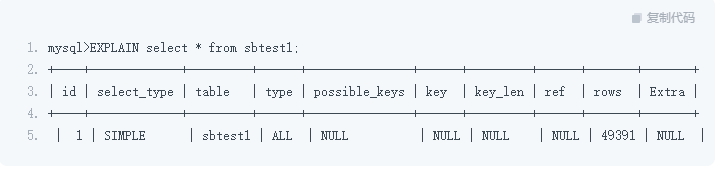
select_type:查询的模式
type:扫描的方式,ALL(全表扫描);SIMPLE(简单查询);RANGE(范围查询)……
table:选择的目标
possible_keys:可能用到的索引(优化器可能选择的索引项)
key:实际用到的索引(要注意,如果 key 为 NULL 或者并不是你所期望看到的索引项,就需要进行处理)
key_len:索引长度(需要关注),实际用到的索引长度,此项针对联合索引,因为存在并没有全部应用联合索引的情况,通过索引长度和联合索引的定义长度进行对比
rows:扫描的行数(需要关注),理论上扫描得越多,性能消耗就越大(注意,并不是实际的数据行数而是目标的数据)
extra:额外的信息(需要关注)Using temporary (采用临时表);Using filesort (采用文件排序);Using index(采用覆盖索引);Using join buffer (Block Nested Loop) BNL 优化,出现此项则代表多表 JOIN 连接没有走索引
SQL 具体的优化思路
添加索引优化慢日志
在索引添加时,你需要注意以下几点情况:
避免索引字段使用函数,尽量在程序端完成计算;
避免发生隐式转换,这要注意条件查询的类型区别,比如字符串类型需要加引号;
order by 字段需要走索引,否则会发生 filesort;
当全表扫描成本低于使用索引成本,需要重新选择区分度大的条件选项;
由于元数据不准确造成优化器选择失误,需要手动进行元数据收集统计;
联合索引的使用顺序基于索引字段的建立顺序。
除此之外,针对多表联查的 SQL 我也提供给你几点建议:
多表联查的语句一定要在连接字段添加索引,这非常重要;
永远是小表驱动大表,合理地选择你的驱动表。
要知道优化的目标是尽可能减少 JOIN 中 Nested Loop 的循环次数,从而保证“永远用小结果集驱动大结果集(这一点很重要)”。A JOIN B,其中,A为驱动,A 中每一行和 B 进行循环JOIN,看是否满足条件,所以当 A 为小结果集时,越快,那么:
尽量不要嵌套太多的 JOIN 语句,连表的数量越多,性能消耗越大,业务复杂性也会越高,MySQL 不是 Oracle,这一点需要你切记;
多表联查的不同表如果字符集不一致,会导致连接字段索引失效。
最后,索引添加你也需要注意这样两点:
建议用 pt-osc、gh-ost 等工具进行添加索引,这样能够在执行 DDL 语句时不会阻塞表;
要在业务低峰期进行操作,尽量避免影响业务。
通过拆分冷热数据优化慢日志
你可能对“通过拆分冷热数据优化慢日志的方案”感到陌生,但实际来说,这个方案非常实用,尤其适合“超大表暂时无法添加有效索引的情况”,超大表是因为历史数据不断插入形成的,后面业务需要查询某些特定条件,而这些特定条件区分度又比较低,即便添加索引效率也 不会提升太大。
比如 A 系统只需要近一年的数据,但是这个扫描条件没办法添加合适的索引,所以将之前的数据进行归档,在某些特定的条件下,能有效地减少扫描行数,大大加快 SQL 语句的执行时间。
拆分冷热数据,针对特定场景的慢日志是有效果的,也有利于数据管理,根据我的经验,可以设立定时任务,按照每天/每周/每月的频率,指定业务低峰时期执行数据归档,执行完成后邮件/微信通知即可。
MySQL慢日志优化的更多相关文章
- MySQL binlog日志优化
mysql中日志类型有慢查询日志,二进制日志,错误日志,默认情况下,系统只打开错误日志,因为开启日志会产生较大的IO性能消耗. 一般情况下,生成系统中很少打开二进制日志(bin log),bin ...
- mysql binlog日志优化及思路
在数据库安装完毕,对于binlog日志参数设置,有一些参数的调整,来满足业务需求或使性能最大化.Mysql日志主要对io性能产生影响,本次主要关注binlog 日志. 查一下二进制日志相关的参数 ...
- MySQL慢日志功能分析及优化增强
本文由 网易云发布. MySQL慢日志(slow log)是MySQL DBA及其他开发.运维人员需经常关注的一类信息.使用慢日志可找出执行时间较长或未走索引等SQL语句,为进行系统调优提供依据.本 ...
- MySQL慢日志线上问题分析及功能优化
本文来源于数据库内核专栏. MySQL慢日志(slow log)是MySQL DBA及其他开发.运维人员需经常关注的一类信息.使用慢日志可找出执行时间较长或未走索引等SQL语句,为进行系统调优提供依据 ...
- MYSQL数据库的优化
我们究竟应该如何对MySQL数据库进行优化?下面我就从MySQL对硬件的选择.MySQL的安装.my.cnf的优化.MySQL如何进行架构设计及数据切分等方面来说明这个问题. 服务器物理硬件的优化 在 ...
- MySQL 调优/优化的 100 个建议
MySQL 调优/优化的 100 个建议 MySQL是一个强大的开源数据库.随着MySQL上的应用越来越多,MySQL逐渐遇到了瓶颈.这里提供 101 条优化 MySQL 的建议.有些技巧适合特定 ...
- Linux下jvm、tomcat、mysql、log4j优化配置笔记
小菜一直对操作系统心存畏惧,以前也很少接触,这次创业购买了Linux云主机,由于木有人帮忙,只能自己动手优化服务器了.... 小菜的云主机配置大致为:centeos6(32位),4核心cpu,4G内存 ...
- [转]MySQL数据库的优化-运维架构师必会高薪技能,笔者近六年来一线城市工作实战经验
本文转自:http://liangweilinux.blog.51cto.com/8340258/1728131 年,嘿,废话不多说,下面开启MySQL优化之旅! 我们究竟应该如何对MySQL数据库进 ...
- mysql数据库性能优化(包括SQL,表结构,索引,缓存)
优化目标减少 IO 次数IO永远是数据库最容易瓶颈的地方,这是由数据库的职责所决定的,大部分数据库操作中超过90%的时间都是 IO 操作所占用的,减少 IO 次数是 SQL 优化中需要第一优先考虑,当 ...
随机推荐
- 在cmd中使用vim编译器
下载地址:http://www.vim.org/download.php#pc 下载GVIM,配置下path环境变量就可以在cmd中使用vim了 把vim.exe复制一份,更名为vi.exe,就可以直 ...
- [loj3284]Exercise
对于一个排列$p_{i}$,假设循环长度依次为$x_{1},x_{2},...,x_{m}$,那么所需步数即${\rm lcm}_{i=1}^{m}x_{i}$ 由于是乘积,因此可以枚举素数$p$,并 ...
- 应用SpringAOP及Tlog工具完成日志链路追踪、收集、持久化
一.痛点 目前我司各系统的日志管理比较原始,使用logback打日志到log文件,虽然有服务管理平台,但记录的日志也仅仅是前置机调用后台系统的出入参,当遇到问题时查日志较为麻烦. 登录VPN-打开服务 ...
- 【JavaSE】格式化输出
Java格式化输出 2019-07-06 11:35:55 by冲冲 1. 输出字符串 %s 1 /*** 输出字符串 ***/ 2 // %s表示输出字符串,也就是将后面的字符串替换模式中的%s ...
- CF1036F
考虑这种一堆数字\(gcd = k\) 有经典做法. 考虑设\(f(x)\)为\(gcd\)是\(x\)的倍数的方案数. \(g(x)\)为\(gcd\)刚好为\(x\)的方案数. 则有 \(f(x) ...
- Codeforces 251D - Two Sets(异或方程组)
题面传送门 题意: 你有一个可重集 \(S=\{a_1,a_2,\dots,a_n\}\),你要把它划分成两个可重集 \(S_1,S_2\) 使得 \(S\) 中每个元素都恰好属于 \(S_1\) 与 ...
- Codeforces 1340F - Nastya and CBS(分块+哈希)
Codeforces 题面传送门 & 洛谷题面传送门 首先看到这样的数据范围我们可以考虑分块,具体来说,对于每一块我们记录其中的括号是否能完全消掉,以及对其进行括号相消之后的括号序列(显然是一 ...
- 自然溢出哈希 hack 方法
今天不知道在什么地方看到这个东西,感觉挺有意思的,故作文以记之( 当 \(base\) 为偶数时,随便造一个长度 \(>64\) 的字符串,只要它们后 \(64\) 位相同那么俩字符串的哈希值就 ...
- R语言与医学统计图形-【30】流行病学数据可视化
sjPlot包适用于社会科学.流行病学中调查数据可视化,且能和SPSS数据无缝对接(流行病学问卷调查录入Epidata软件后,都会转成SPSS格式或EXCEL格式保存). 辅助包sjmisc进行数据转 ...
- Excel-电话号码隐藏某几个数为*,起到保护信息作用;
9.电话号码隐藏某几个数为*,起到保护信息作用: 方法一: =SUBSTITUTE(AG2,MID(AG2,4,5),"*****") 解释函数: MID(目标字符串,裁剪起始位置 ...